
在人工智能领域,Hugging Face 再次引领创新,推出了 SmolVLM。这项技术利用 WebGPU,无需服务器支持,直接在用户的浏览器中实现实时摄像头图像识别。所有计算都在本地设备上完成,既保护了用户隐私,又大大降低了 AI 应用的部署门槛。本文将深入探讨 SmolVLM 的本地实时演示及其对 AI 生态系统的影响。
WebGPU:赋能本地 AI 推理的核心
SmolVLM 是一种超轻量级多模态模型,其参数规模在 256M 到 500M 之间,专为边缘设备优化。其最新演示利用 WebGPU,这是一种现代浏览器 GPU 加速标准,使模型能够在浏览器中直接运行图像处理任务。用户只需访问 Hugging Face 提供的在线演示页面,授权摄像头,即可立即捕获图像。SmolVLM 将实时生成图像描述或回答相关问题,例如“这张照片里有什么?”或“这是什么物体?”
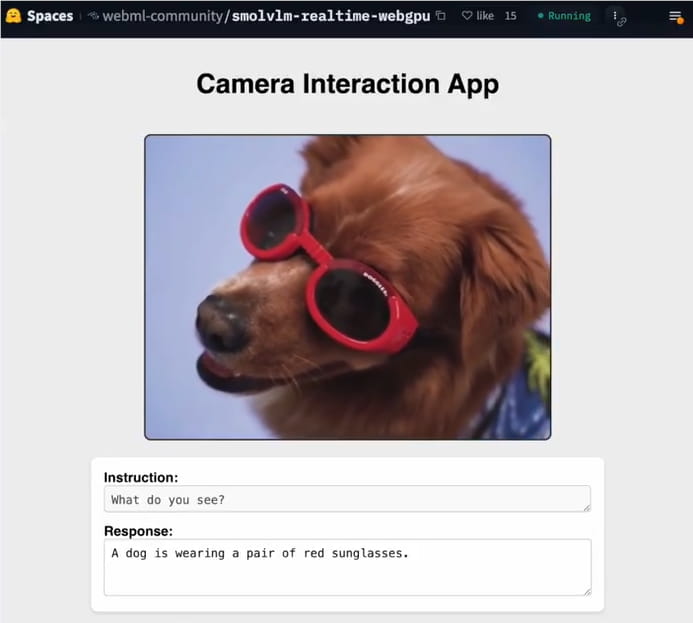
SmolVLM 的推理过程完全本地化,无需将数据传输到云端,从而确保用户隐私。在支持 WebGPU 的浏览器(如 Chrome 113+ 或 Safari Technology Preview)上,500M 模型运行流畅,处理单张图像的延迟低至 0.5 秒,即使在普通笔记本电脑上也能实现实时响应。
演示亮点:简单易用,性能强大
SmolVLM 的实时摄像头演示因其易用性和高性能而备受关注。用户只需打开指定的网页(如 Hugging Face Spaces 的 SmolVLM-256M-Instruct-WebGPU 演示),无需安装任何软件,即可体验 AI 对摄像头馈送的实时分析。该演示支持多种任务,包括图像描述、对象识别和视觉问题回答,例如识别雕像中的精细物体(如剑)或描述复杂场景。
为了优化性能,SmolVLM 支持 4/8 位量化(如 bitsandbytes 或 Quanto 库),从而最大限度地减少模型内存使用。开发人员可以通过调整输入图像分辨率来进一步提高推理速度。这种轻量级设计使 SmolVLM 特别适用于资源受限的设备,如智能手机或低端 PC,展示了多模态 AI 的包容性潜力。
技术细节:SmolVLM 与 WebGPU 的协同作用
SmolVLM 的成功归功于其与 WebGPU 的深度集成。WebGPU 通过浏览器访问设备 GPU,支持高效的并行计算,使其比 WebGL 更适合机器学习任务。SmolVLM-256M 和 500M 模型使用 Transformers.js 库,并通过 WebGPU 加速图像和文本处理,接受任意图像-文本序列输入,适用于聊天机器人、视觉助手和教育工具。
值得注意的是,WebGPU 的普及仍需时日。例如,Firefox 和稳定版本的 Safari 尚未默认启用 WebGPU,Android 设备的支持也不够全面。因此,开发人员需要确保浏览器兼容性,或使用 Safari Technology Preview 以获得最佳体验。
社区反响:开源生态系统的又一里程碑
SmolVLM 的实时演示迅速激发了开发者社区的热情。其 GitHub 仓库(ngxson/smolvlm-realtime-webcam)在发布后两天内获得了超过 2000 个 star,反映了社区对其可移植性和创新性的高度认可。Hugging Face 还提供了详细的开源代码和文档,使开发人员能够基于 llama.cpp 服务器或 Transformers.js 定制应用。
一些开发人员已经尝试将 SmolVLM 扩展到更多场景,例如 AI 姿势纠正和批量图像处理,进一步验证了其灵活性。SmolVLM 的开源特性和低硬件要求将加速多模态 AI 在教育、医疗保健和创意领域的普及。
行业意义:本地 AI 隐私和效率的革命
SmolVLM 的本地实时演示展示了边缘 AI 的巨大潜力。与依赖云的传统多模态模型(如 GPT-4o)相比,SmolVLM 通过 WebGPU 实现零数据传输,为医疗图像分析或个人设备助手等隐私敏感场景提供了理想的解决方案。随着 WebGPU 在 2025 年继续普及,SmolVLM 等轻量级模型将成为本地 AI 应用的主流。
SmolVLM 的成功凸显了 Hugging Face 在开源 AI 生态系统中的领导地位。它与 Qwen3 等原生模型的潜在兼容性也为中国开发者提供了更多本地化开发的机会。期待看到更多模型加入 WebGPU 生态系统,共同推动 AI 的普及。
多模态 AI 的轻量级未来
SmolVLM 的实时摄像头演示不仅是一项技术突破,也是本地 AI 的一个里程碑。其轻量级设计与 WebGPU 相结合,使开发人员能够在无需复杂配置的情况下部署多模态 AI,真正实现了“打开网页即可使用”的愿景。








