
在人工智能(AI)领域,我们经常听到关于AI在诗歌创作、绘画艺术,甚至日常对话中展现出的卓越能力。然而,当我们深入探讨AI的视频理解能力时,一个关键问题浮出水面:AI真的能够“看懂”视频吗?
当然,AI在物体识别方面已经取得了显著进展,能够识别视频中的猫、狗,甚至人群。但是,理解视频的精髓——摄像机的运动方式——则是一个更为复杂的问题。想象一下,希区柯克电影中经典的“滑动变焦”所带来的眩晕感,或者《侏罗纪公园》中镜头缓缓抬起又平移时所营造的敬畏感。这些运镜技巧都在讲述故事,传递情感。
然而,对于AI来说,这些微妙的动作语言在很大程度上仍然是一个谜。AI可能能够识别出画面中有人在奔跑,但很难准确判断摄像机是在跟随拍摄,还是在原地旋转,或者只是随意晃动。这种理解上的不足限制了AI在视频内容理解、3D重建以及生成逼真视频等方面的应用。
为了解决这个问题,来自卡内基梅隆大学、马萨诸塞大学和南加州大学等顶尖机构的研究人员共同推出了一项名为CameraBench的项目。该项目旨在通过一套全面的方法,提升AI对镜头运动的理解能力。本文将深入剖析CameraBench项目,揭示其背后的原理和方法。

AI为何难以理解镜头运动?
人类天生具备视觉感知能力,能够轻松理解镜头运动。那么,为什么AI在这方面会遇到困难呢?原因主要有以下几点:
- 参照物不明确:例如,无人机在进行航拍时,如果镜头向前飞行,有人可能会描述为“向前”,但也有人会描述为“向下”,因为镜头是朝向地面的。这种参照物的不明确性会导致AI产生混淆。研究人员指出,人类在描述镜头运动时,通常会结合场景或物体,例如“相机跟随主体跑动”,即使相机实际上是在倒退飞行。
- 术语混淆:即使是专业人士,也可能难以区分“推拉镜头”和“变焦”。前者是指相机物理上的移动,改变了相机的位置;而后者只是调整镜头内部的镜片,改变了焦距。虽然两者产生的视觉效果相似,但原理和透视感却截然不同。如果AI模型学习了错误的术语,将会产生严重的问题。
- 真实世界的复杂性:现实世界中的视频拍摄方式千变万化,可能包含各种复杂的镜头运动,例如先向前飞行然后突然掉头,或者镜头抖动非常厉害,甚至多种运镜方式同时进行。使用简单的“左移”、“右移”等标签来概括这些复杂的运动是远远不够的。
面对这些挑战,传统的方法显得力不从心:
- 传统的几何方法(SfM/SLAM):这类方法擅长通过分析画面像素的变化来推算相机的轨迹,非常适合进行3D重建。然而,在动态场景中,例如画面中同时存在人和车辆移动时,这些方法容易混淆相机和物体的运动,无法准确判断相机的运动轨迹。此外,它们只关注坐标等冷冰冰的数据,无法理解运镜的意图和情感。
- 新兴的视频语言模型(VLM):像GPT-4o、Gemini等模型在理解语义方面表现出色,似乎能够“看懂”视频。但是,它们对精确的几何运动并不敏感,例如难以准确判断是平移了1米还是旋转了5度。因此,它们对视频的理解很大程度上依赖于猜测和从大规模训练数据中获得的“感觉”。
鉴于以上问题,研究人员认为有必要系统地解决AI理解镜头运动的问题。
CameraBench:AI的“镜头语言词典”
CameraBench不仅仅是一个数据库,而是一套完整的解决方案。该方案的核心包括两个关键要素:一个详细的“镜头运动分类法”和一个高质量的“标注数据集”。
1. 镜头运动分类法

该分类法并非随意设计,而是由视觉研究人员和专业电影摄影师共同合作,经过数月的反复推敲和完善而成的。它充分考虑了各种因素:
- 三大参照系:明确区分相对于物体、地面和相机自身的运动,从而解决参照物混乱的问题。
- 精确术语:采用电影行业的标准术语,避免歧义。
- 平移(Translation):Dolly(前后)、Pedestal(上下)、Truck(左右),表示相机在物理上的移动。
- 旋转(Rotation):Pan(左右摇摆)、Tilt(上下点头)、Roll(侧向翻滚),表示相机在原地旋转。
- 变焦(Zooming):Zoom In/Out,表示通过改变镜头内部结构来改变焦距。
- 更高级的运动:包括环绕、各种跟踪镜头(跟随式、领跑式、侧跟式、空中跟拍等)以及稳定性(静止、稳定、轻微抖动、剧烈抖动)。
- 目标导向:考虑以物体为中心的运动,例如镜头是否为了使主体在画面中显得更大或更小。
该分类法就像一本权威的词典,为镜头运动的描述建立了规范。
2. 高质量标注数据集
拥有了好的词典,还需要高质量的例句。研究人员从网上收集了约3000个各种各样的视频片段,包括电影、广告、游戏、Vlog、动画、体育赛事等。然后,他们对这些视频片段进行了一套非常严格的标注流程:
- 人工分镜:首先将视频手动分割成一个个独立的、运镜连续的镜头。
- “先打标签,再描述”:
- 对于简单清晰的运动,标注员必须严格按照分类法,为所有相关的运动都打上标签。
- 对于复杂模糊的运动,如果运动非常复杂(例如先左摇再右摇)或者看不清楚(例如背景太暗),标注员只选择自己非常有把握的标签,其他留空(标为“不确定”),并用自然语言写一段描述,解释清楚这个复杂的运动过程,或者说明为什么看不清楚。
- 解释“为什么这么动”:鼓励标注员描述运镜的意图,例如“第一人称视角跟随角色走路”、“为了展示风景”、“为了跟踪主体”等。这使得数据不仅包含了几何信息,还包含了语义和叙事的维度。

为了保证标注的质量,研究人员采取了以下措施:
- 人类研究:研究表明,有摄影经验的“专家”比“小白”的标注准确率高15%以上。
- 培训计划:为了保证大规模标注的质量,研究人员制定了一个详细的培训计划,包括提供图文并茂的指南(包含各种易错点、边界案例),让标注员参加多轮考试(每轮标注30个视频),并在考完后提供详细的错误反馈PDF。经过培训,无论是专家还是小白,准确率都提升了10-15%。只有通过所有培训(平均耗时20小时!)的人才能上岗。此外,还有随机抽查和反馈机制,以保证质量。
通过这套流程,得到的数据质量非常高,既有结构化的标签,又有丰富的自然语言描述。
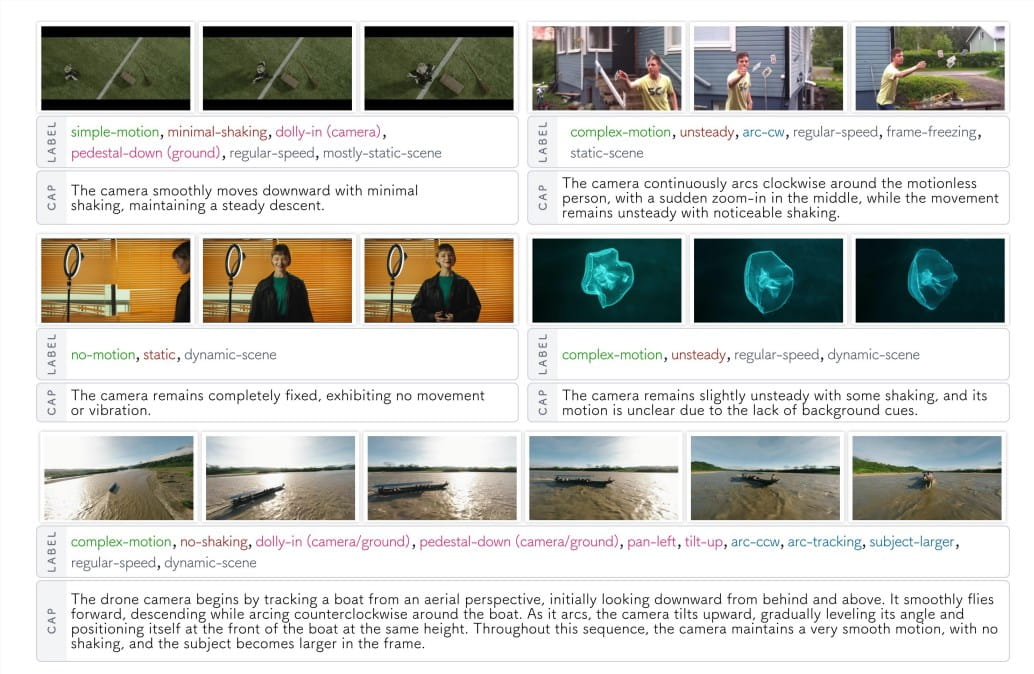
CameraBench上的“期末考试”
有了高质量的教材和考卷,研究人员立即将市面上主流的AI模型拉来参加“考试”。考试题目包括运动分类、视频问答(VQA)、视频描述生成、视频文本检索等。
考试结果显示,AI模型的表现参差不齐:
1. 几何学派(SfM/SLAM)
- 优点:在处理简单、静态的场景时表现良好。基于学习的方法(如MegaSAM)比传统方法(如COLMAP)在处理动态场景时表现更佳。
- 缺点:在遇到主体移动、背景纹理较少的视频时表现较差;对旋转和移动的区分能力不足;完全不理解语义(例如无法判断“这是一个跟踪镜头”)。
- 结论:基本功扎实,但应用能力不足。
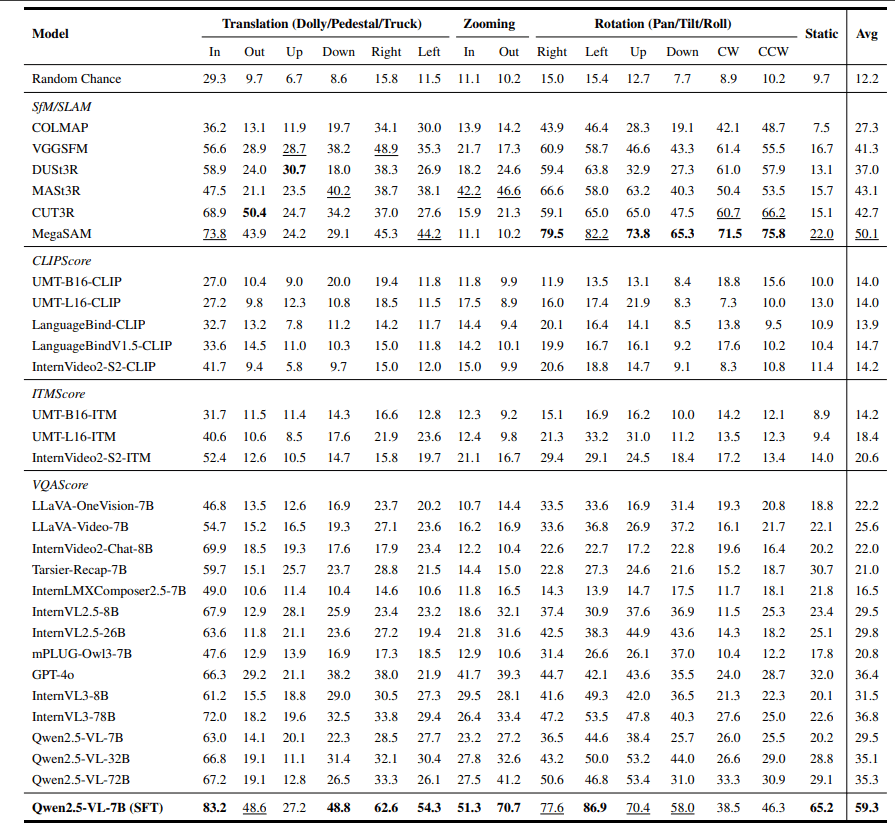
2. 语言模型(VLM)
- 优点:在语义理解方面具有潜力,例如能够大致判断出“相机在跟随人走”。生成式VLM(如GPT-4o)普遍比判别式VLM表现更好。
- 缺点:几何感知能力较差,难以精确判断是Pan还是Truck,是Dolly还是Zoom。在VQA测试中,许多模型的表现甚至不如随机猜测。
- 结论:擅长语言表达,但缺乏对物理世界的精确感知。
3. VLM的“电影课”
既然VLM具有潜力,研究人员便尝试使用CameraBench的高质量数据来提升VLM的能力。他们选择了一个表现不错的生成式VLM(Qwen2.5-VL),并使用CameraBench的一部分数据(约1400个视频)进行了监督微调(SFT)。
结果显示,微调后的模型性能得到了显著提升:
- 分类任务:在镜头运动分类任务上,性能提升了1-2倍,整体表现与最好的几何方法MegaSAM持平。
- 生成任务(描述/VQA):生成的镜头描述更加准确、细致。在VQA任务中也表现出色,尤其是在需要理解复杂逻辑和物体中心运动的任务上。
这表明,高质量、带有精确几何和语义标注的数据对于提升VLM理解视频动态(尤其是镜头运动)的能力至关重要。CameraBench提供的“教材”确实有效。
未来展望:让AI真正“看懂”运动的世界
CameraBench项目是让AI理解镜头运动的关键一步。它告诉我们:
- 需要专业的分类法:定义清晰、参照系明确是基础。
- 高质量数据是王道:专家参与、严格的标注流程和培训必不可少。
- 几何和语义要结合:SfM/SLAM和VLM各有优劣,未来需要融合两者之长。
- 微调潜力巨大:即使是小规模的高质量数据微调,也能显著提升现有大模型的能力。
当然,研究还在继续。未来可能需要更多样、更刁钻的数据,探索更有效的模型训练方法,甚至让AI不仅能识别运镜,还能理解运镜背后的情感和导演意图。
下次你看片时,AI 可能比你更懂“镜头”了!
总而言之,CameraBench 不仅仅是一个数据集,它更像是一个 “AI 电影学院” 的雏形。它用严谨的方法论、专业的知识和高质量的数据,试图教会 AI 这个“直男”如何欣赏和理解镜头运动这门充满魅力的“视觉舞蹈”。
虽然现在的 AI 在这方面还像个刚入门的学生,但有了 CameraBench 这样的“教科书”和“训练场”,相信不久的将来,AI 不仅能看懂视频里的猫猫狗狗,更能和你一起讨论:“哇,你看诺兰这个旋转镜头用得多妙!”
想了解更多技术细节可至项目页查看~








