
在人工智能技术日新月异的今天,各行各业都在积极探索AI赋能的新模式。2025年5月12日,AI领域再次迎来一系列重大进展,从快手推出AI作图工具Poify,到字节跳动开源代码模型Seed-Coder,再到谷歌Gemini2.5Pro在视频理解上的突破,每一项技术都预示着AI应用更加广阔的前景。
快手Poify:电商领域的AI图像革命
快手推出的AI作图工具Poify,精准定位于电商市场,无疑是看到了电商领域对图像处理的迫切需求。Poify的核心功能包括文生图和图生图,这意味着商家只需要输入简单的文字描述,或者提供一张基础图片,Poify就能自动生成高质量的商品展示图。更令人兴奋的是,Poify还具备AI模特试衣、背景更换等创新能力,这些功能对于降低电商商家的运营成本,提升商品的视觉吸引力具有重要意义。
在传统电商运营中,商品展示图的拍摄需要投入大量的人力、物力和时间。而Poify的出现,无疑将大大简化这一流程。商家不再需要聘请专业的摄影团队,也不需要搭建复杂的拍摄场景,只需要利用Poify的AI能力,就能轻松生成各种风格的商品展示图。这不仅降低了成本,还提高了效率,让商家能够将更多精力投入到产品研发和市场推广上。
快手此举,无疑是希望通过Poify抢占电商与AI融合的先机,推动整个电商行业向智能化转型。随着越来越多的商家开始使用Poify,电商领域的图像处理方式将迎来一场深刻的变革。
字节跳动Seed-Coder:开源代码模型的里程碑
字节跳动Seed团队开源的Seed-Coder代码模型,拥有8B参数和强大的代码生成与推理能力,无疑是AI领域的一颗重磅炸弹。Seed-Coder在多个基准测试中表现优异,这证明了其在代码生成和软件工程任务上的卓越能力。更重要的是,Seed-Coder的开源,将为广大的开发者和研究者提供一个强大的工具,促进AI在编程领域的创新应用。
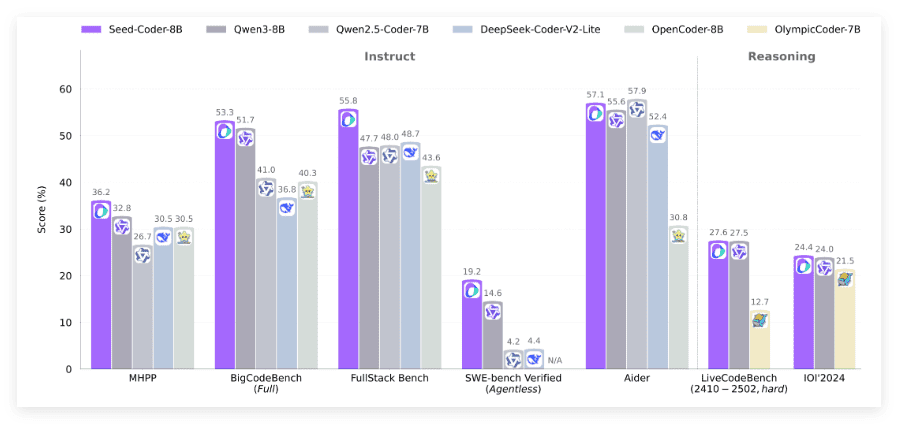
Seed-Coder的创新之处在于其数据处理方式和训练策略。通过小型语言模型自动策划和过滤代码数据,Seed-Coder能够大幅减少人工干预,提升数据筛选效率。这种高效的数据处理方式,不仅提升了代码生成质量,也为未来的AI驱动数据处理提供了新的思路。可以预见,随着Seed-Coder的不断发展和完善,它将成为轻量级编程模型的佼佼者,为软件开发带来革命性的变革。
DeepSeek App入选年度十大IP:AI的文化价值
2025年度十大IP的评选结果揭晓,DeepSeek App等作品成功入选。这不仅是对DeepSeek App在技术创新上的肯定,更是对其文化价值的认可。在众多参赛作品中,《哪吒之魔童闹海》等优秀作品脱颖而出,展示了中国文化创意的多样性。DeepSeek App的入选,也意味着AI正在逐渐融入人们的日常生活,成为文化创意产业的重要组成部分。
本次博览会吸引了2368个参赛IP,经过专家评审和网络投票,最终确定了十个优秀作品。这一评选过程,不仅是对参赛作品的一次全面检验,也是对整个文化创意产业的一次推动。随着AI技术的不断发展,我们有理由相信,未来将有更多优秀的AI作品涌现出来,为人们带来更加丰富多彩的文化体验。
Claude AI API:网页搜索赋能AI智能体
Anthropic最新推出的Claude AI API引入了网页搜索功能,这使得Claude能够实时访问网络信息,极大地提升了其回答问题的准确性。这一创新,无疑将为传统搜索引擎带来巨大的竞争压力。开发者可以利用Claude的这一功能,构建更加精准的智能体,应用于金融、法律、开发者工具和生产力等多个领域。

在信息爆炸的时代,如何快速、准确地获取信息,成为人们面临的一大挑战。Claude AI API的网页搜索功能,正是为了解决这一问题而生。通过实时访问网络信息,Claude能够为用户提供最新、最全面的答案,帮助用户更好地理解和解决问题。可以预见,随着Claude AI API的不断完善和推广,它将成为各行各业的重要工具,推动AI智能体的广泛应用。
苹果FastVLM:移动端的视觉语言模型革命
苹果发布的FastVLM模型,是一款专为高分辨率图像处理优化的视觉语言模型,具有极高的编码速度和卓越的性能,特别适合在移动设备上运行。FastVLM的核心是其创新的FastViTHD编码器,通过动态分辨率调整和层次化令牌压缩等技术,显著提升了效率。
FastVLM的出现,意味着我们可以在手机上运行更加强大的视觉语言模型,实现更加智能的图像处理和分析。这对于移动互联网的发展具有重要意义。例如,我们可以利用FastVLM实现更加智能的图像搜索、图像编辑和图像识别等功能,为用户带来更加便捷、高效的移动体验。
腾讯PrimitiveAnything:3D形状生成的颠覆者
腾讯与清华大学合作推出的PrimitiveAnything框架,旨在重新定义3D形状的抽象与生成。通过将复杂形状分解为原始组件,PrimitiveAnything不仅提升了几何准确性,还增强了学习效率。其自动回归生成方式和大规模的HumanPrim数据集,验证了该框架在重构准确性和与人类抽象模式一致性方面的优越性。

PrimitiveAnything的出现,为3D建模领域带来了革命性的变革。传统的3D建模需要专业的设计师和复杂的软件,而PrimitiveAnything则可以通过简单的操作,自动生成高质量的3D模型。这无疑将大大降低3D建模的门槛,让更多的人能够参与到3D内容的创作中来。
智能文档处理基准IDP Leaderboard:多模态AI的现实挑战
首个智能文档处理基准IDP Leaderboard的推出,为视觉-语言模型的发展提供了一个重要的参考。该基准通过对9229份文档和16个数据集的评估,全面分析了当前主流模型在多个核心任务上的表现。尽管Gemini2.5Flash在综合实力上表现突出,但在OCR和分类任务中却出现了意外的下滑,显示出多模态推理能力与基础文本识别功能之间的权衡问题。
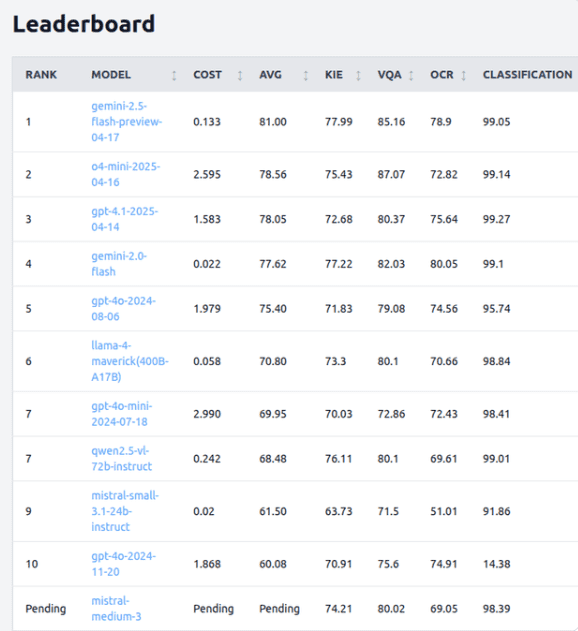
IDP Leaderboard的推出,让我们更加清晰地认识到,多模态AI在实际应用中仍然面临着许多挑战。长文档处理和表格提取等任务,仍然是视觉-语言模型的短板。我们需要不断努力,提升模型在这些方面的能力,才能真正实现多模态AI的广泛应用。
谷歌Gemini2.5Pro:6小时视频理解的突破
谷歌的Gemini2.5Pro模型在视频理解领域取得了重大突破,支持长达6小时的视频分析和高达200万Token的上下文窗口。通过API解析YouTube链接,Gemini2.5Pro在VideoMME基准测试中表现出色,准确率接近行业顶尖水平。
Gemini2.5Pro的突破,意味着AI在视频理解领域的能力得到了极大的提升。我们可以利用Gemini2.5Pro实现更加智能的视频分析、视频搜索和视频推荐等功能,为用户带来更加丰富、便捷的视频体验。
用户提问方式:影响AI模型准确性的关键
近期研究表明,用户在请求简短回答时,许多语言模型更容易生成错误或误导性的信息。这项研究揭示了简洁请求对模型准确性的负面影响,特别是在用户使用自信措辞时,模型的纠正能力会显著下降。
这一研究提醒我们,在使用AI模型时,需要注意提问的方式。简洁的提问可能会导致模型生成错误的信息,而使用清晰、明确的提问,则有助于提高模型的准确性。
Fellou:全球首款AI智能浏览器
Fellou的发布标志着浏览器的重大变革,成为全球首款具备AI智能自动化功能的浏览器。它不仅能进行传统的搜索和浏览,还能思考、规划并执行复杂任务,大幅提升用户的工作效率。
Fellou的出现,为我们展示了未来浏览器的发展方向。未来的浏览器,不仅仅是一个信息展示的工具,更是一个智能化的助手,能够帮助我们完成各种复杂的任务,提升我们的工作效率。
NVIDIA Audio-SDS:音效生成与多任务音频处理的革新
NVIDIA的Audio-SDS技术通过将Score Distillation Sampling扩展至音频领域,显著提升了音效生成和音源分离能力。该技术支持多任务音频处理,用户可通过文本提示生成定制化音效,降低了开发成本与时间。
Audio-SDS的出现,为音频处理领域带来了新的可能性。我们可以利用Audio-SDS实现更加智能的音效生成、音源分离和音频编辑等功能,为用户带来更加丰富、便捷的音频体验。
Kimi入驻小红书:AI大模型的内容深耕
Kimi与小红书的合作标志着AI大模型在内容平台上的新尝试。虽然目前的入口尚未与小红书的其他功能深度整合,但这次合作显示出Kimi在流量焦虑下的转型策略。未来,Kimi可能会通过内容与社区的结合,增强用户黏性。

Kimi入驻小红书,是AI大模型在内容平台上的一个重要尝试。通过与内容平台的合作,AI大模型可以更好地触达用户,了解用户的需求,从而提供更加个性化、智能化的服务。
总而言之,2025年5月12日,AI领域的各项进展都预示着AI应用更加广阔的前景。从电商领域的图像革命,到开源代码模型的里程碑,再到视频理解和音频处理的突破,AI正在深刻地改变着我们的生活和工作方式。随着技术的不断发展,我们有理由相信,AI将在未来发挥更加重要的作用。








