
人工智能(AI)技术日新月异,已渗透到我们生活的方方面面。我们常常惊叹于AI能写诗作画,能流畅对话,但当AI面对视频时,它真的能理解其中的内涵吗?或许你能说,AI已经能够识别视频中的猫狗,甚至人山人海的场景。但识别物体仅仅是第一步,真正理解视频的“灵魂”——摄像机的运动方式,才是更深层次的挑战。
想象一下,希区柯克电影中经典的“滑动变焦”所带来的眩晕感,或是《侏罗纪公园》中镜头缓缓抬起又平移时,初见恐龙的敬畏之情,再或是vlog中跟随主角移动的“跟踪镜头”,这些都是通过镜头运动来叙事和传递情感的经典案例。
然而,对于AI来说,这些微妙的镜头语言在很大程度上仍然是个谜。虽然AI可能能够识别出画面中有人在奔跑,但它很难区分摄像机是在跟随跑动(tracking),还是在原地转动(panning),亦或是像喝醉了一样晃动(unsteady)。要真正理解视频内容,进行3D重建,或者生成更逼真的视频,AI必须掌握理解镜头运动的这项基本功。
一群来自卡内基梅隆大学、马萨诸塞大学、南加州大学等顶尖机构的研究者们,共同推出了一个名为CameraBench的项目,旨在为AI系统地补习这堂“电影摄影课”。

AI理解镜头运动的难点
为什么人类能够轻松理解镜头运动,而AI却面临诸多挑战呢?
首先,参照物不明确是导致理解偏差的重要原因。例如,当无人机进行俯拍时,镜头向前飞行,有人可能描述为“向前”,但也有人会说是“向下”。这种描述上的差异源于参照系的不同,是相对于相机自身,还是相对于地面或画面中的物体?缺乏明确的参照系,AI就难以准确理解镜头的运动轨迹。研究人员指出,人类在描述镜头运动时,通常会将场景或物体纳入考量,例如“相机跟随主体跑动”,即使相机实际上是在倒退。
其次,专业术语的混淆也是一个挑战。即使是资深影迷,也可能难以区分“推拉镜头”(Dolly In/Out)和“变焦”(Zoom In/Out)。推拉镜头涉及相机物理位置的移动,从而改变相机外参;而变焦仅仅是调整镜头内部的镜片,改变焦距,从而改变相机内参。虽然两种技巧在视觉效果上可能相似,但其原理和透视感却截然不同。如果AI模型学习了不准确的术语,可能会导致理解上的偏差。
最后,真实世界的复杂性为AI理解镜头运动带来了额外的困难。真实的视频内容往往充满了各种不规则的运动模式,例如相机可能先向前飞行,然后突然改变方向;或者镜头抖动剧烈;甚至可能同时运用多种运镜技巧。试图用简单的“左移”、“右移”等标签来概括这些复杂的运动,显然是不够的。
面对这些挑战,传统的解决方法显得有些力不从心。
老派几何学方法,例如SfM/SLAM,擅长从画面像素变化推算相机轨迹,在3D重建方面表现出色。然而,在动态场景中,当画面中的人和物体都在运动时,这类方法容易混淆相机运动和物体运动,难以区分“敌我”。此外,它们只关注冷冰冰的坐标数据,无法理解镜头运动的“意图”和“情绪”。
新兴的视频语言模型(VLM),如GPT-4o、Gemini等,在理解语义方面表现出色,似乎能够“看懂”视频。然而,这些模型对于精确的几何运动并不敏感,难以准确判断平移的具体距离或旋转的角度,很大程度上依赖于“猜测”和大规模训练数据中获得的“感觉”。
因此,研究人员认为,有必要系统性地解决AI理解镜头运动的问题。
CameraBench:AI的“镜头语言词典”
CameraBench不仅仅是一个简单的数据库,而是一整套解决方案。其核心包括两个关键组成部分:一个详细的“镜头运动分类法”(Taxonomy)和一个高质量的“标注数据集”。
镜头运动分类法

CameraBench的镜头运动分类法并非凭空捏造,而是视觉研究人员和专业电影摄影师共同合作,历经数月反复推敲和完善的成果。它充分考虑了镜头运动的各个方面:
- **三大参照系:**明确区分了相对于物体(Object)、地面(Ground)和相机自身(Camera)的运动,从而解决了参照物混乱的问题。
- **精准术语:**采用了电影行业的标准术语,避免了歧义。
- 平移(Translation):Dolly(前后)、Pedestal(上下)、Truck(左右)。相机发生实际的物理移动。
- 旋转(Rotation):Pan(左右摇摆)、Tilt(上下点头)、Roll(侧向翻滚)。相机在原地转动。
- 变焦(Zooming):Zoom In/Out。通过改变镜头内部结构,调整焦距。
- **其他运动类型:**包括环绕(Arcing/Orbiting)、各种跟踪镜头(Tracking shots)以及稳定性(Steadiness)。
- **目标导向:**考虑了以物体为中心的运动,例如镜头是否旨在使主体在画面中显得更大或更小。
CameraBench的镜头运动分类法就像一本权威的词典,为镜头运动的描述建立了规范。
高质量标注数据集
有了好的词典,还需要高质量的例句。研究人员从互联网上搜集了约3000个视频片段,涵盖电影、广告、游戏、Vlog、动画、体育赛事等多种类型。然后,他们采用了一套极其严格的标注流程:
- **人工分镜:**首先将视频手动切割成一系列独立的、运镜连续的镜头。
- **“先打标签,再描述”:**对于简单、清晰的运动,标注员必须严格按照分类法,为所有相关的运动都打上标签。对于复杂、模糊的运动,标注员只选择自己非常有把握的标签,其他留空(标为“不确定”),并用自然语言详细描述复杂的运动过程,或者说明看不清的原因。
- **解释运动意图:**鼓励标注员描述运镜的意图,例如“第一人称视角跟随角色走路”、“为了展示风景”、“为了跟踪主体”等。这使得数据不仅包含几何信息,还包含了语义和叙事维度。
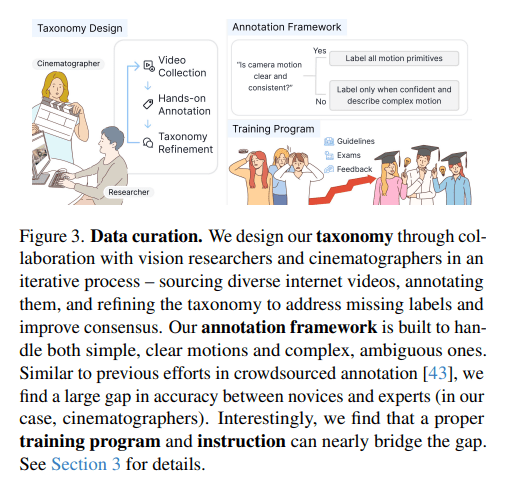
为了保证标注质量,研究人员采取了以下措施:
- **专家把关:**研究发现,有摄影经验的“专家”比“小白”标注准确率高15%以上。
- **培训大法:**为了保证大规模标注的质量,研究人员制定了详细的培训计划,提供图文并茂的指南,并让标注员参加多轮考试。只有通过所有培训(平均耗时20小时)的人员才能上岗。此外,还有随机抽查和反馈机制,以确保数据质量。
通过这套严格的流程,CameraBench获得了高质量的数据集,既包含结构化的标签,又包含丰富的自然语言描述。
CameraBench测试:AI模型的“期末考试”
为了验证CameraBench的有效性,研究人员将市面上主流的AI模型放在CameraBench上进行了测试。测试内容包括运动分类、视频问答(VQA)、视频描述生成、视频文本检索等。
几何学方法的表现
几何学方法(如SfM/SLAM)在处理简单、静态场景时表现尚可。基于学习的方法(如MegaSAM)比传统方法(如COLMAP)在处理动态场景时表现更好。然而,当遇到主体在运动、背景纹理较少的视频时,几何学方法就会失效;对旋转和移动的区分能力较弱;并且完全无法理解语义。总的来说,几何学方法的基本功扎实,但在应用题方面表现不佳。
语言模型的表现
语言模型(VLM)在语义理解方面具有潜力,例如能够大致判断出“相机在跟随人走”。生成式VLM(如GPT-4o)通常比判别式VLM表现更好。然而,几何感知是语言模型的短板,难以精确判断是Pan还是Truck,是Dolly还是Zoom。在VQA测试中,许多模型的表现甚至不如随机猜测。总的来说,语言模型擅长“说漂亮话”,但缺乏对物理世界的精确感知。
语言模型“上课”后的表现
为了提升语言模型的性能,研究人员尝试使用CameraBench的高质量数据对VLM进行微调。他们选择了一个表现不错的生成式VLM(Qwen2.5-VL),并使用CameraBench的部分数据(约1400个视频)进行了监督微调(SFT)。
结果表明,微调后的模型在镜头运动分类任务上的性能提升了1-2倍,整体表现追平了最好的几何方法MegaSAM。在生成任务(描述/VQA)方面,微调后的模型也显著优于之前的模型和其他VLM。生成的镜头描述更加准确、更加细致。VQA任务也表现出色,尤其是在需要理解复杂逻辑和物体中心运动的任务上。
这一结果表明,高质量、带有精确几何和语义标注的数据,对于提升VLM理解视频动态(尤其是镜头运动)至关重要。CameraBench提供的“教材”确实有效。
未来展望
CameraBench项目是让AI理解镜头运动的关键一步。它表明:
- 需要专业的分类法:定义清晰、参照系明确是基础。
- 高质量数据是王道:专家参与、严格的标注流程和培训必不可少。
- 几何和语义要结合:SfM/SLAM和VLM各有优劣,未来需要融合两者之长。
- 微调潜力巨大:即使是小规模的高质量数据微调,也能显著提升现有大模型的能力。
当然,研究仍在继续。未来可能需要更多样、更刁钻的数据,探索更有效的模型训练方法,甚至让AI不仅能识别运镜,还能理解运镜背后的情感和导演意图。
总而言之,CameraBench不仅仅是一个数据集,它更像是一个“AI电影学院”的雏形。它用严谨的方法论、专业的知识和高质量的数据,试图教会AI如何欣赏和理解镜头运动这门充满魅力的“视觉舞蹈”。虽然现在的AI在这方面还像个刚入门的学生,但有了CameraBench这样的“教科书”和“训练场”,相信不久的将来,AI不仅能看懂视频里的猫猫狗狗,更能和你一起讨论:“哇,你看诺兰这个旋转镜头用得多妙!”








