
近年来,随着人工智能技术的飞速发展,动态肖像生成领域取得了显著的进步。由复旦大学和腾讯优图实验室联合推出的DICE-Talk框架,正是这一领域的最新成果。它不仅能够生成具有生动情感表达的动态肖像视频,还能保持人物身份的一致性,为数字人、虚拟助手等应用场景带来了全新的可能性。
DICE-Talk框架的核心在于其独特的情感关联增强模块和情感判别目标设计。情感关联增强模块通过学习不同情感之间的关系,提升了情感生成的准确性和多样性。而情感判别目标则确保了生成过程中情感的一致性,避免了情感漂移或失真。在MEAD和HDTF数据集上的实验结果表明,DICE-Talk在情感准确性、对口型和视觉质量等方面均优于现有的技术。
DICE-Talk的功能特点
DICE-Talk框架具备以下几项主要功能特点:
情感化动态肖像生成
DICE-Talk能够根据输入的音频和参考图像,生成具有特定情感表达的动态肖像视频。这意味着我们可以让虚拟人物根据语音内容和情感需求,展现出喜怒哀乐等各种情绪,从而使其更加生动和自然。
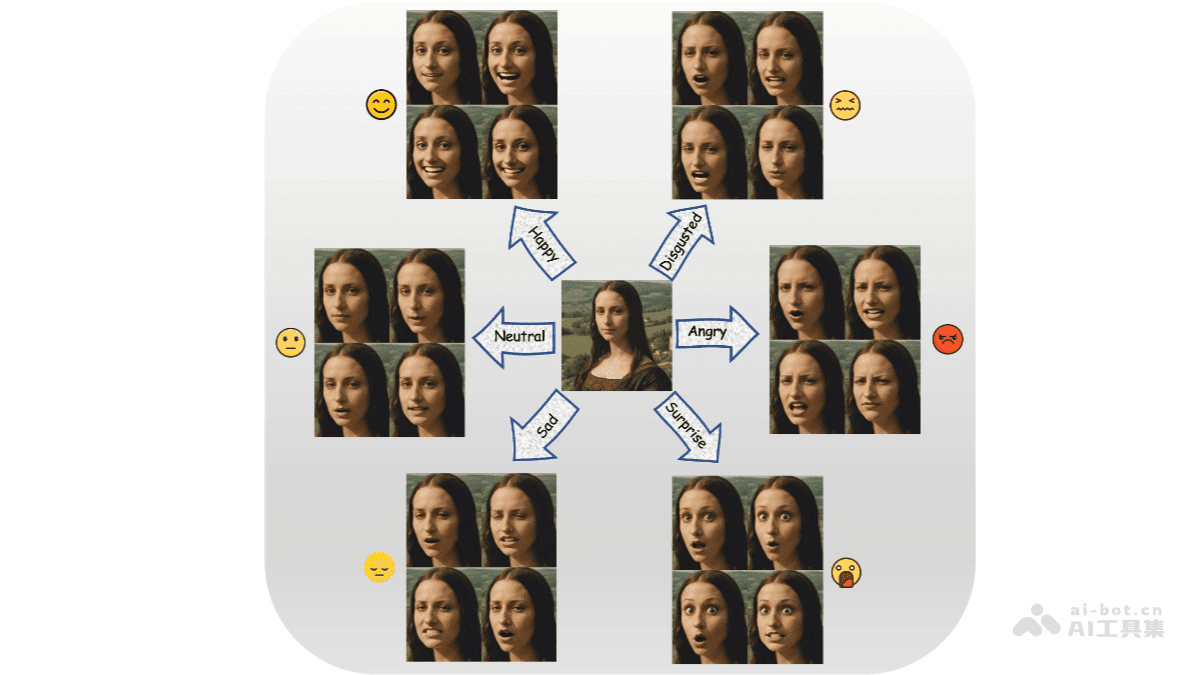
身份保持
在生成情感化视频的同时,DICE-Talk能够保持输入参考图像的身份特征。这对于需要保持人物形象一致性的应用场景至关重要,例如数字代言人、虚拟客服等。通过DICE-Talk,我们可以确保虚拟人物在表达不同情感时,始终保持其独特的面部特征和身份信息。
高质量视频生成
DICE-Talk生成的视频在视觉质量、唇部同步和情感表达方面均达到了较高的水平。这意味着我们可以获得更加逼真和自然的动态肖像视频,从而提升用户体验。高质量的视频生成能力是DICE-Talk在众多同类框架中脱颖而出的关键因素之一。
泛化能力
DICE-Talk具备良好的泛化能力,能够适应未见过的身份和情感组合。这意味着我们可以使用DICE-Talk生成各种各样的人物和情感表达,而无需针对每一种情况进行单独的训练。这种泛化能力大大提高了DICE-Talk的实用性和灵活性。
用户控制
DICE-Talk允许用户输入特定的情感目标,从而控制生成视频的情感表达。这种高度的用户自定义能力使得DICE-Talk能够满足各种不同的应用需求。例如,我们可以通过指定情感目标来生成表达特定情绪的教学视频、宣传片等。
多模态输入
DICE-Talk支持多种输入模态,包括音频、视频和参考图像。这意味着我们可以使用各种不同的输入方式来生成动态肖像视频,从而满足不同的应用场景需求。例如,我们可以使用一段音频和一张参考图像来生成一段虚拟人物的讲话视频,也可以使用一段视频来驱动虚拟人物的情感表达。
DICE-Talk的技术原理
DICE-Talk框架的技术原理主要包括以下几个方面:
解耦身份与情感
DICE-Talk基于跨模态注意力机制联合建模音频和视觉情感线索,将情感表示为身份无关的高斯分布。这种解耦的设计使得DICE-Talk能够更好地控制生成视频的情感表达,并保持人物身份的一致性。通过对比学习(如InfoNCE损失)训练情感嵌入器,确保相同情感的特征在嵌入空间中聚集,不同情感的特征则分散,从而提高了情感表达的准确性和可控性。
情感关联增强
情感库是DICE-Talk中一个可学习的模块,用于存储多种情感的特征表示。通过向量量化和基于注意力的特征聚合,DICE-Talk能够学习情感之间的关系,从而更好地生成各种情感表达。情感库存储单一情感的特征,学习情感之间的关联,帮助模型更好地生成其他情感。这种情感关联增强的设计使得DICE-Talk能够生成更加自然和流畅的情感表达。
情感判别目标
在扩散模型的生成过程中,DICE-Talk基于情感判别器确保生成视频的情感一致性。情感判别器与扩散模型联合训练,确保生成的视频在情感表达上与目标情感一致,保持视觉质量和唇部同步。这种情感判别目标的设计有效地避免了情感漂移和失真,提高了生成视频的情感准确性。
扩散模型框架
DICE-Talk采用了扩散模型框架,从高斯噪声开始,逐步去噪生成目标视频。基于变分自编码器(VAE)将视频帧映射到潜在空间,在潜在空间中逐步引入高斯噪声,基于扩散模型逐步去除噪声,生成目标视频。在去噪过程中,扩散模型基于跨模态注意力机制,结合参考图像、音频特征和情感特征,引导视频生成。这种扩散模型框架使得DICE-Talk能够生成高质量、高逼真度的动态肖像视频。
DICE-Talk的应用场景
DICE-Talk框架具有广泛的应用前景,以下是一些典型的应用场景:
数字人与虚拟助手
DICE-Talk可以为数字人和虚拟助手赋予丰富的情感表达,使其在与用户交互时更加自然和生动,从而提升用户体验。例如,我们可以使用DICE-Talk创建一个具有喜怒哀乐等各种情感表达的虚拟客服,从而更好地服务用户。
影视制作
在影视特效和动画制作中,DICE-Talk可以快速生成具有特定情感的动态肖像,提高制作效率,降低制作成本。例如,我们可以使用DICE-Talk生成电影中角色的面部表情,从而减少演员的表演负担。
虚拟现实与增强现实
在VR/AR应用中,DICE-Talk可以生成与用户情感互动的虚拟角色,增强沉浸感和情感共鸣。例如,我们可以使用DICE-Talk创建一个能够根据用户的情绪变化而做出相应反应的虚拟伙伴。
在线教育与培训
DICE-Talk可以创建具有情感反馈的教学视频,让学习内容更加生动有趣,提高学习效果。例如,我们可以使用DICE-Talk创建一个能够根据学生的学习进度和情绪状态调整教学内容的虚拟老师。
心理健康支持
DICE-Talk可以开发情感化虚拟角色,用于心理治疗和情感支持,帮助用户更好地表达和理解情感。例如,我们可以使用DICE-Talk创建一个能够倾听用户心声并给予鼓励的虚拟心理咨询师。
DICE-Talk的未来展望
随着人工智能技术的不断发展,DICE-Talk框架也将不断完善和发展。未来,我们可以期待DICE-Talk在以下几个方面取得更大的突破:
- 更高的情感表达精度:通过引入更先进的情感识别和生成技术,DICE-Talk可以实现更精确、更细腻的情感表达,从而使虚拟人物的情感更加逼真和自然。
- 更强的多模态融合能力:通过融合更多的输入模态,例如文本、肢体语言等,DICE-Talk可以生成更加丰富、更加全面的情感表达,从而使虚拟人物的情感更加具有感染力。
- 更广泛的应用场景:随着DICE-Talk技术的不断成熟,其应用场景将不断拓展,例如游戏、社交、娱乐等领域,为人们的生活带来更多的乐趣和便利。
总而言之,DICE-Talk作为一种新颖的情感化动态肖像生成框架,具有广阔的应用前景和巨大的发展潜力。它的出现,为数字人、虚拟助手等应用场景带来了全新的可能性,也为人工智能技术的发展注入了新的活力。








