
在人工智能领域,大型模型正以前所未有的速度发展,尤其是在代码生成和修复方面。最近,字节跳动旗下的 Doubao 大型模型团队开源了 Multi-SWE-bench,这是一个多语言代码修复基准数据集,旨在推动大型模型在自动化软件工程领域的智能升级。这一举措不仅为评估和提升大型模型的“自动 Bug 修复”能力提供了重要的工具,也为整个行业带来了新的发展机遇。
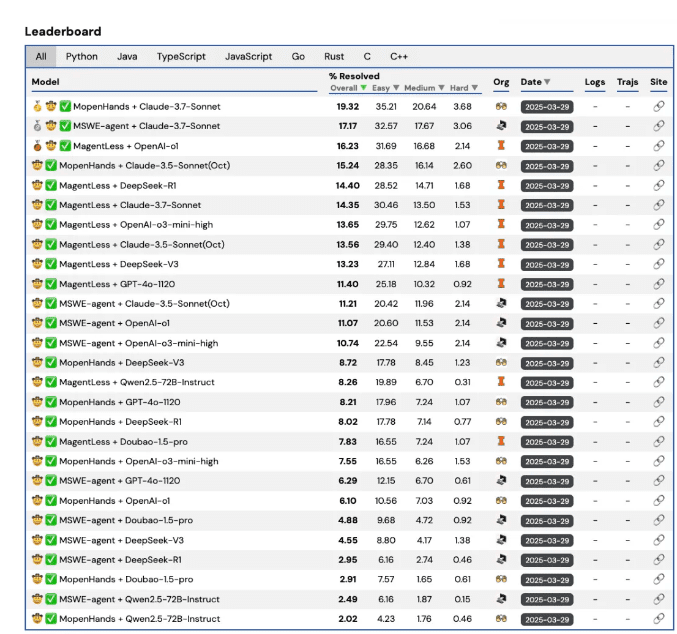
随着大型模型技术的飞速进步,代码生成任务已成为衡量模型智能水平的关键领域。现有的代码修复基准,如 SWE-bench,虽然能够评估模型在编程方面的智能,但其局限性也日益凸显。SWE-bench 主要集中在 Python 语言上,无法全面评估模型在跨语言环境下的泛化能力。此外,其任务难度相对有限,难以充分测试大型模型在复杂开发场景中的表现,这在一定程度上制约了代码智能的进一步发展。
为了克服这些局限性,Multi-SWE-bench 应运而生。它在 SWE-bench 的基础上进行了显著扩展,覆盖了七种主流编程语言:Java、TypeScript、C、C++、Go、Rust 和 JavaScript。该数据集包含了 1632 个来自真实开源代码仓库的修复任务,这些任务经过了严格的筛选和人工验证,以确保其可靠性和高质量。更重要的是,Multi-SWE-bench 引入了难度等级系统(简单、中等、困难),从而能够更全面地评估模型在不同技能水平下的性能表现。
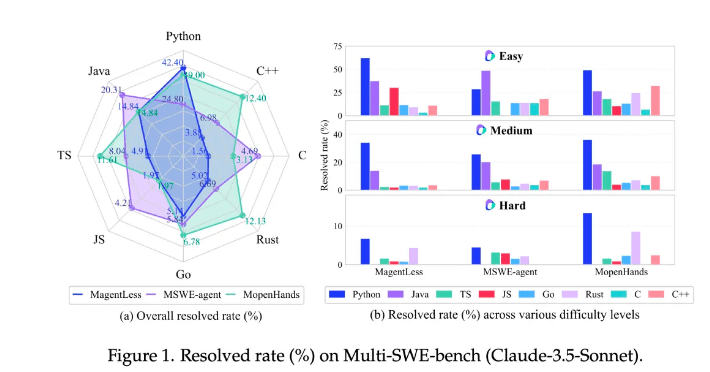
通过 Multi-SWE-bench 进行的实验表明,目前的大型语言模型在 Python 修复任务上表现相对较好,但在其他语言上的平均修复率却低于 10%。这一结果突显了大型模型在多语言代码修复方面所面临的巨大挑战。模型在处理不同难度级别的任务时,其修复率也会出现显著差异。难度越高,修复率越低,这表明模型在处理复杂代码问题时仍有很大的提升空间。
为了进一步支持强化学习在自动编程中的应用,Doubao 团队还开源了 Multi-SWE-RL。该项目提供了 4723 个实例以及相应的可复现 Docker 环境,支持一键启动和自动评估,为强化学习训练提供了一个标准化的数据基础。此外,该团队还发起了一项开源社区倡议,邀请开发者和研究人员参与数据集的扩展、新方法评估等工作,共同推进 RL for Code 生态系统的发展。
Multi-SWE-bench 的技术细节
Multi-SWE-bench 的构建并非一蹴而就,而是经过了精心的设计和严格的实施过程。其核心目标是创建一个能够真实反映实际软件开发场景,并能有效评估大型模型代码修复能力的基准数据集。以下将从数据来源、数据处理、难度分级以及评估指标等方面详细介绍 Multi-SWE-bench 的技术细节。
数据来源
Multi-SWE-bench 的数据主要来源于 GitHub 等主流开源代码托管平台。选择开源代码库作为数据来源,旨在确保数据集的真实性和多样性。团队通过爬虫技术,收集了大量包含 Bug 修复的提交记录。这些提交记录通常包含 Bug 引入的代码片段、修复 Bug 的代码片段以及相关的提交信息。
为了保证数据的质量,团队对收集到的数据进行了严格的筛选。首先,过滤掉那些提交信息不完整或不清晰的记录。其次,排除那些修复过于简单或过于复杂的 Bug。最终,挑选出那些具有代表性、能够有效评估模型修复能力的 Bug 修复案例。
数据处理
收集到的原始数据需要经过一系列的处理,才能转化为可供模型训练和评估的数据集。数据处理的主要步骤包括:
- 代码清洗:去除代码中的注释、空行以及不相关的代码片段,只保留与 Bug 修复相关的核心代码。
- 代码简化:对复杂的代码片段进行简化,使其更易于模型理解和处理。例如,可以将多层嵌套的循环结构简化为单层循环。
- 代码对齐:将 Bug 引入的代码片段和修复 Bug 的代码片段进行对齐,确保它们在语义上是对应的。这有助于模型学习 Bug 的模式和修复方法。
- 生成测试用例:为了能够自动评估模型的修复效果,需要为每个 Bug 修复案例生成相应的测试用例。测试用例应该能够覆盖 Bug 引入的代码片段,并且在修复后的代码上能够正常运行。
难度分级
Multi-SWE-bench 引入了难度分级系统,将 Bug 修复任务分为简单、中等和困难三个等级。难度分级的依据主要包括以下几个方面:
- 代码复杂度:Bug 引入的代码片段的复杂度越高,任务的难度就越高。代码复杂度可以从代码的行数、控制流的复杂程度以及数据结构的复杂程度等方面进行衡量。
- 修复代码的长度:修复 Bug 所需的代码量越多,任务的难度就越高。修复代码的长度可以反映 Bug 的修复难度。
- 修复所需的知识:修复 Bug 所需的特定领域知识越多,任务的难度就越高。例如,修复一个与操作系统内核相关的 Bug,通常需要具备操作系统内核的知识。
- 修复方案的唯一性:如果一个 Bug 有多种修复方案,并且这些方案之间存在显著差异,那么任务的难度就越高。这要求模型能够从多个可能的方案中选择最优的方案。
难度分级不仅有助于更全面地评估模型在不同技能水平下的性能表现,还可以为模型的训练提供更有针对性的指导。例如,可以先用简单级别的任务训练模型,然后再逐步增加难度,从而提高模型的学习效率。
评估指标
为了客观地评估模型的代码修复能力,Multi-SWE-bench 采用了一系列评估指标。这些指标主要包括:
- 修复率:修复率是指模型成功修复的 Bug 修复案例占总案例的比例。修复率是衡量模型代码修复能力的最基本指标。
- 精确率:精确率是指模型正确修复的 Bug 修复案例占模型所有修复案例的比例。精确率可以反映模型修复的准确性。
- 召回率:召回率是指模型成功修复的 Bug 修复案例占所有应该被修复的 Bug 修复案例的比例。召回率可以反映模型修复的完整性。
- F1 值:F1 值是精确率和召回率的调和平均值。F1 值可以综合反映模型的修复能力。
- BLEU:BLEU 是一种用于评估机器翻译质量的指标,也可以用于评估代码修复的质量。BLEU 通过比较模型生成的修复代码和人工编写的修复代码之间的相似度来评估修复的质量。
除了以上这些常用的评估指标外,还可以根据具体的应用场景,自定义一些其他的评估指标。例如,可以评估模型修复后的代码的性能、可读性以及安全性。
Multi-SWE-RL 的设计与应用
Multi-SWE-RL 是一个基于强化学习的代码修复平台,旨在利用强化学习技术提升大型模型在自动编程任务中的性能。该平台的设计充分考虑了强化学习算法的特点以及代码修复任务的特殊性,为研究人员提供了一个便捷、高效的实验环境。
平台架构
Multi-SWE-RL 的平台架构主要包括以下几个组成部分:
- 环境(Environment):环境是强化学习算法与外部世界交互的接口。在 Multi-SWE-RL 中,环境主要负责提供代码修复任务,并根据模型(智能体)的动作给出相应的奖励或惩罚。
- 智能体(Agent):智能体是强化学习算法的核心。在 Multi-SWE-RL 中,智能体通常是一个大型语言模型,它负责接收环境提供的代码修复任务,并生成相应的修复代码。
- 奖励函数(Reward Function):奖励函数是强化学习算法的指挥棒。在 Multi-SWE-RL 中,奖励函数根据模型生成的修复代码的质量,给出相应的奖励或惩罚。奖励函数的设计直接影响着模型的学习效果。
- 训练模块(Training Module):训练模块负责执行强化学习算法,并根据环境的反馈不断优化模型的参数。训练模块通常采用 GPU 加速,以提高训练效率。
- 评估模块(Evaluation Module):评估模块负责评估模型在代码修复任务上的性能。评估模块采用与 Multi-SWE-bench 相同的评估指标,以确保评估结果的客观性。
强化学习算法
Multi-SWE-RL 支持多种强化学习算法,包括:
- 策略梯度算法(Policy Gradient):策略梯度算法是一种直接优化策略的强化学习算法。该算法通过不断调整模型的参数,使得模型能够生成更高质量的修复代码。
- 深度 Q 网络(Deep Q-Network,DQN):DQN 是一种基于值函数的强化学习算法。该算法通过学习一个 Q 函数,来评估每个动作的价值,并选择价值最高的动作。
- Actor-Critic 算法:Actor-Critic 算法是一种结合了策略梯度算法和值函数算法的强化学习算法。该算法同时学习策略和值函数,从而提高学习效率。
应用案例
Multi-SWE-RL 已经被广泛应用于代码修复、代码生成以及代码优化等领域。以下是一些典型的应用案例:
- 代码修复:利用 Multi-SWE-RL 训练的模型,可以自动修复代码中的 Bug。该技术可以大大提高软件开发的效率,并降低软件维护的成本。
- 代码生成:利用 Multi-SWE-RL 训练的模型,可以根据自然语言描述自动生成代码。该技术可以降低编程的门槛,使得非专业人士也能够参与软件开发。
- 代码优化:利用 Multi-SWE-RL 训练的模型,可以自动优化代码的性能。该技术可以提高软件的运行效率,并降低服务器的负载。
字节跳动 Doubao 大型模型团队希望 Multi-SWE-bench 能够推动自动编程技术迈向新的高度。他们计划继续扩展其覆盖范围,以帮助大型模型在“自动化软件工程”领域取得更大的进展。Multi-SWE-bench 的开源,无疑为广大的开发者和研究者提供了一个强大的工具,相信在不久的将来,我们将会看到更多基于 Multi-SWE-bench 的创新成果涌现出来,共同推动人工智能技术在软件工程领域的应用。








