
SWEET-RL:Meta 的新一代多轮强化学习框架深度解析
在人工智能领域,特别是大型语言模型(LLM)的应用中,如何有效地训练模型以执行复杂的协作推理任务一直是研究的重点。Meta 近期推出的 SWEET-RL 框架,正是为了解决这一难题而生。它通过引入多轮强化学习的概念,为 LLM 代理在复杂任务中的训练提供了新的思路。本文将深入探讨 SWEET-RL 的核心功能、技术原理、应用场景以及项目地址,旨在帮助读者全面了解这一前沿技术。
SWEET-RL 的核心功能
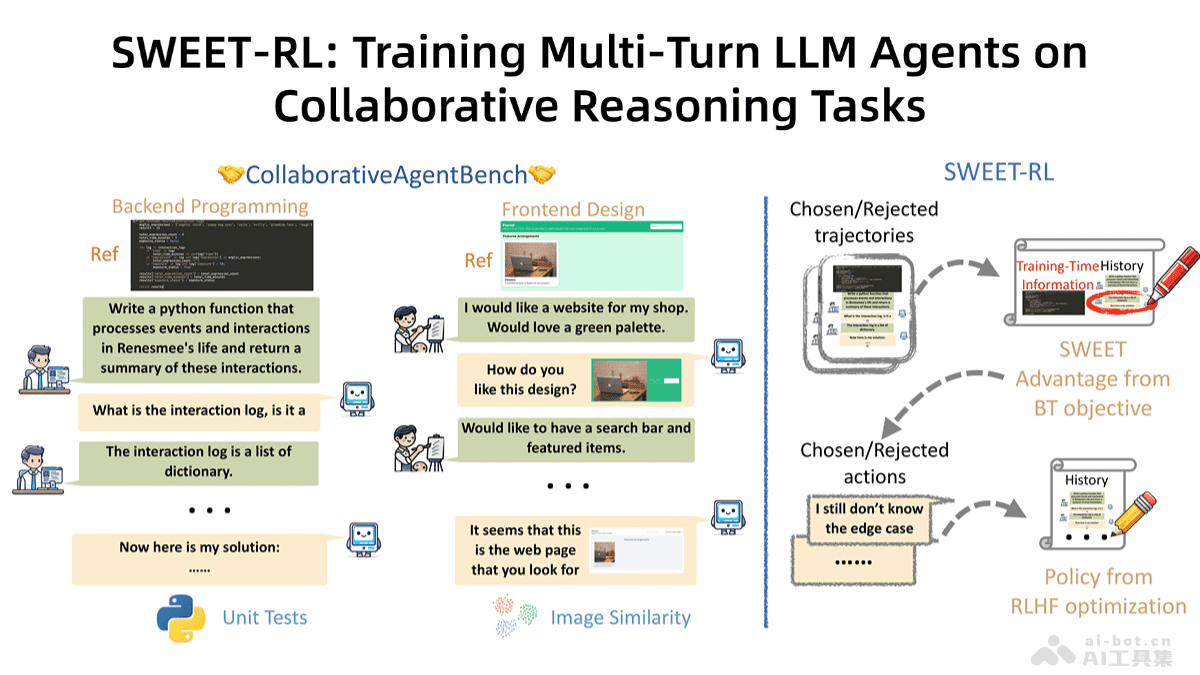
SWEET-RL 框架的核心在于其能够优化多轮交互任务。不同于传统的单轮决策任务,许多实际应用场景,例如后端编程和前端设计,都需要模型进行多轮交互,逐步完善解决方案。SWEET-RL 专门针对这类任务进行了优化,使得 LLM 代理能够更好地理解任务需求,并在多轮交互中不断提升性能。
该框架通过有效分配信用,解决了多轮任务中常见的信用分配问题。在多轮交互过程中,如何准确评估每一步动作的价值至关重要。SWEET-RL 引入了训练时的额外信息,例如参考解决方案,来优化“批评者”模型。该模型能够为每个步骤提供奖励,从而帮助“行动者”模型更好地分配信用,优化策略。
此外,SWEET-RL 还具有良好的通用性和适应性,支持多种任务类型。除了后端编程任务外,该框架还能够处理复杂的前端设计任务,展示了其在不同类型任务中的强大潜力。这意味着 SWEET-RL 不仅仅是一个针对特定任务的解决方案,而是一个通用的强化学习框架,可以广泛应用于各种需要多轮交互的复杂任务。
SWEET-RL 的技术原理
SWEET-RL 的技术原理是其核心竞争力的关键。该框架采用了多种创新技术,以实现高效的多轮强化学习。
首先,SWEET-RL 基于训练时的额外信息来优化“批评者”模型。这些额外信息可以是参考解决方案、专家经验或其他有用的数据。通过利用这些信息,“批评者”模型能够更准确地评估每个动作的价值,为“行动者”模型提供更有效的反馈。这种不对称的信息结构是 SWEET-RL 的一大特点,它使得批评者能够提供更专业的指导,而行动者则专注于优化策略。
其次,SWEET-RL 采用了 Bradley-Terry 目标函数来直接训练优势函数。优势函数用于评估每个动作在当前状态下的有效性。传统的强化学习方法通常需要先训练价值函数,预测当前状态和动作的期望效用,然后再计算优势函数。而 SWEET-RL 直接训练优势函数,避免了中间步骤,更加高效。此外,Bradley-Terry 目标函数与预训练的 LLM 更加对齐,有助于提高模型的性能。
SWEET-RL 采用了不对称的演员-评论家结构。在这种结构中,“批评者”模型可以访问训练时的额外信息,而“行动者”模型只能访问交互历史。这种不对称的设计使得批评者能够更准确地评估动作的价值,而行动者则可以根据评估结果来优化策略。这种结构模仿了人类专家指导学习的过程,能够有效地提高模型的学习效率。
最后,SWEET-RL 将优势函数参数化为每个动作的平均对数概率,并基于轨迹级别的 Bradley-Terry 目标进行训练。这种参数化方式与 LLM 的预训练目标更加一致,有助于提高模型的泛化能力。这意味着模型在训练过程中学到的知识可以更好地应用于新的、未知的任务。
SWEET-RL 的性能表现
SWEET-RL 在 ColBench 基准测试中表现出色,这充分证明了其有效性。ColBench 是一个专门用于评估 LLM 代理在协作推理任务中性能的基准测试。在该测试中,SWEET-RL 相比其他先进算法,在后端编程和前端设计任务上的成功率和胜率提升了 6%。这一提升幅度虽然看似不大,但在竞争激烈的 AI 领域,已经具有显著的优势。
更令人 впечатляюще的是,SWEET-RL 使得 Llama-3.1-8B 模型的性能与 GPT-4o 等顶尖模型相媲美甚至超越。这意味着 SWEET-RL 不仅能够提高模型的性能,还能够降低模型的训练成本。Llama-3.1-8B 是一个相对较小的模型,而 GPT-4o 则是一个非常庞大的模型。通过使用 SWEET-RL,可以使用较小的模型达到甚至超过大型模型的性能,这对于实际应用具有重要意义。
SWEET-RL 的应用场景
SWEET-RL 的应用场景非常广泛,可以应用于各种需要多轮交互的复杂任务。
文本校对是一个典型的应用场景。SWEET-RL 可以帮助作者和编辑快速纠正文章中的错别字和敏感内容。通过多轮交互,模型可以逐步完善校对结果,提高准确率和效率。
社交媒体审核是另一个重要的应用场景。SWEET-RL 可以用于确保社交媒体发布内容合规,保护个人或企业声誉。社交媒体平台每天都会产生大量的内容,人工审核难以覆盖所有内容。SWEET-RL 可以自动审核内容,及时发现并处理违规信息。
广告合规也是一个重要的应用领域。SWEET-RL 可以审核广告文案,避免因内容错误导致的法律和市场风险。广告内容需要符合各种法律法规和行业规范,人工审核容易出错。SWEET-RL 可以自动审核广告内容,确保其合规性。
在学术出版领域,SWEET-RL 可以用于确保教材和学术作品的准确性和严谨性。学术出版物对质量要求非常高,需要经过严格的审核。SWEET-RL 可以辅助审核人员,提高审核效率和质量。
此外,SWEET-RL 还可以应用于多媒体内容检测,审核视频、音频和图片,确保多媒体内容合法合规。随着多媒体内容的普及,对其进行审核变得越来越重要。SWEET-RL 可以自动检测多媒体内容,及时发现并处理违规信息。
SWEET-RL 的项目地址
对于想要深入了解 SWEET-RL 的读者,以下是该项目的相关地址:
- GitHub 仓库:https://github.com/facebookresearch/sweet_rl
- HuggingFace 模型库:https://huggingface.co/datasets/facebook/collaborative_agent_bench
- arXiv 技术论文:https://arxiv.org/pdf/2503.15478
通过访问这些地址,可以获取 SWEET-RL 的源代码、数据集和技术文档,从而更深入地了解该框架的细节。
总结
SWEET-RL 是 Meta 推出的一个强大的多轮强化学习框架,它通过优化多轮交互任务、有效分配信用和支持多种任务类型,为 LLM 代理在复杂任务中的训练提供了新的思路。其技术原理包括训练时的额外信息、Bradley-Terry 目标、不对称信息结构和参数化优势函数。SWEET-RL 在 ColBench 基准测试中表现出色,使得 Llama-3.1-8B 模型的性能与 GPT-4o 等顶尖模型相媲美甚至超越。该框架的应用场景非常广泛,可以应用于文本校对、社交媒体审核、广告合规、学术出版和多媒体内容检测等领域。通过 GitHub 仓库、HuggingFace 模型库和 arXiv 技术论文,可以获取 SWEET-RL 的更多信息。
总而言之,SWEET-RL 是一个值得关注的 AI 技术,它有望在未来推动 LLM 代理在复杂任务中的应用。








