当时间来到2025年的最后一天,整个科技界都在进行一场深刻的年度复盘。回望这充满变数的365天,人工智能领域经历了前所未有的震荡与突破。从模型架构的迭代到算力竞赛的白热化,从资本的疯狂涌入到质疑声音的此起彼伏,我们似乎站在了一个关键的历史节点。在这个转折点上,OpenAI的掌舵人Sam Altman在年中发布了一篇引发轩然大波的博文《温和的奇点》。他在文中做出了一个惊人的预测:我们已经掌握了构建AGI的核心方法,2026年将会诞生能够产生原创见解的智能系统。更加激进的论点是,Scaling Law远未触及天花板,随着电力生产的自动化,智能的成本最终将趋近于零。

与此同时,NVIDIA的创始人黄仁勋将目光从单纯的「算力崇拜」转向了更为宏大的「AI工厂」概念。他在2025年底的一次重要演讲中指出,AI发展的瓶颈已经不再是人类的想象力,而是实实在在的电力供应。未来的Scaling Law不再仅仅是模型层数和参数量的简单堆叠,而是推理效率需要实现十万量级的飞跃。这种观点的碰撞,折射出行业内对于AI发展路径的深层思考。

然而,并非所有人都对大模型的未来持乐观态度。Meta的前首席科学家Yann LeCun在离职创办新公司之前,依然保持着他的批判立场。他公开表示,大型语言模型本质上就是通往AGI的死胡同,因为它们缺乏真正的世界模型,就像一座没有躯体的空中楼阁。这种截然不同的声音,让我们不得不思考:2026年之后,Scaling Law是否还能继续发挥作用?对于这个困扰业界的问题,一篇来自DeepMind华人研究员的万字长文在社交网络上引发了热烈讨论。

这篇文章的核心观点异常清晰:Scaling Law没有死,算力依然是驱动AI进步的核心动力,AGI的发展才刚刚踏上征程。作者以自己在DeepMind的亲身经历为线索,深入剖析了从2015年至今AI领域发生的剧变,并揭示了推动这一切的根本力量——算力。尽管外界对于Scaling Laws的有效性存在诸多质疑,但历史事实反复证明了一个简单而深刻的道理:随着算力的指数级增长,AI模型不断展现出超越人类预期的能力。

算力的信仰:Scaling Law的持续进化
最近一段时间,业界关注的焦点集中在一个核心问题上:Scaling Law是否已经遇到了无法逾越的障碍?在2024年底,曾经出现过一阵强烈的悲观论调,认为预训练数据的枯竭和边际收益的递减,标志着Scaling Law时代的终结。然而,站在2025年的终点回顾,我们可以负责任地说:Scaling Law不仅没有失效,它正在经历一场深刻的进化,从简单的「暴力堆参数」转向更为精细的「智能密度」提升。

要真正理解Scaling Law的韧性,我们需要从历史的长镜头来观察。研究数据清晰地显示,在过去的十五年间,用于训练AI模型的算力以每年四到五倍的速度持续增长。这种指数级的复合增长模式,在整个人类技术发展史上都是极为罕见的。在DeepMind的内部观察中,模型训练过程中消耗的数学运算量,已经远远超过了可观测宇宙中的恒星数量。这听起来有些夸张,但却是实实在在的技术现实。
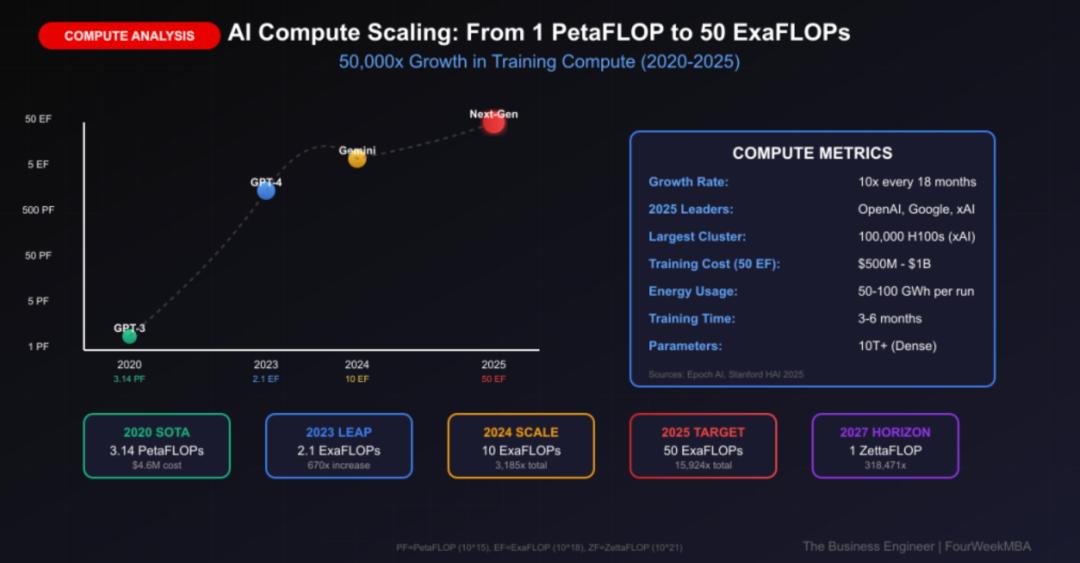
这种增长绝非盲目进行,而是建立在极其稳定的经验公式基础之上。根据Kaplan和Hoffmann等人的实证研究,模型性能与投入算力之间存在着明确的幂律关系:性能提升与算力的0.35次方成正比。这意味着什么呢?每当我们投入10倍的算力,大约能带来3倍的性能增益;而当我们跨越1000倍的算力鸿沟时,性能的提升将达到惊人的10倍量级。这种稳定的关系,为算力投入提供了可预测的回报率。
Scaling Law最迷人的地方在于,它不仅带来了定量的误差减少,更诱发了许多无法预测的定性跃迁。在DeepMind的多次实验中,随着算力的持续增加,模型会突然展现出逻辑推理、复杂指令遵循以及事实性修正等「涌现能力」。这些能力在低算力阶段完全不可见,只有当算力跨越某个临界值时才会突然出现。这种现象说明了一个深刻的道理:算力不仅仅是驱动模型运行的燃料,它本身就是一种能够催生智能的物理量。

进入2025年,我们已经从单一的「预训练Scaling」转向了「四维度Scaling」的新范式。第一个维度依然是预训练Scaling,通过海量多模态数据构建模型的基础认知能力;第二个维度是后训练Scaling,利用强化学习技术进行模型对齐和偏好优化;第三个维度是推理时Scaling,也就是让模型在给出最终回答之前「想得更久」,通过增加推理计算量来提升输出质量;第四个维度是上下文Scaling,通过超长记忆能力提升端到端的任务处理能力。
算力的震撼:千倍扩张的微观启示
如果说Scaling Law是宏观层面的哲学思考,那么2021年在DeepMind发生的一次真实实验,就是微观层面的生动启示。那次经历彻底重塑了许多研究员对于「智能」的理解,也让大家真正明白了为什么说「算力即正义」。当时,DeepMind团队正在尝试解决具身智能在3D虚拟环境中的导航与交互问题,这是一个典型的「硬核AI」挑战。

在那个阶段,业内的普遍共识是:这个问题的瓶颈在于算法的精妙程度,关键在于我们如何设计更优的采样策略和奖励函数。团队投入了大量精力在算法优化上,试图通过人类智慧来突破性能瓶颈。然而,一位同事提出了一个近乎「鲁莽」的方案:不要改动算法,直接把算力投入增加一千倍。在当时看来,这个方案简直是在浪费资源,但实验结果却让所有人震惊。
在那次算力狂飙之后,奇迹真正发生了!那些原本被认为需要突破性人类巧思才能解决的逻辑死角,在海量的矩阵乘法面前直接「融化」了。算法本身并没有变得更聪明,但规模赋予了它一种类似于生物本能的鲁棒性。这种体验让人深刻体会到强化学习教父Richard Sutton在《苦涩