
在人工智能领域,创新如潮水般涌来,每天都有令人瞩目的进展。本文将深入探讨近期AI领域的几大热点,从阿里巴巴的Qwen模型登顶开源榜首,到MiniMax的语音模型创新,再到ChatGPT用户激增,以及更多前沿技术突破,带您全面了解AI的最新动态与未来趋势。
1. 阿里巴巴Qwen2.5-Omni:开源模型的领头羊
最近,Hugging Face发布了最新的大型模型排行榜,阿里巴巴的Qwen2.5-Omni凭借其卓越的性能和强大的多模态能力,成功登顶,成为全球开源模型的领导者。这一成就不仅展示了阿里巴巴在技术研发方面的雄厚实力,也为人工智能技术的普及和应用创造了更有利的条件。Qwen2.5-Omni模型的成功,无疑为整个开源社区注入了新的活力。
Qwen2.5-Omni的突出之处在于其对多模态信息的处理能力,能够同时理解和生成文本、图像、音频等多种类型的数据。这意味着AI系统可以更好地理解真实世界的复杂场景,从而在各种应用中实现更自然、更智能的交互。例如,在智能客服领域,Qwen2.5-Omni可以根据用户提供的图片或语音信息,更准确地理解用户的问题,并给出更个性化的解答。
此外,阿里巴巴开源了超过200个模型,涵盖了自然语言处理、计算机视觉、语音识别等多个领域。这种开放的姿态,无疑将加速AI技术的创新和应用,让更多的开发者和企业能够从中受益。开源不仅降低了AI技术的门槛,也促进了技术的交流和共享,从而推动整个行业的发展。
2. MiniMax Speech-02:语音模型的革新
MiniMax Audio近期推出了全新的Speech-02系列语音模型,该模型支持超过30种语言,并且能够一次性处理高达20万字的输入。新模型在语音合成方面实现了高达99%的真人相似度,有效解决了音频播放中的节奏不流畅问题,确保用户获得流畅的聆听体验。此外,全新的“朗读任意内容”功能和“长文本模式”使得用户能够更轻松地访问和处理长篇文本内容,极大地提升了用户体验。
“朗读任意内容”功能允许用户上传文件或粘贴URL,随时随地聆听各种内容。这一功能对于信息获取和知识学习具有重要意义。例如,学生可以通过上传课件或论文,随时随地进行学习;商务人士可以通过上传报告或新闻,随时了解行业动态。
“长文本模式”支持单次输入20万字,使得处理长篇文本变得轻而易举。这对于制作有声书和播客等内容非常理想。内容创作者可以利用这一功能,将长篇小说、新闻报道、博客文章等转化为高质量的音频内容,从而扩大其内容的受众范围。
3. ChatGPT用户激增:付费模式的成功
OpenAI的ChatGPT在短短三个月内,付费用户数量激增至2000万以上,年度经常性收入增长了近30%,这充分表明市场对这一AI工具的强劲需求。尽管付费用户比例略有下降,但每周活跃用户已达到5亿。为了支持不断增长的用户群,OpenAI计划筹集400亿美元的资金,尽管该公司目前仍在亏损,预计还需要五年才能实现盈利。

ChatGPT的成功,离不开其强大的自然语言处理能力和广泛的应用场景。从智能客服到内容创作,ChatGPT都能提供高效、智能的解决方案。其付费模式的成功,也为其他AI公司提供了借鉴。通过提供高质量的服务和差异化的功能,AI公司可以吸引更多的付费用户,从而实现可持续发展。
然而,随着Gemini、Claude和Grok等竞争对手的迅速崛起,市场竞争日益激烈。OpenAI需要不断创新,才能保持其领先地位。例如,OpenAI可以进一步提升ChatGPT的性能,拓展其应用场景,或者推出更具吸引力的付费计划。
4. ElevenLabs “Text To Bark”:AI与宠物沟通的新尝试
ElevenLabs推出了“Text To Bark”,这是世界上首个专门为狗狗设计的AI文本转语音模型。这项技术可以将人类输入的文本转化为高度逼真的狗叫声,据称有95%的狗狗无法分辨声音的来源。这一创新为人类与宠物之间的交流提供了新的可能性,尽管狗狗可能仍然无法理解具体的意图。

“Text To Bark”的原理是利用深度学习技术,对大量的狗叫声数据进行分析和建模,从而生成逼真的狗叫声。用户可以选择不同的犬种,并调整叫声的音调和节奏,以适应不同的场景。例如,用户可以选择“金毛”犬种,并调整叫声为“兴奋”的音调,来表达对狗狗的喜爱。
虽然狗狗可能无法完全理解“Text To Bark”表达的具体含义,但它们可以通过声音的音调和节奏,感受到人类的情绪。这为人类与宠物之间的情感交流提供了新的途径。ElevenLabs计划将这项技术扩展到其他动物,探索多模态互动系统。这意味着未来我们或许可以通过AI技术,与各种动物进行更自然、更有效的交流。
5. 腾讯元宝:多图处理的效率提升
腾讯元宝近期进行了一次重要的功能升级,特别是在图像识别能力方面得到了显著提升。用户现在可以一次性上传多达10张图片,通过混元或DeepSeek模型实现无缝的图像识别和理解。这一功能在实际应用中非常实用,可以帮助用户快速提取信息、生成文案,甚至将草图转化为网页演示。

腾讯元宝的多图处理能力,极大地提升了工作效率。例如,在电商领域,用户可以一次性上传多张商品图片,快速生成商品描述和推广文案;在教育领域,用户可以一次性上传多张试题图片,快速提取试题内容和答案;在设计领域,用户可以将手绘草图上传到腾讯元宝,快速生成网页演示。
腾讯元宝还支持多种平台,包括移动端、桌面端和网页版,方便用户在不同场景下使用。这种全面的支持,使得腾讯元宝成为了一款非常实用的AI工具。
6. EasyControl_Ghibli:宫崎骏风格图像的自由生成
EasyControl_Ghibli模型的发布,为用户提供了一个免费的工具,可以轻松生成宫崎骏风格的图像。它打破了传统AI图像生成的限制,让普通用户也能参与到艺术创作中,体验技术带来的乐趣和温暖。尽管该模型仍有改进空间,但其开源性和易用性为教育、娱乐和个人表达开辟了新的可能性,展示了AI技术的潜力和魅力。

EasyControl_Ghibli模型的原理是利用生成对抗网络(GAN)技术,对大量的宫崎骏风格图像进行学习,从而生成新的图像。用户可以通过调整模型的参数,来控制生成的图像的风格和内容。例如,用户可以调整“场景”参数,来生成不同场景的宫崎骏风格图像,如森林、城堡、城市等;用户也可以调整“人物”参数,来生成不同人物的宫崎骏风格图像,如少女、少年、老人等。
EasyControl_Ghibli模型的开源性,使得更多的开发者可以参与到模型的改进和优化中。这无疑将加速模型的发展,使其能够生成更高质量的宫崎骏风格图像。EasyControl_Ghibli模型的易用性,使得普通用户也能轻松参与到艺术创作中,体验AI带来的乐趣。
7. PaddlePaddle 3.0:降低跨芯片适配成本
百度深度学习平台PaddlePaddle近期发布了其下一代框架3.0,标志着深度学习领域的一项重大技术创新。通过引入动态和静态统一的自动并行等五项核心技术创新,该框架显著降低了大型模型的开发和训练成本,提高了性能和适应性。PaddlePaddle 3.0支持多个主流大型模型,并实现了跨芯片的无缝迁移,从而将硬件适配成本降低了80%。

PaddlePaddle 3.0的五项核心技术创新包括:动态和静态统一的自动并行、统一的算子编译优化、统一的内存管理、统一的分布式通信和统一的部署方案。这些创新技术,使得PaddlePaddle 3.0能够更好地支持大型模型的开发和训练,并降低硬件适配成本。
PaddlePaddle 3.0还通过优化DeepSeek-R1单机部署,将吞吐量提高了高达一倍。这使得开发者能够更高效地训练和部署大型模型。PaddlePaddle 3.0支持超过60种主流芯片,实现了跨芯片的无缝迁移,从而将硬件适配成本降低了80%。
8. Krea集成Gemini:聊天界面体验的飞跃
Krea近期与谷歌Gemini进行了深度集成,成功引入了文本到图像生成和图像编辑功能,极大地增强了平台的生成能力和用户体验。此次更新将Krea Chat界面从一个简单的对话工具转变为一个综合性的创作平台,能够快速生成和编辑视觉内容,降低了创作门槛。

Krea与Gemini的集成,使得用户可以通过自然语言描述,快速生成和编辑图像。例如,用户可以输入“生成一张风景优美的海滩图片”,Krea就会自动生成一张符合描述的图像。用户还可以对生成的图像进行编辑,如调整颜色、亮度、对比度等。这种便捷的图像生成和编辑方式,极大地降低了创作门槛。
此次更新预计将缩短创意产业从概念到成品的周期,从而提高团队的创造力。Krea与Gemini的集成,为创意产业带来了新的可能性。
9. 腾讯GeometryCrafter:解锁开放世界视频的几何一致性
腾讯近期推出的GeometryCrafter模型在开放世界视频的几何估计方面取得了重大突破。通过使用扩散先验,它成功实现了对动态视频内容的深度理解和处理。该模型无需额外信息即可提取和生成一致的几何信息,填补了该领域的空白。

GeometryCrafter的原理是利用扩散模型,对大量的视频数据进行学习,从而生成一致的几何信息。该模型可以生成精细且连贯的深度序列和几何结构,无需相机姿态或光流数据,填补了行业空白。
腾讯已选择在Hugging Face上开源该模型代码,以促进AI技术的普及,并允许更多创作者参与到技术探索中。这种开放的姿态,无疑将加速GeometryCrafter模型的发展,使其能够更好地应用于各种场景。
10. Meta MoCha:文本瞬间转化为生动的动画角色
Meta与滑铁卢大学的研究团队共同开发的MoCha AI系统,可以根据文本描述生成全身动画角色,并具有同步的语音和自然的动作。这项技术标志着内容创作效率和表现力的显著提高,在数字助理和虚拟化身等领域显示出巨大的应用潜力。
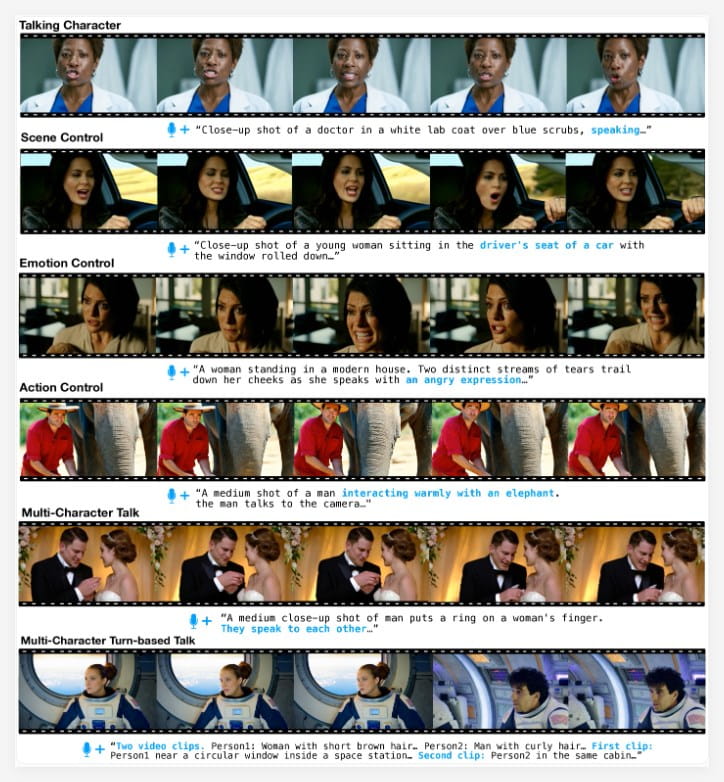
MoCha的原理是利用深度学习技术,对大量的动画角色数据进行学习,从而生成新的动画角色。通过创新的“语音-视频窗口注意力”机制,MoCha实现了更准确的唇音同步,解决了音频和视频生成中的挑战。
MoCha的多角色管理系统简单高效。用户只需定义一次角色信息,即可在不同场景中使用,从而提高创作的便捷性。MoCha的出现,为数字助理和虚拟化身等领域带来了新的可能性。
11. GPT-4.5通过图灵测试:AI会话能力达到新高度
加州大学圣地亚哥分校的研究表明,OpenAI的GPT-4.5首次通过使用“角色扮演”在图灵测试中超越了人类的表现,成为会话能力最像人类的AI系统。该模型在语言流畅性和情感表达方面表现出色,能够灵活地响应评委的情感变化,展示了类似人类的社交智能。这一突破不仅推动了AI技术的发展,也引发了对AI智能标准的深刻讨论。

GPT-4.5以73%的通过率超越了标准图灵测试中的人类表现,成为第一个真正“通过”的AI模型。该模型展示了惊人的语言流畅性和情感丰富性,能够根据评委的语气灵活地调整其反应。
GPT-4.5的成功源于其复杂的角色扮演机制和会话策略,推动了AI技术的应用潜力。GPT-4.5的出现,为AI会话能力的发展树立了新的标杆。
12. OpenAI Academy:免费AI教育资源的推出
OpenAI近期推出了一个新的教育平台OpenAI Academy,旨在向全球用户提供免费且高质量的AI学习资源。该平台涵盖了从基础知识到高级技能的各种课程,适合自学者、教育工作者和开发人员。尽管没有广泛宣传,但此举被认为是OpenAI在促进AI教育普及方面迈出的重要一步,并受到了业内专业人士的广泛欢迎。

OpenAI Academy提供数十小时的免费学习材料,涵盖了人工智能的基础知识和高级技能。该平台面向自学者、教育工作者和开发人员开放,提供灵活多样的课程形式,包括在线和线下活动。
OpenAI Academy的推出标志着该公司在教育和知识传播方面发挥的积极作用,旨在降低AI学习的门槛。OpenAI Academy的出现,为AI教育的普及提供了新的途径。
总而言之,人工智能领域正在以惊人的速度发展,从模型创新到应用拓展,每一项突破都为我们带来了新的可能性。我们有理由相信,在不久的将来,AI将会在更多领域发挥重要作用,为人类社会带来更大的福祉。








