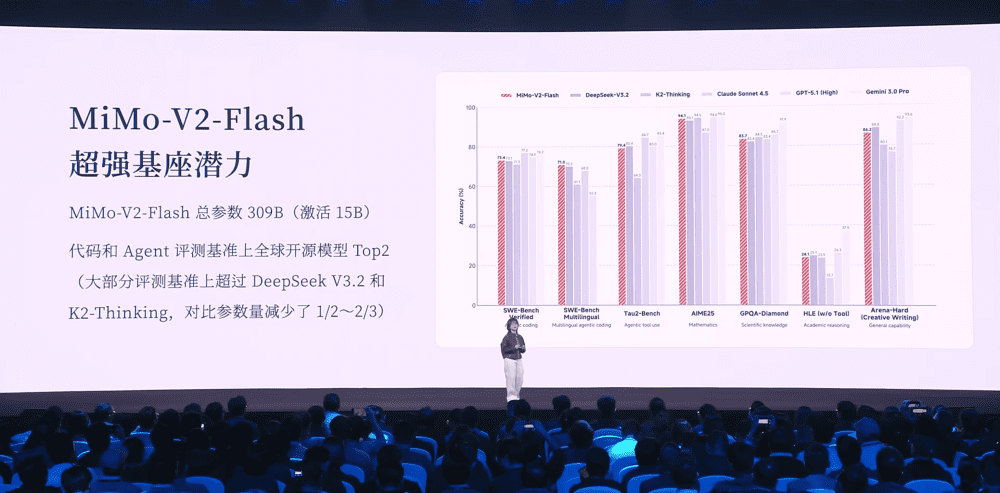
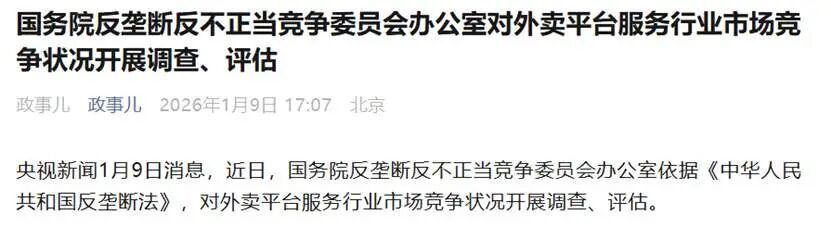
AMD开启AI算力新篇章
在2026年国际消费电子展(CES)的聚光灯下,AMD首席执行官苏姿丰揭开了MI455X GPU的神秘面纱。这款基于CDNA 4架构的加速器,采用台积电3nm制程工艺,单卡FP16算力突破400 TFLOPS,较前代MI300X提升近80%。其创新性在于集成192GB HBM3e内存,通过3D封装技术将内存带宽提升至6TB/s,有效解决了大模型训练中的内存墙瓶颈。

超大规模计算的引擎级方案
MI455X专为云服务商和科研机构设计,单机架可部署16卡配置,提供6.4 PFLOPS的混合精度算力。这种密度设计使数据中心空间利用率提升40%,同时通过液冷散热系统将PUE(电源使用效率)控制在1.15以内。根据AMD实验室数据,在训练1300亿参数模型时,MI455X集群比竞品方案节省27%的电力消耗,这对年电费超千万美元的超算中心具有显著经济价值。
OpenAI合作背后的战略意义
OpenAI总裁格雷格·布罗克曼的站台演讲揭示了更深层产业动态。自2024年签署战略协议以来,OpenAI已在犹他州数据中心部署超过20000片MI400系列芯片,用于GPT-5模型的预训练。此次确认将MI455X纳入下一代算力体系,标志着AMD在关键客户生态的突破。值得注意的是,OpenAI采用混合架构策略——推理层保留NVIDIA方案,训练层全面转向AMD,这种分割部署模式可能成为行业新标准。
企业市场的精准切入
同步发布的MI440X展现出AMD的市场细分策略。该版本保留MI455X 85%的算力性能,但通过PCIe 5.0接口兼容现有服务器,企业无需改造供电和散热系统即可升级。这种设计源于劳伦斯利弗莫尔国家实验室的合作经验,当时AMD为美国能源部超算项目开发了可插拔式加速模块。目前制造业巨头西门子已启动测试,在其工业数字孪生平台中,MI440X将实时流体动力学仿真速度提升11倍。
MI500系列的颠覆性蓝图
苏姿丰在主题演讲中透露的MI500系列引发全场关注。计划2027年问世的该系列采用全新XDNA架构,通过chiplet设计集成1024个AI核心,结合光学互连技术突破数据传输瓶颈。工程样片测试显示,其稀疏计算能力较MI400提升1000倍,特别适合MoE(混合专家)模型训练。这种跃升源于三大创新:
- 存算一体设计:在内存单元嵌入计算电路,减少数据搬运能耗
- 可变精度引擎:动态切换FP8/FP4精度,平衡精度与效率
- 量子隧穿晶体管:实验室阶段技术,有望突破1nm物理极限
重塑AI芯片竞争格局
当前AMD在数据中心加速器市场份额约18%,距离NVIDIA的78%仍有差距。但MI500路线图显示其技术追赶速度:2027年单卡算力密度将达到竞品2.3倍,每瓦性能提升60%。彭博行业研究预测,若MI455X量产如期推进,AMD 2026年AI芯片收入将突破120亿美元,市占率升至25%。
产业变革的深层驱动力
算力民主化进程加速
MI440X的推出实质降低了AI算力使用门槛。传统企业数据中心通常不具备液冷改造条件,MI440X的风冷设计使部署成本降低65%。医疗AI公司Paige的案例显示,在保留原有IBM服务器基础上加装4片MI440X后,病理图像分析效率提升9倍,这种渐进式升级模式可能催生百亿美元级的企业边缘AI市场。
生态构建的战略价值
AMD的开放软件栈ROCm 6.0成为关键胜负手。其新增的自动分布式训练功能,使ResNet-152模型训练代码修改量减少80%。微软Azure的测试表明,在同等硬件配置下,ROCm比CUDA快15%的编译速度。这种软件优势正在吸引更多开发者:2025年Q4,ROCm GitHub仓库星标数同比增长210%。
技术挑战与行业展望
尽管路线图雄心勃勃,AMD仍需解决芯片良率问题。台积电3nm工艺初期良率仅65%,导致MI455X首发价格高达2.8万美元/片。产业分析师认为,2026年下半年产能爬坡后,价格有望降至1.9万美元,这将触发互联网巨头批量采购。
在架构层面,内存子系统仍是瓶颈。即使HBM3e带宽达到6TB/s,仍不能满足万亿参数模型的实时权重更新需求。AMD研究院正在探索存内计算与近内存计算融合方案,预计在MI550系列实现商用。
全球AI算力竞赛已进入新阶段。随着各国主权AI计划推进,到2028年数据中心加速器市场规模将突破2500亿美元。AMD通过MI455X建立市场存在,借MI500实现技术超越的战略路径,正在改写由单一巨头主导的产业规则。当算力效率成为核心指标,开放架构与模块化设计可能成为未来十年的主流范式。