
在人工智能领域,模型的发展日新月异。近日,IBM发布了Granite 4.0 Tiny Preview,这款新型语言模型以其小巧的体积和强大的性能引起了业界的广泛关注。Granite 4.0 Tiny Preview不仅在计算效率上表现出色,还为开源社区提供了一个极具价值的实验平台。本文将深入探讨Granite 4.0 Tiny Preview的技术特点、应用前景以及对AI领域的影响。
Granite 4.0 Tiny Preview:小身材,大能量
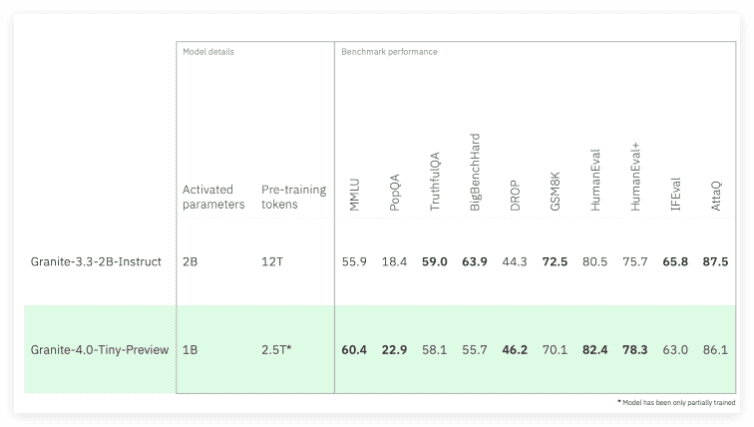
Granite 4.0 Tiny Preview是IBM即将推出的Granite 4.0系列语言模型中最小巧的一款。它最大的亮点在于其高效的性能和极低的内存需求。在FP8精度下,Granite 4.0 Tiny Preview能够在消费级硬件上运行多个长上下文(128K)的并发任务,这使得它非常适合在价格低于350美元的GPU上运行。尽管该模型目前仅经过部分训练,处理过2.5万亿个训练标记,但其性能已经接近IBM Granite 3.32B Instruct模型,同时内存需求降低了约72%。随着后续训练的不断深入,预计Granite 4.0 Tiny Preview的性能将达到与Granite 3.38B Instruct相当的水平。
混合架构设计:Mamba-2/Transformer
Granite 4.0系列语言模型采用了全新的混合Mamba-2/Transformer架构,这一创新设计融合了Mamba的速度与效率以及Transformer的自注意力精度。Mamba架构以其高效的序列建模能力而闻名,而Transformer架构则在处理长距离依赖关系方面表现出色。通过将两者结合,Granite 4.0 Tiny Preview在性能上实现了显著的提升。Granite 4.0 Tiny Preview是一个细粒度的混合专家模型,具有70亿个总参数,但在推理时仅激活10亿个参数。这种架构设计不仅提高了模型的效率,还降低了计算成本。值得一提的是,这一创新架构设计源自IBM研究院与Mamba原始创造者的合作,进一步提升了模型的整体性能。
无约束的上下文长度:突破传统限制
Granite 4.0 Tiny Preview的另一个显著特点是其理论上能够处理无限长的序列。这一能力源自其不使用位置编码(NoPE)的设计,有效避免了传统模型在处理长上下文时的性能限制。在传统的Transformer模型中,位置编码是必不可少的一部分,用于告知模型序列中每个token的位置信息。然而,位置编码也会带来一些问题,例如,当处理的序列长度超过训练时使用的最大长度时,模型可能会出现性能下降。Granite 4.0 Tiny Preview通过不使用位置编码,成功地避免了这一问题,从而能够处理更长的上下文。测试结果表明,该模型在处理128K个标记时表现良好,未来还将验证其在更长上下文上的性能表现。
广泛的应用场景:企业应用的理想选择
Granite 4.0 Tiny Preview的内存效率和高性能使其成为多个企业应用的理想选择。例如,在金融领域,它可以用于分析大量的交易数据,从而识别潜在的欺诈行为。在医疗领域,它可以用于处理患者的病历,从而辅助医生进行诊断。在客服领域,它可以用于自动回复客户的问题,从而提高客户满意度。IBM计划在未来几个月内进一步完善模型,并期待在即将召开的IBM Think 2025大会上分享更多信息。这表明IBM对Granite 4.0 Tiny Preview的未来发展充满信心,并计划将其应用于更多的实际场景中。
开源社区的福音:促进AI技术的普及
IBM发布Granite 4.0 Tiny Preview不仅是对高效能语言模型的一次大胆尝试,更是对开源社区的一次有力支持。通过开源Granite 4.0 Tiny Preview,IBM希望能够促进AI技术的普及,让更多的开发者和企业用户能够从中受益。开源不仅可以加速技术的创新,还可以降低AI技术的应用门槛,使得更多的企业和个人能够参与到AI的开发和应用中来。Granite 4.0 Tiny Preview的开源,无疑将为AI领域注入新的活力。
技术细节解析
Granite 4.0 Tiny Preview模型的成功,离不开其背后精巧的技术设计。以下将对该模型的一些关键技术细节进行深入解析:
- 混合专家模型(Mixture of Experts, MoE):Granite 4.0 Tiny Preview采用了细粒度的混合专家模型架构。这意味着模型内部存在多个“专家”模块,每个专家模块负责处理不同类型的输入数据。在推理时,模型会根据输入数据的特点,选择激活最相关的专家模块,从而提高模型的效率和准确性。这种架构设计使得模型能够在保持较小体积的同时,依然能够处理复杂的任务。
- Mamba-2架构:Mamba是一种新型的序列建模架构,它采用了选择性状态空间模型(Selective State Space Model, S6)的设计。与传统的循环神经网络(RNN)和Transformer相比,Mamba在处理长序列时具有更高的效率和更低的计算成本。Mamba-2是Mamba的改进版本,它在Mamba的基础上进行了一些优化,进一步提高了模型的性能。
- Transformer架构:Transformer是一种基于自注意力机制的深度学习模型,它在自然语言处理领域取得了巨大的成功。Transformer模型能够有效地捕捉输入序列中的长距离依赖关系,从而提高模型的性能。Granite 4.0 Tiny Preview将Transformer架构与Mamba-2架构相结合,充分发挥了两者的优势。
- 无位置编码(NoPE):传统的位置编码方法在处理长序列时可能会遇到一些问题,例如,当序列长度超过训练时使用的最大长度时,模型可能会出现性能下降。为了解决这个问题,Granite 4.0 Tiny Preview采用了无位置编码的设计。这意味着模型不依赖于位置信息来处理输入序列,从而能够处理任意长度的序列。

未来展望
Granite 4.0 Tiny Preview的发布,标志着IBM在AI领域迈出了重要的一步。作为一款小巧而强大的语言模型,Granite 4.0 Tiny Preview不仅具有高效的性能和极低的内存需求,还能够处理长上下文,这使得它在多个企业应用中具有广泛的应用前景。随着后续版本的不断推出和完善,Granite 4.0 Tiny Preview有望为开发者和企业用户带来更多的可能性。同时,Granite 4.0 Tiny Preview的开源,也将促进AI技术的普及,让更多的企业和个人能够参与到AI的开发和应用中来。
结语
IBM Granite 4.0 Tiny Preview的发布,无疑是AI领域的一项重要进展。它不仅展示了IBM在AI技术方面的强大实力,也为未来的AI发展指明了方向。我们有理由相信,在IBM等科技巨头的推动下,AI技术将会在更多的领域得到应用,为人类社会带来更多的福祉。








