
在人工智能领域,Meta AI 近期推出了一款名为 ReasonIR-8B 的新型模型,该模型专为推理密集型检索任务设计,引起了业界的广泛关注。ReasonIR-8B 基于 LLaMA3.1-8B 架构进行训练,采用了双编码器结构,旨在提升模型在处理复杂查询和长上下文时的能力。本文将深入探讨 ReasonIR-8B 的技术原理、主要功能、应用场景以及其在检索任务中的优势。
ReasonIR-8B:技术原理与架构
ReasonIR-8B 的核心在于其双编码器架构。这种架构将查询(query)和文档(document)分别编码成嵌入向量,并通过计算余弦相似度来评估它们之间的相关性。具体来说,查询和文档会分别通过独立的编码器,转换成固定维度的向量表示。这些向量在向量空间中的距离反映了查询与文档之间的语义相似度。余弦相似度是一种常用的度量方法,它计算两个向量夹角的余弦值,值越高表示相似度越高。
为了提升模型处理复杂查询的能力,ReasonIR-8B 的训练数据包含了多样长度的查询(Varied-Length Queries,简称 VL Queries)和需要逻辑推理的困难查询(Hard Queries,简称 HQ)。VL Queries 的长度可达 2000 个 token,这使得模型能够更好地处理长篇和跨领域的查询。HQ 则侧重于考察模型的推理能力,通过设计需要逻辑推理才能正确回答的查询,来提升模型对抽象问题的理解和处理能力。
ReasonIR-8B 结合了创新的数据生成工具 ReasonIR-SYNTHESIZER,用于构建模拟真实推理挑战的合成查询和文档对。ReasonIR-SYNTHESIZER 的一个重要特点是能够生成“难负样本”。传统的负样本生成方法通常依赖于词汇匹配,例如选择与查询没有共同词汇的文档作为负样本。然而,这种方法生成的负样本往往过于简单,容易被模型区分。ReasonIR-SYNTHESIZER 通过多轮提示(multi-turn prompting)生成更具迷惑性的负样本,从而提高模型的判别能力。
ReasonIR-8B 的训练数据还包括现有的公共数据集,例如 MS MARCO 和 Natural Questions。这些数据集包含了大量的真实查询和文档对,可以为模型提供多样化的训练数据。通过结合合成数据和公共数据,ReasonIR-8B 能够更好地泛化到不同的检索任务中。
对比学习:优化检索器
ReasonIR-8B 使用对比学习(contrastive learning)目标来优化检索器。对比学习的目标是使模型能够将查询嵌入到与相关文档更接近的向量空间中,同时远离不相关的文档。具体来说,对于一个给定的查询,模型会计算其与正样本(相关文档)和负样本(不相关文档)之间的相似度。然后,模型会调整其参数,使得查询与正样本的相似度更高,与负样本的相似度更低。
对比学习是一种有效的训练方法,可以帮助模型学习到更好的嵌入表示。通过对比学习,ReasonIR-8B 能够更好地捕捉查询和文档之间的语义关系,从而提高检索的准确性。
测试时优化:提升检索性能
除了训练时的优化,ReasonIR-8B 在测试时也采用了一些技术来进一步提升性能。这些技术包括查询重写(query rewriting)和 LLM 重排器(LLM reranker)。
查询重写是指使用语言模型将原始查询重写为更长、更详细的信息性查询。例如,对于一个简单的查询“巴黎的天气”,查询重写可能会将其扩展为“请告诉我今天巴黎的天气预报,包括温度、湿度和风速”。通过重写查询,可以为检索器提供更多的上下文信息,从而提高检索质量。
LLM 重排器是指结合语言模型对检索结果进行重排。检索器返回的初始结果可能包含一些不准确或不相关的文档。LLM 重排器会使用语言模型对这些结果进行重新排序,将更准确和相关的文档排在前面。LLM 重排器可以利用语言模型的理解能力和生成能力,对检索结果进行更细致的评估和排序,从而提高检索的准确性和相关性。
ReasonIR-8B 的主要功能
ReasonIR-8B 的主要功能可以概括为以下几点:
- 复杂查询处理:ReasonIR-8B 采用双编码器架构,能够有效处理长篇和跨领域的复杂查询。通过训练数据中包含的长达 2000 个 token 的多样长度查询和需要逻辑推理的困难查询,模型显著提升了处理长上下文和抽象问题的能力。
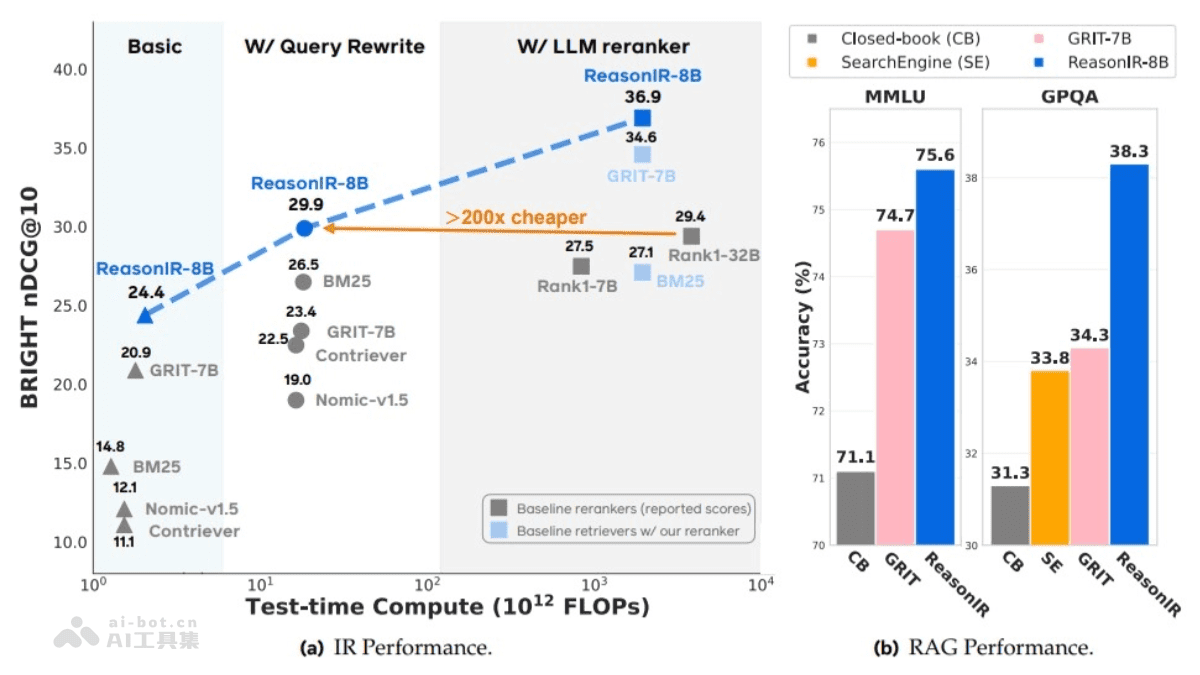
- 推理精度提升:在 BRIGHT 基准测试中,ReasonIR-8B 的原查询得分达到了 24.4 nDCG@10,结合 Qwen2.5 重新排序后提升至 36.9,远超更大的 Rank1-32B 模型,且计算成本仅为后者的 1/200。此外,在 MMLU 和 GPQA 等 RAG 任务中,模型分别带来了 6.4% 和 22.6% 的显著提升。这表明 ReasonIR-8B 在推理精度方面具有显著优势。
- 合成数据生成:ReasonIR-8B 结合了创新的数据生成工具 ReasonIR-SYNTHESIZER,能够构建模拟真实推理挑战的合成查询和文档对,更精准地支持复杂任务。通过多轮提示构建“难负样本”,区别于传统词汇匹配式负样本方法,进一步提高了模型的判别能力。
ReasonIR-8B 的应用场景
ReasonIR-8B 在多个领域都具有广泛的应用前景:
- 复杂问答系统:在法律咨询、医学研究或学术问题解答等需要推理的问答系统中,ReasonIR-8B 能够提供更准确和相关的文档支持。例如,在法律咨询中,用户可能需要查询与特定法律条款相关的判例和解释。ReasonIR-8B 可以根据用户的查询,检索相关的法律文档,并提供准确的答案。
- 教育和学习工具:在教育领域,ReasonIR-8B 可以帮助学生和教师找到与复杂问题相关的背景知识和推理模式,辅助学习和教学。例如,学生在学习历史时,可能需要查找与特定历史事件相关的资料。ReasonIR-8B 可以根据学生的查询,检索相关的历史文献和研究报告,帮助学生更好地理解历史事件。
- 企业知识管理:在企业环境中,ReasonIR-8B 可以用于内部知识库的检索,帮助员工快速找到与复杂问题相关的解决方案和背景信息。例如,员工在处理客户投诉时,可能需要查找与特定产品或服务相关的文档。ReasonIR-8B 可以根据员工的查询,检索相关的产品手册、故障排除指南和客户服务记录,帮助员工更快地解决问题。
- 研究和开发:在科研和开发中,ReasonIR-8B 可以帮助研究人员快速找到相关的文献、实验结果和研究方法,加速研究进程。例如,研究人员在进行一项新的研究时,可能需要查找与该研究相关的最新论文。ReasonIR-8B 可以根据研究人员的查询,检索相关的学术论文和研究报告,帮助研究人员了解最新的研究进展。
ReasonIR-8B 的项目地址
对于有兴趣深入了解 ReasonIR-8B 的读者,可以参考以下资源:
- Github 仓库:https://github.com/facebookresearch/ReasonIR
- HuggingFace 模型库:https://huggingface.co/reasonir/ReasonIR-8B
- arXiv 技术论文:https://arxiv.org/pdf/2504.20595
结论
ReasonIR-8B 是 Meta AI 在推理密集型检索任务方面取得的一项重要进展。通过采用双编码器架构、结合合成数据和公共数据、使用对比学习目标以及在测试时进行优化,ReasonIR-8B 在处理复杂查询和长上下文方面表现出色。其在复杂问答系统、教育和学习工具、企业知识管理以及研究和开发等领域的应用前景广阔。随着人工智能技术的不断发展,ReasonIR-8B 有望在未来的检索任务中发挥更大的作用。








