
NVIDIA Audio-SDS:文本驱动音频创作的未来
在人工智能与音频处理的交汇点,NVIDIA的Audio-SDS技术应运而生,它不仅仅是一个模型,更是一场音频创作方式的革新。这项技术通过将Score Distillation Sampling(SDS)巧妙地应用于文本条件音频扩散模型,为音频领域打开了前所未有的可能性。Audio-SDS无需对模型进行耗时的重新训练,即可将任何预训练的音频扩散模型转化为一个多功能工具,广泛应用于音效生成、音源分离、FM合成以及语音增强等任务。这种技术的出现,无疑将极大地推动音频内容创作的边界,为创意产业和工业应用注入新的活力。
Audio-SDS的核心功能
Audio-SDS的功能远不止于简单的音频生成,它是一个集多种音频处理能力于一体的强大平台:
- 音效生成:通过文本提示,Audio-SDS能够创造出各种逼真的环境音效和富有创意的声音效果。无论是游戏中所需的爆炸声、电影场景中的风声,还是VR应用中的沉浸式音效,Audio-SDS都能轻松胜任,极大地提升用户体验。
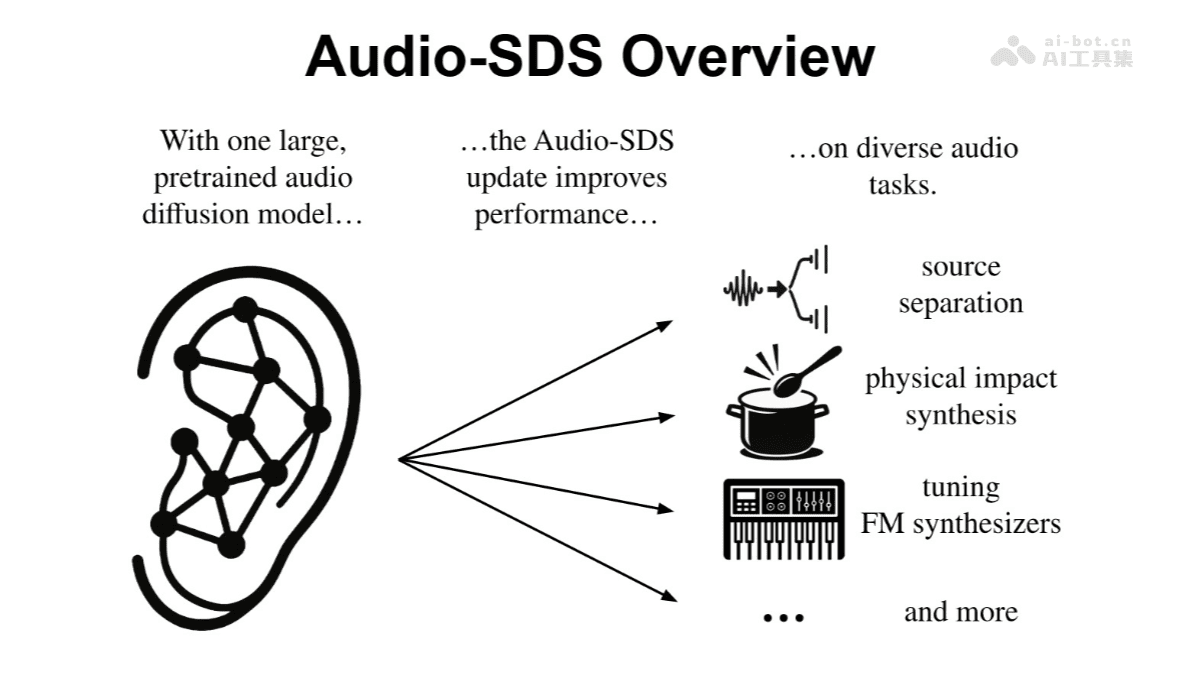
音源分离:Audio-SDS能够从复杂的混合音频中精确提取目标音轨,这在音乐制作和视频后期处理中具有重要意义。例如,它可以自动地将真实世界音频中的不同声源分离出来,无需手动标记或依赖专门的数据集,大大提高了音频处理的效率和精度。
物理信息影响声音模拟:Audio-SDS具备模拟物体碰撞等物理信息对声音产生影响的能力,这为游戏开发、虚拟现实等领域提供了更真实、更具沉浸感的声音体验。通过模拟真实世界的物理规律,Audio-SDS能够生成更符合实际的声音效果,增强用户的感知。
FM合成参数校准:Audio-SDS支持高质量的频率调制合成,这为音色设计师提供了强大的工具。通过精确校准FM合成参数,用户可以创造出各种富有表现力的音色,满足不同音乐风格的需求。
语音增强:Audio-SDS能够有效提升语音的清晰度,这在音频编辑软件和智能语音助手中具有广泛的应用前景。通过降低噪音、消除干扰,Audio-SDS能够提高语音的可懂性和质量,为用户带来更好的语音交互体验。
Audio-SDS的技术解析
Audio-SDS的技术核心在于其巧妙地结合了预训练音频扩散模型、文本条件引导和分数蒸馏采样(SDS)等技术:
预训练音频扩散模型:Audio-SDS以预训练的音频扩散模型为基础,这些模型经过大量数据的训练,已经具备了生成高质量音频样本的能力,并蕴含了丰富的音频先验知识。这些先验知识为Audio-SDS提供了强大的基础,使其能够生成更逼真、更自然的声音。
文本条件引导:Audio-SDS通过文本提示来引导音频的生成过程。文本提示被编码为条件向量,用于指导音频扩散模型生成符合描述的音频。这意味着用户可以通过简单的文本描述来控制音频的生成,实现高度定制化的音频创作。
分数蒸馏采样(SDS):在音频生成过程中,SDS通过计算生成音频与目标音频之间的差异,优化模型参数,使生成音频更接近目标音频。具体来说,SDS通过以下步骤实现:
- 噪声添加:在音频样本上添加随机噪声,生成噪声音频。这一步骤的目的是为了模拟音频在传输过程中可能受到的干扰,使模型能够更好地处理各种复杂的音频环境。
- 损失计算:计算噪声音频与真实音频之间的差异,并通过梯度下降法优化参数,使预测噪声与真实噪声之间的差异最小化。这一步骤是SDS的核心,通过不断优化模型参数,使生成音频逐渐接近目标音频。
- 优化目标:SDS的损失函数基于扩散模型的概率密度分布,通过最小化噪声分布与真实分布之间的KL散度来优化参数。KL散度是一种衡量两个概率分布差异的指标,通过最小化KL散度,可以使生成音频的概率分布更接近真实音频的概率分布,从而提高生成音频的质量。
多功能扩展:Audio-SDS无需重新训练模型,即可将预训练的音频扩散模型转化为多功能工具,适用于音效生成、音源分离、FM合成及语音增强等多种任务。这种多功能性使得Audio-SDS成为一个强大的音频处理平台,可以满足不同用户的需求。
高效推理:优化后的SDS算法在保持高质量输出的同时,降低了计算复杂度,提升了实时应用的可行性。这意味着Audio-SDS可以在各种设备上运行,并能够实时生成音频,为用户提供更流畅的体验。
Audio-SDS的应用前景
Audio-SDS的应用场景非常广泛,几乎涵盖了所有与音频相关的领域:
音效设计:Audio-SDS能够根据文本提示生成各种逼真的环境音效或创意音效,如爆炸声、风声、雨声等,为电影、游戏和虚拟现实(VR)应用提供沉浸式的音效设计,提升用户体验。想象一下,游戏开发者可以通过简单的文本描述,快速生成各种逼真的音效,而无需花费大量时间和精力进行录制和编辑。
音乐制作:在音乐制作和视频后期处理中,Audio-SDS可以从混合音频中精准提取目标音轨,例如将人声与伴奏分离,方便音乐制作人进行混音或创作新的音乐作品。这为音乐制作人提供了更大的创作空间,可以更自由地调整和组合不同的音轨。
音频编辑:Audio-SDS为音乐制作人和内容创作者提供高效工具,降低专业音频处理的门槛。创作者可以通过简单的文本描述生成高质量音频内容,无需复杂的音频编辑技能。这意味着即使是没有专业音频知识的人,也可以轻松地创作出高质量的音频内容。
音乐教育:提取清唱音轨可以用于制作卡拉OK伴奏,也有助于音乐教育中的扒谱和学习。这为音乐学习者提供了更便捷的工具,可以更轻松地学习和练习音乐。
智能家居:Audio-SDS可以自动识别家庭环境中的各种声音,如婴儿哭声、水龙头漏水等,提升生活智能化水平。这为智能家居系统提供了更强大的感知能力,可以更好地为用户提供服务。
Audio-SDS的局限性与未来发展
尽管Audio-SDS具有诸多优势,但仍存在一些局限性。例如,对于某些非常复杂或抽象的文本描述,Audio-SDS可能难以生成完全符合要求的音频。此外,Audio-SDS的计算复杂度仍然较高,需要进一步优化以满足实时应用的需求。
未来,Audio-SDS的发展方向可能包括:
- 提高生成音频的质量和多样性:通过引入更先进的深度学习技术,提高Audio-SDS生成音频的质量和多样性,使其能够更好地满足不同用户的需求。
- 降低计算复杂度:优化SDS算法,降低Audio-SDS的计算复杂度,使其能够在各种设备上运行,并能够实时生成音频。
- 扩展应用场景:将Audio-SDS应用于更多的领域,如医疗、教育等,为这些领域提供更智能、更高效的音频处理解决方案。
结论
NVIDIA的Audio-SDS技术代表了音频处理领域的一次重大突破。它不仅能够生成高质量的音频,还能够根据文本提示进行定制化的音频创作,为音频内容创作者提供了强大的工具。随着技术的不断发展,Audio-SDS有望在未来发挥更大的作用,为我们的生活带来更多惊喜。








