
在人工智能领域,文字转语音(TTS)技术一直备受关注。近日,Stability AI开源了一款名为“Adversarial Post-Training Accelerated Fast Text-to-Audio Generation”的超轻量级TTS模型,引起了业界的广泛关注。这款模型以其超快的速度和轻量级的特点,为移动设备上的实时音频生成应用带来了新的可能性。
这款模型最引人注目的特点是其仅有341M的参数量。相比于动辄数十亿甚至上千亿参数的传统TTS模型,这款模型堪称“苗条”。然而,它却能在保证音频质量的同时,实现惊人的生成速度。这主要归功于Stability AI所采用的一系列创新技术。
ARC后训练:超越蒸馏的加速方法
为了提高模型的生成速度,研究人员通常会采用“蒸馏”技术,即利用一个大型模型(教师)来指导小型模型(学生)的学习。然而,这种方法存在训练成本高或需要存储大量“作业”的问题。Stability AI提出了一种名为ARC(Adversarial Relativistic-Contrastive)后训练的新方法,它是一种对抗性加速算法,不依赖于蒸馏技术,而是通过在训练后对模型进行优化,使其在保持性能的同时变得更快。
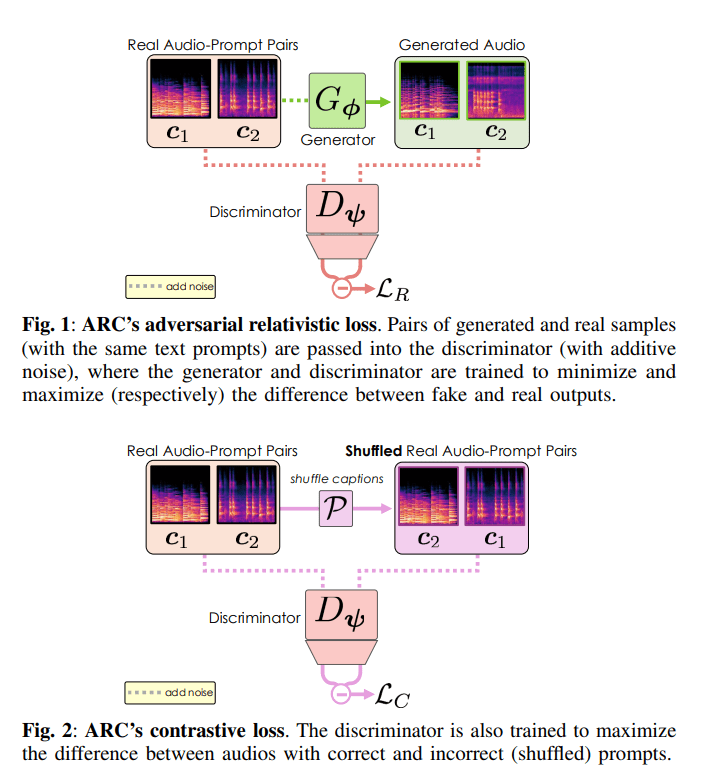
相对抗性损失:提升音频质量
ARC后训练的核心是“对抗性相对损失”。传统的对抗网络(GAN)通过生成器和判别器之间的博弈来提高生成样本的逼真度。而相对抗性损失则更进一步,它要求生成器不仅要生成逼真的样本,还要让生成的样本比真实样本更“真”。同时,判别器则要让真实样本比生成的样本更“真”。这种“以假乱真”的博弈促使生成器不断提高生成音频的质量。
更重要的是,由于该模型是文字转语音模型,研究人员可以直接利用相同文字描述的真实音频和生成音频进行对比,从而为模型提供更强的训练信号。这种方法有效地提高了生成音频的逼真度。
对比损失:增强语义理解
除了生成逼真的音频外,TTS模型还需要能够理解文字的含义,并生成符合文字描述的声音。为了解决传统对抗性训练可能忽略文字信息的问题,ARC后训练还加入了“对比损失”。
对比损失通过训练判别器来区分带有正确文字描述的音频和带有错误文字描述的音频。判别器会努力让正确配对的音频和文字之间的距离更近,而错误配对的距离更远。这使得判别器能够更好地理解文字的含义,从而指导生成器生成更符合文字描述的音频。此外,这种方法还可以避免使用CFG(Classifier-Free Guidance),从而在提高文本一致性的同时,避免牺牲生成的多样性。
乒乓采样:加速音频生成
传统的扩散模型生成音频需要经过多个步骤的去噪过程。为了加速音频生成,这款模型采用了“乒乓采样”技术。乒乓采样不是简单地一步去噪到底,而是在去噪和加噪之间来回切换,类似于打乒乓球。通过在不同噪声水平之间来回“击打”,每次击打都能使生成的音频更接近真实,从而在更少的步骤内达到更好的效果。
架构优化:打造轻量级模型
除了创新的训练方法外,该模型还对自身的架构进行了优化。研究人员在Stable Audio Open(SAO)的基础上,对模型的“零部件”进行了小型化和高效化处理。例如,他们减少了Diffusion Transformer(DiT)的维度和层数,并加入了一些新技术来提高模型的稳定性。这些优化使得模型的参数数量大大减少,同时又不牺牲性能。
性能表现:速度与质量并存
通过上述一系列创新技术,这款模型在速度和质量上都取得了显著的提升。在专业的H100 GPU上,它可以在大约75毫秒内生成12秒的44.1kHz立体声音频,比原始的SAO模型快了100倍。更令人印象深刻的是,经过专门针对移动设备的优化,该模型在手机CPU上也能在大约7秒内生成12秒的音频。这使得它成为目前最快的手机端文字转语音模型之一。
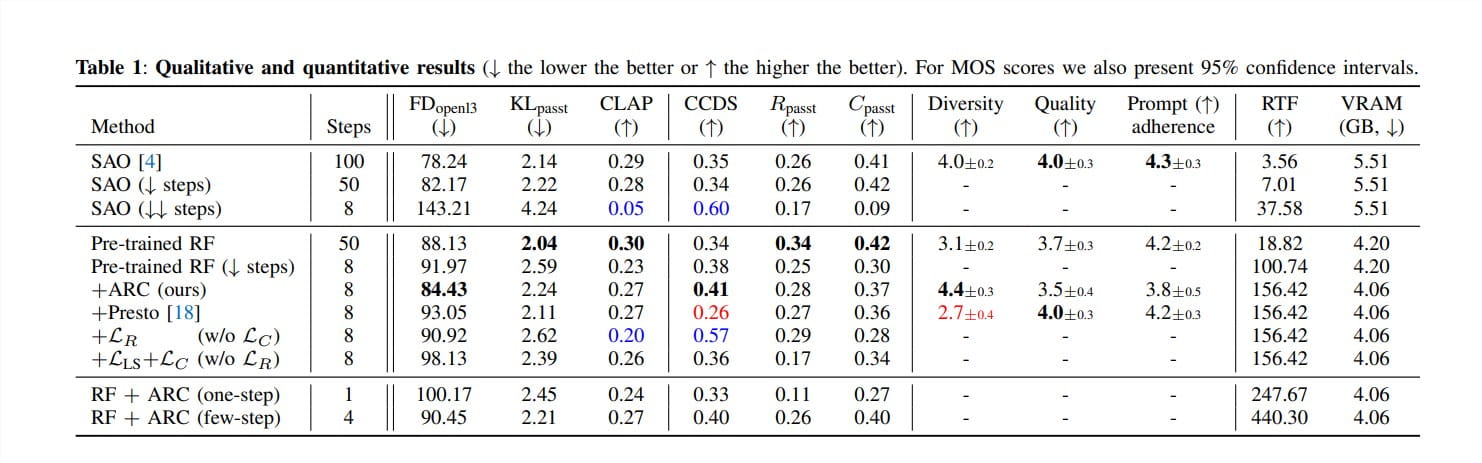
更重要的是,该模型在保证速度的同时,并没有明显牺牲音频质量。论文中提供的各种专业音频评估指标表明,它的音频质量可以与那些更大的、更慢的模型相媲美。
多样性生成:激发创作灵感
许多加速模型为了追求速度,往往会牺牲生成结果的多样性,导致生成的声音听起来千篇一律。然而,这款模型不仅速度快,而且生成的声音多样性更高。为了衡量模型在给定相同文字描述下生成不同声音的能力,研究人员提出了一个新的评估指标CCDS(CLAP Conditional Diversity Score)。实验结果表明,该模型在CCDS上的得分很高,并且通过主观听力测试也证实了其生成声音的多样性和创意性。
这意味着,当用户输入一段文字时,该模型可以生成多种不同风格、不同感觉的声音,从而大大激发用户的创作灵感。
音频转音频:玩转声音风格
除了文字转语音外,这款模型还具备一项隐藏技能——音频转音频。用户可以输入一段音频作为参考,然后用文字描述想要的声音风格,模型就能将输入的音频转换成新的风格。例如,用户可以输入一段自己的说话声,然后用文字描述“变成机器人的声音”,模型就能生成一段机器人版的说话声。这种声音界的“风格迁移”功能为用户提供了更多的创作可能性,而且无需额外的训练即可使用。
应用前景:移动端的“声音魔法师”
这款超快、超轻、高质量的TTS模型为文字转语音技术的落地应用打开了新的大门。尤其是在移动设备上,以前受限于算力,很难运行复杂的音频生成模型。现在,有了这款模型,用户的手机可以变身为一个强大的“声音魔法师”,随时随地生成各种创意音频。
用户可以在手机上实时为视频配音,为游戏生成独特的音效,或者仅仅是玩转各种有趣的声音效果。而且,由于该模型对文字描述的理解能力强,用户可以更精准地控制生成的声音。
当然,目前该模型还有一些需要改进的地方,例如它对内存和存储空间还有一定的要求。但总体而言,Stability AI已经迈出了关键的一步,让高性能的文字转语音技术真正走进了寻常百姓家。
总而言之,Stability AI开源的这款341M超轻量文字转语音模型,通过创新的ARC后训练方法,实现了令人惊叹的速度和多样性,同时保持了高质量的音频输出。它的轻量化设计和在移动设备上的出色表现,预示着文字转语音技术将在更多创意应用中大放异彩。未来,我们可以期待这款模型在更多场景下大显身手,让我们的世界变得更加“声”动有趣。








