
在人工智能领域,数学推理模型正逐渐崭露头角,为解决复杂问题提供了新的途径。其中,由DeepSeek团队推出的DeepSeek-Prover-V2,作为一款开源的数学推理大模型,受到了广泛关注。本文将深入探讨DeepSeek-Prover-V2的技术原理、功能特性、应用场景及其在数学推理领域带来的突破。同时,也会分析其优势与局限,展望未来发展趋势。
DeepSeek-Prover-V2:技术架构与核心功能
DeepSeek-Prover-V2并非横空出世,而是站在了前代Prover-V1.5的肩膀上,实现了全面升级。该模型拥有两个版本:DeepSeek-Prover-V2-671B和DeepSeek-Prover-V2-7B,分别拥有6710亿和70亿参数。这种规模的模型,旨在处理复杂的数学推理任务,并提供更高的准确性和效率。
该模型采用了混合专家系统(MoE)架构,这一架构允许模型根据不同的输入,动态选择不同的“专家”模块进行处理,从而提高了模型的灵活性和适应性。MoE架构能够有效地提升模型的容量,使其能够处理更复杂的任务,并学习到更细致的知识。
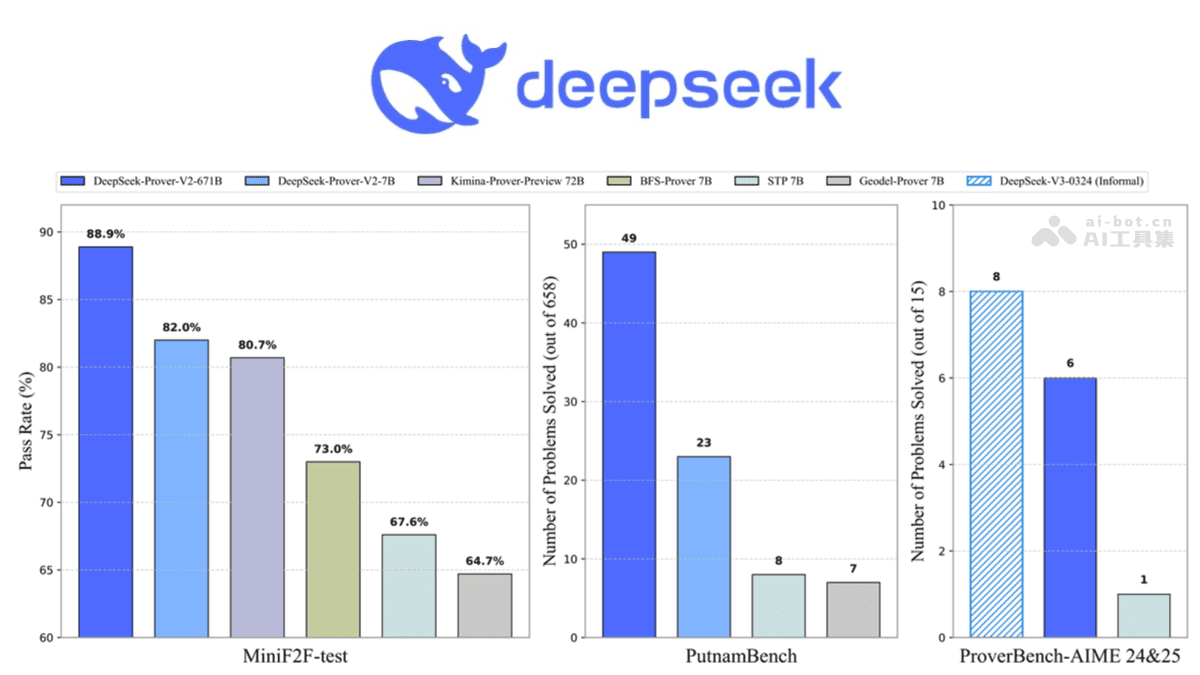
超长上下文支持是DeepSeek-Prover-V2的另一大亮点。它支持最长163,840 tokens的上下文窗口,这意味着模型可以处理更长的文本序列,从而更好地理解问题的背景和约束条件。在数学推理中,长上下文支持尤为重要,因为许多数学问题需要考虑大量的已知条件和中间步骤。
此外,DeepSeek-Prover-V2还支持多精度计算,包括BF16、FP8、F32等。这种灵活性使得模型可以在不同的硬件平台上运行,并根据计算资源进行优化。例如,在资源受限的设备上,可以使用较低的精度来降低计算成本;而在高性能服务器上,可以使用较高的精度来提高准确性。
该模型的核心功能可以概括为以下几个方面:
数学问题解决:DeepSeek-Prover-V2能够处理从基础代数到高等数学的各类问题。它不仅可以进行数值计算,还可以进行符号推理和定理证明。通过将自然语言问题转化为形式化证明代码,模型能够自动验证数学命题的正确性。
形式化推理训练:DeepSeek-Prover-V2基于Lean 4框架进行形式化推理训练。Lean 4是一种用于形式化数学的编程语言和证明助手。通过在Lean 4中进行训练,模型能够学习到严格的逻辑推理规则,从而提高其证明能力。
高效训练与部署:DeepSeek-Prover-V2使用了safetensors文件格式,这种格式比传统的PyTorch格式更高效,可以加快模型的加载和保存速度。同时,模型支持多种计算精度,方便在不同的硬件平台上进行训练和部署。
超长上下文处理:DeepSeek-Prover-V2支持长达163,840 tokens的上下文窗口,使其能够处理复杂的数学证明任务。
双模式解题:DeepSeek-Prover-V2提供快速模式和逻辑模式两种解题方式。快速模式直接生成代码答案,适用于对效率要求较高的场景;逻辑模式则分步拆解推理过程,适用于需要详细解释的场景。
知识蒸馏与优化:DeepSeek-Prover-V2可以通过知识蒸馏技术将大型模型的知识迁移到小型模型中,从而在资源受限的设备上实现高性能推理。
技术原理:MLA架构、MoE与强化学习
DeepSeek-Prover-V2的技术原理主要体现在以下几个方面:
多头潜注意力(MLA)架构:MLA架构是DeepSeek-Prover-V2的核心组成部分。它通过压缩键值缓存(KV Cache),有效地降低了推理过程中的内存占用和计算开销。KV Cache存储了模型在处理输入序列时产生的中间结果,MLA架构通过减少KV Cache的大小,从而降低了计算成本。这种优化使得模型在资源受限的环境下也能高效运行。
混合专家(MoE)架构:MoE架构允许模型根据不同的输入,动态选择不同的“专家”模块进行处理。每个专家模块都专注于处理特定类型的任务或数据。通过这种方式,模型可以更好地适应不同的输入,并提高其整体性能。MoE架构通常包含一个门控网络(Gating Network),用于决定哪些专家应该被激活。
文件格式与计算精度:DeepSeek-Prover-V2-671B使用了safetensors文件格式,这种格式比传统的PyTorch格式更高效,可以加快模型的加载和保存速度。同时,模型支持多种计算精度,包括BF16、FP8、F32等。这种灵活性使得模型可以在不同的硬件平台上运行,并根据计算资源进行优化。
强化学习与训练范式:DeepSeek-Prover-V2采用了三阶段训练范式:预训练、数学专项训练以及人类反馈强化学习(RLHF)微调。预训练阶段使用大量的文本数据来训练模型的基本语言能力。数学专项训练阶段则使用数学数据集来提高模型在数学领域的性能。RLHF微调阶段则使用人类反馈来优化模型的输出,使其更符合人类的偏好。
在强化学习阶段,模型使用GRPO算法,通过为每个定理采样一组候选证明并根据它们的相对奖励优化策略。模型通过课程学习逐步增加训练任务的难度,引导模型学习更复杂的证明。课程学习是一种逐步增加训练难度的策略,它可以帮助模型更好地学习复杂的任务。
- 形式化证明器集成:DeepSeek-Prover-V2创新性地集成了形式化证明器,能将自然语言问题转化为Coq/Lean等证明辅助系统的代码表示。这种集成使得模型可以利用现有的形式化证明工具来验证其推理结果,从而提高其可靠性。
应用场景:教育、科研与工程
DeepSeek-Prover-V2的应用场景非常广泛,涵盖了教育、科研、工程等多个领域。
在教育领域,DeepSeek-Prover-V2可以作为强大的教学辅助工具,帮助学生和教师解决复杂的数学问题。它可以自动生成解题步骤、验证答案的正确性,并提供个性化的学习建议。例如,学生可以使用DeepSeek-Prover-V2来检查他们的作业,或者教师可以使用它来生成教学材料。
在科学研究中,DeepSeek-Prover-V2能协助研究人员进行复杂数学建模和理论验证。它可以帮助研究人员更快地发现新的数学规律,并验证他们的假设。例如,物理学家可以使用DeepSeek-Prover-V2来验证他们的理论模型,或者生物学家可以使用它来分析复杂的生物数据。
在工程设计领域中,DeepSeek-Prover-V2可以应用于优化设计和模拟测试。它可以帮助工程师设计出更高效、更可靠的产品。例如,汽车工程师可以使用DeepSeek-Prover-V2来优化汽车的空气动力学性能,或者建筑工程师可以使用它来设计更安全的建筑物。
此外,DeepSeek-Prover-V2还可以应用于金融分析、软件开发等领域。在金融领域,它可以用于风险评估和投资策略分析;在软件开发过程中,它可以辅助开发者进行算法设计和性能优化。
局限性与未来展望
尽管DeepSeek-Prover-V2在数学推理领域取得了显著进展,但它仍然存在一些局限性。
首先,模型的计算成本较高,需要大量的计算资源才能进行训练和推理。这限制了其在资源受限设备上的应用。
其次,模型对于输入数据的质量要求较高。如果输入数据存在错误或歧义,模型可能会产生错误的推理结果。
此外,模型在处理一些非常复杂的数学问题时,可能仍然无法达到人类专家的水平。
未来,DeepSeek-Prover-V2的发展方向可能包括以下几个方面:
降低计算成本:通过优化模型架构和算法,降低模型的计算成本,使其能够在更多的设备上运行。
提高鲁棒性:提高模型对于输入数据质量的鲁棒性,使其能够处理存在错误或歧义的数据。
增强推理能力:通过引入新的推理机制和知识表示方法,增强模型在复杂数学问题上的推理能力。
扩展应用领域:将模型应用于更多的领域,例如自然语言处理、计算机视觉等。
总的来说,DeepSeek-Prover-V2作为一款开源的数学推理大模型,为数学推理领域带来了新的突破。它在技术架构、功能特性和应用场景等方面都具有显著优势。随着技术的不断发展,DeepSeek-Prover-V2有望在未来发挥更大的作用,为人类解决复杂问题提供更强大的工具。








