
在人工智能领域,多模态模型的研发一直是备受关注的热点。近日,阿里巴巴Qwen团队推出了其最新的轻量级多模态AI模型——Qwen2.5-Omni-3B,这款模型作为Qwen2.5-Omni-7B的精简版本,在保证多模态性能的同时,更加注重在消费级硬件上的应用。本文将对Qwen2.5-Omni-3B的技术原理、主要功能、应用场景以及未来发展趋势进行深入分析,以便读者能够全面了解这款模型的价值与潜力。
Qwen2.5-Omni-3B:技术架构与核心优势
Qwen2.5-Omni-3B的核心在于其独特的技术架构和设计理念。作为一款轻量级模型,它在参数量上进行了精简,从7B缩减到3B,使其能够在资源受限的设备上运行。然而,这种精简并没有牺牲模型的性能,反而通过架构创新和优化,使其在多模态任务中依然能够保持卓越的表现。
多模态输入与实时响应
Qwen2.5-Omni-3B模型支持多种输入模态,包括文本、音频、图像和视频。这种多模态输入能力使得模型能够处理更加复杂的任务,例如视频内容分析、语音交互等。更重要的是,Qwen2.5-Omni-3B具备实时生成文本和自然语音响应的能力,这意味着它可以应用于实时性要求较高的场景,例如智能客服、实时翻译等。
语音定制与个性化体验
为了提供更加个性化的用户体验,Qwen2.5-Omni-3B模型支持语音定制功能。用户可以在两个内置声音之间进行选择,分别是女性声音Chelsie和男性声音Ethan。这种语音定制功能使得模型能够更好地适应不同的应用场景和用户需求,从而提升用户满意度。
显存优化与高效运行
在实际应用中,显存占用是一个非常重要的考虑因素。Qwen2.5-Omni-3B模型在显存优化方面做了大量工作。通过优化模型结构和算法,Qwen2.5-Omni-3B在处理长上下文输入时,显存占用大幅降低。具体来说,处理25,000 token的长上下文输入时,显存占用从7B模型的60.2GB降至28.2GB,减少了53%。这意味着Qwen2.5-Omni-3B可以在24GB GPU的设备上运行,大大降低了硬件门槛。
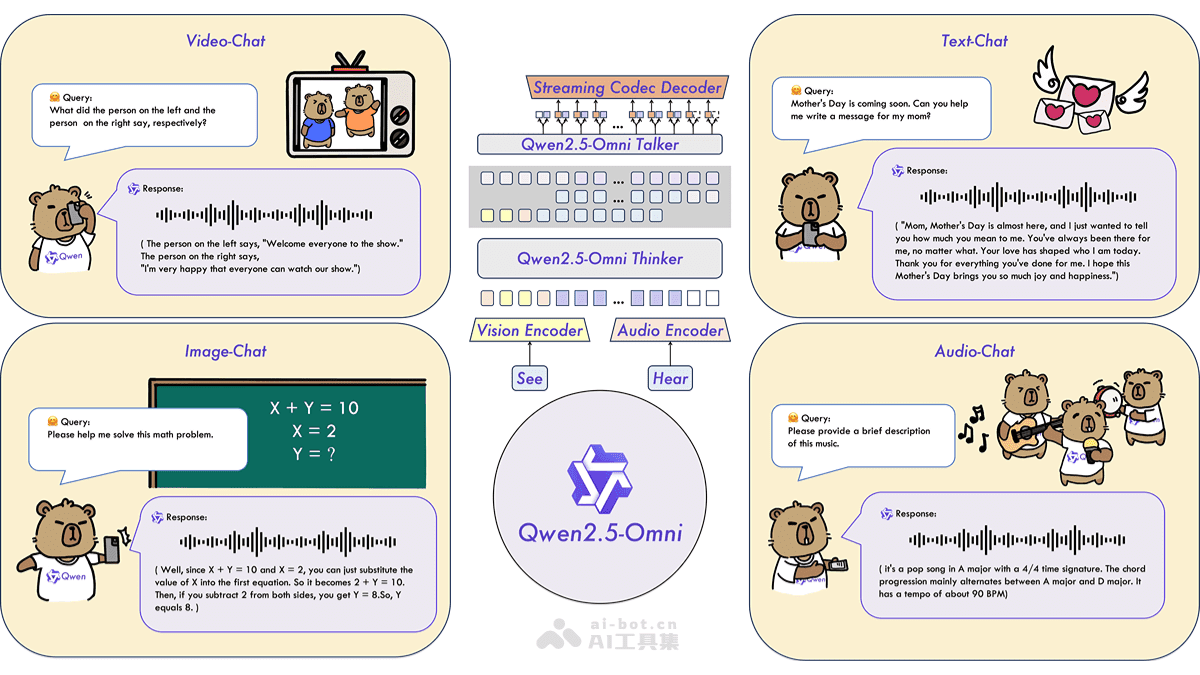
Thinker-Talker架构与TMRoPE技术
Qwen2.5-Omni-3B模型采用了Thinker-Talker架构,这种架构将模型分为“思考者”(Thinker)和“说话者”(Talker)两个部分。Thinker负责处理和理解多模态输入,生成高级语义表示和文本输出;Talker基于Thinker的输出生成自然语音,确保文本生成和语音输出的同步进行。
为了实现视频与音频输入的同步理解,Qwen2.5-Omni-3B提出了时间对齐多模态位置嵌入(TMRoPE)技术。通过交错排列音频和视频帧的时间ID,将多模态输入的三维位置信息编码到模型中,从而实现视频与音频的同步处理。
性能表现与基准测试
尽管Qwen2.5-Omni-3B是一款轻量级模型,但其性能表现却非常出色。在多模态基准测试中,Qwen2.5-Omni-3B的性能接近7B模型。例如,在VideoBench视频理解测试中,Qwen2.5-Omni-3B得分为68.8;在Seed-tts-eval语音生成测试中,Qwen2.5-Omni-3B得分为92.1。这些数据充分证明了Qwen2.5-Omni-3B在多模态任务中的强大能力。
Qwen2.5-Omni-3B的技术原理:深入剖析
要深入了解Qwen2.5-Omni-3B,必须对其技术原理进行剖析。Qwen2.5-Omni-3B在架构设计、多模态处理、实时响应等方面都采用了独特的技术方案。
Thinker-Talker架构的优势
Thinker-Talker架构是Qwen2.5-Omni-3B的核心组成部分。这种架构将模型分为两个模块,分别负责不同的任务。Thinker模块负责理解输入,提取信息,生成文本;Talker模块则负责将文本转化为自然语音。这种分工使得模型能够更加高效地处理多模态输入,并生成高质量的输出。
Thinker-Talker架构的优势在于:
- 解耦设计:Thinker和Talker模块相互独立,可以分别进行优化,从而提高整体性能。
- 高效处理:Thinker模块专注于理解输入,Talker模块专注于生成语音,这种分工使得模型能够更加高效地处理多模态输入。
- 灵活性:Thinker和Talker模块可以根据不同的应用场景进行调整,从而适应不同的需求。
TMRoPE:时间对齐的多模态位置嵌入
在多模态任务中,如何将不同模态的信息进行有效融合是一个关键问题。Qwen2.5-Omni-3B通过TMRoPE技术解决了这个问题。TMRoPE是一种时间对齐的多模态位置嵌入方法,它能够将视频和音频的时间信息进行对齐,从而实现视频与音频的同步理解。
TMRoPE的原理如下:
- 时间ID编码:将视频帧和音频帧的时间信息编码为时间ID。
- 交错排列:将视频帧和音频帧的时间ID进行交错排列,形成一个统一的时间序列。
- 位置嵌入:将时间序列输入到位置嵌入层,生成位置嵌入向量。
通过TMRoPE技术,Qwen2.5-Omni-3B能够有效地将视频和音频信息进行融合,从而提高多模态任务的性能。
流式处理与实时响应
Qwen2.5-Omni-3B采用了流式处理方法,将长序列的多模态数据分解为小块进行处理,从而减少处理延迟。此外,模型还引入了滑动窗口机制,限制当前标记的上下文范围,进一步优化流式生成的效率。
流式处理和滑动窗口机制使得Qwen2.5-Omni-3B能够以流式方式实时生成文本和语音响应,从而满足实时性要求较高的应用场景。
精度优化:FlashAttention 2和BF16
为了进一步提升处理速度并降低内存消耗,Qwen2.5-Omni-3B支持FlashAttention 2和BF16精度优化。
FlashAttention 2是一种高效的注意力机制,它能够显著减少计算量和内存占用,从而提高模型的运行速度。
BF16是一种半精度浮点数格式,它能够在保证模型性能的同时,降低内存占用。通过使用BF16精度,Qwen2.5-Omni-3B能够在资源受限的设备上运行。
Qwen2.5-Omni-3B的应用场景:无限可能
Qwen2.5-Omni-3B作为一款强大的多模态AI模型,具有广泛的应用前景。以下将介绍Qwen2.5-Omni-3B在不同领域的应用。
视频理解与分析
Qwen2.5-Omni-3B能够实时处理和分析视频内容,可以应用于视频内容分析、监控视频解读、智能视频编辑等领域。例如,在视频内容分析方面,Qwen2.5-Omni-3B可以自动识别视频中的人物、物体、场景等,并生成视频摘要;在监控视频解读方面,Qwen2.5-Omni-3B可以自动检测异常行为,并发出警报;在智能视频编辑方面,Qwen2.5-Omni-3B可以自动剪辑视频,添加特效,生成高质量的视频内容。
语音生成与交互
Qwen2.5-Omni-3B支持语音定制功能,用户可以在两个内置声音之间选择。这使得Qwen2.5-Omni-3B可以应用于智能语音助手、语音播报系统、有声读物生成等场景。例如,在智能语音助手方面,Qwen2.5-Omni-3B可以理解用户的语音指令,并执行相应的操作;在语音播报系统方面,Qwen2.5-Omni-3B可以自动播报新闻、天气、交通等信息;在有声读物生成方面,Qwen2.5-Omni-3B可以将文本转化为自然流畅的语音,为用户提供听觉上的享受。
智能客服与自动化报告生成
Qwen2.5-Omni-3B可以处理文本输入并实时生成文本响应,适用于智能客服系统,能快速解答用户问题并提供解决方案。此外,Qwen2.5-Omni-3B还可以自动生成报告,例如市场分析报告、财务报告等。这可以大大提高工作效率,减少人工成本。
教育与学习工具
在教育领域,Qwen2.5-Omni-3B可以辅助教学,例如通过语音和文本交互帮助学生解答问题、提供学习指导。特别是在数学教学方面,Qwen2.5-Omni-3B可以解析几何问题并提供分步推理指导,帮助学生更好地理解数学知识。
创意内容生成
Qwen2.5-Omni-3B能分析图像内容并生成图文结合的创意内容。例如,Qwen2.5-Omni-3B可以根据用户提供的图片,自动生成配文,制作精美的海报;Qwen2.5-Omni-3B还可以根据用户提供的关键词,自动生成文章、诗歌等创意内容。
总结与展望
Qwen2.5-Omni-3B作为一款轻量级多模态AI模型,具有广泛的应用前景。通过对Qwen2.5-Omni-3B的技术原理、主要功能、应用场景的分析,我们可以看到,Qwen2.5-Omni-3B在多模态任务中具有强大的能力,并且能够在资源受限的设备上运行。随着人工智能技术的不断发展,Qwen2.5-Omni-3B将在更多领域发挥重要作用,为人们的生活带来便利。
未来,我们可以期待Qwen2.5-Omni-3B在以下几个方面取得更大的突破:
- 模型优化:进一步优化模型结构和算法,提高模型性能,降低资源消耗。
- 多模态融合:探索更加有效的多模态融合方法,提高模型对多模态信息的理解能力。
- 实时性:进一步优化流式处理和滑动窗口机制,提高模型的实时性。
- 应用拓展:将Qwen2.5-Omni-3B应用于更多领域,例如医疗、金融等。
Qwen2.5-Omni-3B的发布,标志着多模态AI模型在轻量化和实用化方面取得了重要进展。相信在不久的将来,我们将看到更多基于Qwen2.5-Omni-3B的应用涌现,为人们的生活带来更多惊喜。








