
在人工智能领域,NVIDIA 一直是创新和突破的代名词。最近,NVIDIA AI 研究团队发布了一项引人注目的新技术——Audio-SDS,它将 Score Distillation Sampling (SDS) 技术扩展到了文本条件音频扩散模型。这项技术上的革新,不仅显著提升了音效生成的能力,还在音源分离和多任务音频处理方面展现出了强大的潜力。Audio-SDS 的出现,无疑为音频处理领域带来了新的活力,并在学术界和工业界引发了广泛的关注和讨论。
Audio-SDS 技术的核心原理
Audio-SDS 的核心在于将 NVIDIA 在图像生成领域广泛应用的 SDS 技术,巧妙地适配到了预训练的音频扩散模型中。这一创新性的做法,打破了传统音频处理的局限,实现了从单一模型到多任务音频处理的跨越。其核心创新主要体现在以下几个方面:
- 通用性扩展: Audio-SDS 的强大之处在于其通用性。它无需对模型进行重新训练,即可将任意预训练的音频扩散模型转化为多功能工具,适用于音效生成、音源分离、FM 合成和语音增强等多种任务。这种通用性极大地降低了开发成本和时间,为开发者提供了更大的灵活性。
- 文本条件控制: 通过文本提示来引导音频的生成是 Audio-SDS 的另一大亮点。这种文本条件控制的方式,使得用户可以根据自己的需求,高度定制化地设计音效,从而满足创意和工业需求。无论是逼真的环境音效,还是天马行空的创意音效,都可以通过简单的文本描述来实现。
- 高效推理: 为了保证高质量的输出,并提升实时应用的可行性,Audio-SDS 对 SDS 算法进行了优化,降低了计算复杂度。这意味着,即使在计算资源有限的情况下,Audio-SDS 依然能够高效地完成音频处理任务。
NVIDIA 在其技术报告中,展示了 Audio-SDS 的多项演示案例,包括从环境音效生成到复杂音源分离。这些案例充分展示了 Audio-SDS 强大的泛化能力和实用性。为了方便开发者学习和使用,NVIDIA 还通过官方渠道公开了相关的论文和音频样本,为开发者提供了丰富的参考资源。
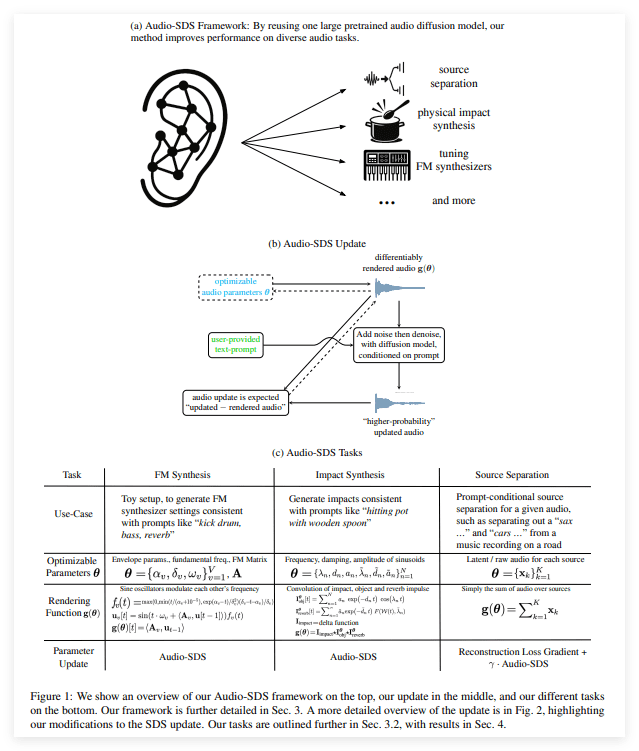
Audio-SDS 的性能亮点
Audio-SDS 在多项音频处理任务中都展现出了卓越的性能,尤其是在以下场景中表现突出:
- 音源分离: Audio-SDS 能够从混合音频中精准地提取目标音轨。这项功能在音乐制作和视频后期处理中具有重要的应用价值。例如,它可以帮助音乐制作人将人声从伴奏中分离出来,或者将电影中的对话从背景噪音中提取出来。
- 音效合成: Audio-SDS 可以生成逼真的环境音效或创意音效,如爆炸声、风声等。这对于游戏开发和虚拟现实 (VR) 应用来说,无疑是一个福音。开发者可以利用 Audio-SDS 快速生成各种各样的音效,从而提升游戏的沉浸感和 VR 体验的真实感。
- FM 合成与语音增强: Audio-SDS 支持高质量的频率调制合成和语音清晰度提升。这意味着,它可以被应用于音频编辑软件和智能语音助手等领域。例如,音频编辑软件可以利用 Audio-SDS 来生成各种各样的音乐,而智能语音助手则可以利用 Audio-SDS 来提升语音识别的准确率。
与传统的音频处理模型相比,Audio-SDS 无需针对单一任务进行专门训练,这极大地降低了开发成本和时间。更重要的是,其基于文本条件的生成能力,进一步增强了用户交互体验,使得非专业用户也能通过简单的描述,生成高质量的音频内容。这种便捷性和易用性,无疑将极大地推动 AI 音频技术的发展和普及。
Audio-SDS 的应用前景
Audio-SDS 的发布,标志着 NVIDIA 在 AI 音频领域又迈出了重要一步。其潜在的应用场景涵盖了多个行业:
- 娱乐与媒体: Audio-SDS 可以为电影、游戏和虚拟现实提供沉浸式音效设计,从而提升用户体验。无论是电影中的爆炸场面,还是游戏中的战斗场景,都可以通过 Audio-SDS 来创造出更加逼真和震撼的音效。
- 智能设备: Audio-SDS 可以增强语音助手的语音处理能力,优化噪声环境下的交互效果。这意味着,即使在嘈杂的环境中,语音助手也能准确地识别用户的语音指令,并做出相应的回应。
- 教育与创作: Audio-SDS 可以为音乐制作人和内容创作者提供高效的工具,降低专业音频处理的门槛。无论是专业的音乐制作人,还是业余的音频爱好者,都可以利用 Audio-SDS 轻松地创作出高质量的音频内容。
Audio-SDS 的开源演示和灵活架构,使其有望成为音频处理领域的标杆技术。NVIDIA 对 AI 多模态研究的持续投入,也预示着其未来可能进一步扩展至视频、3D 建模等领域。这意味着,在不久的将来,我们可能会看到更多基于 Audio-SDS 的创新应用出现。
NVIDIA 推动 AI 音频创新
NVIDIA 一直致力于通过开源和生态建设,加速 AI 技术的普及。Audio-SDS 的论文、代码和演示样本,已经通过官方渠道发布,开发者可以自由访问并基于此进行二次开发。这种开放的策略,不仅促进了学术研究,也为中小型企业提供了低成本的 AI 音频解决方案。通过这种方式,NVIDIA 正在积极地推动 AI 音频技术的创新和发展。
此外,NVIDIA 的 Omniverse 平台和 Isaac 机器人平台,近年来在多模态 AI 应用中表现亮眼。Audio-SDS 的推出,进一步丰富了其技术生态,为构建统一的 AI 内容生成框架奠定了基础。这意味着,NVIDIA 正在构建一个完整的 AI 生态系统,将各种 AI 技术整合在一起,从而为用户提供更加全面和强大的 AI 解决方案。
Audio-SDS:开启 AI 音频新篇章
NVIDIA 的 Audio-SDS 以其创新的 SDS 适配技术和多任务处理能力,为 AI 音频领域注入了新的活力。从音效生成到音源分离,这款技术展示了 AI 在音频处理中的无限可能。随着 AI 技术的不断发展,我们有理由相信,Audio-SDS 将会在未来的音频处理领域发挥越来越重要的作用,并为我们带来更多惊喜。
深入剖析 Audio-SDS 技术细节
为了更全面地理解 Audio-SDS 的技术优势,我们有必要深入剖析其技术细节。Audio-SDS 的核心在于 Score Distillation Sampling (SDS) 技术,这是一种基于扩散模型的生成方法。扩散模型通过逐步添加噪声来破坏原始数据,然后再学习如何从噪声中恢复原始数据。这种方法可以生成非常逼真和高质量的数据,但计算成本也相对较高。
SDS 技术通过引入一个评分函数来指导扩散模型的生成过程,从而提高生成效率和质量。评分函数可以根据文本描述或其他条件,来评估生成数据的质量,并引导扩散模型朝着更符合要求的方向生成。Audio-SDS 将 SDS 技术应用于音频扩散模型,从而实现了文本条件控制的音频生成。
具体来说,Audio-SDS 的工作流程如下:
- 文本编码: 首先,将输入的文本描述通过文本编码器转换成向量表示。这个向量表示包含了文本描述的语义信息,可以作为生成音频的条件。
- 扩散过程: 将随机噪声输入到音频扩散模型中,然后通过迭代的方式,逐步去除噪声,并根据评分函数的指导,生成音频数据。
- 评分指导: 评分函数根据文本编码和生成的音频数据,计算出一个评分。这个评分反映了生成音频与文本描述的匹配程度。扩散模型根据评分的指导,调整生成过程,从而生成更符合文本描述的音频。
- 音频输出: 经过多次迭代后,扩散模型最终生成一段音频数据。这段音频数据既包含了文本描述的语义信息,又具有高质量和逼真度。
通过这种方式,Audio-SDS 实现了文本条件控制的音频生成,并且在音效生成、音源分离和多任务音频处理等方面都取得了显著的成果。
Audio-SDS 的技术挑战与未来发展
尽管 Audio-SDS 在 AI 音频领域取得了显著的进展,但仍然面临着一些技术挑战。其中一个主要的挑战是,如何生成更加复杂和多样化的音频内容。目前的 Audio-SDS 主要集中在生成一些简单的音效和环境音,对于生成复杂的音乐或语音,仍然存在一定的困难。
另一个挑战是,如何提高 Audio-SDS 的生成效率和实时性。虽然 Audio-SDS 已经对 SDS 算法进行了优化,但其计算成本仍然相对较高,难以满足一些实时应用的需求。因此,未来的研究方向之一是,进一步优化 Audio-SDS 的算法,降低计算成本,提高生成效率和实时性。
此外,Audio-SDS 的另一个潜在发展方向是,与其他 AI 技术相结合,例如自然语言处理 (NLP) 和计算机视觉 (CV)。通过将 Audio-SDS 与 NLP 技术相结合,可以实现更加智能化的音频生成,例如根据用户的情感状态或场景描述,自动生成相应的音频内容。通过将 Audio-SDS 与 CV 技术相结合,可以实现更加逼真的音视频同步,例如根据视频内容自动生成相应的音效。
总而言之,Audio-SDS 作为 NVIDIA 在 AI 音频领域的一项重要创新,具有广阔的应用前景和发展潜力。随着技术的不断进步,我们有理由相信,Audio-SDS 将会在未来的音频处理领域发挥越来越重要的作用,并为我们带来更多惊喜。








