
在人工智能领域,多模态大型模型正逐渐崭露头角,引领着AI技术的发展方向。近日,由普林斯顿大学、字节跳动、清华大学和北京大学联合推出的MMaDA(Multimodal Deep Abstraction)模型,引起了业界的广泛关注。这款模型旨在赋予AI更深层次的“思考”能力,实现文本、图像乃至复杂推理任务之间的自由转换,其性能据称超越了GPT-4、Gemini和SDXL等知名模型。

当前的多模态模型已经展现出令人印象深刻的能力,例如能够描述图像或根据文本生成图像。然而,MMaDA的研发团队认为,这还远远不够。传统的模型在处理不同模态的数据时,往往需要独立的组件或复杂的混合机制,类似于一个“多功能工具箱”。虽然工具齐全,但在切换工具时可能会显得不够流畅。MMaDA团队的目标是打破这些壁垒,实现AI的真正融合。
MMaDA模型凭借其三项核心创新技术脱颖而出,旨在让AI不仅能够理解,还能够进行“深入思考”。
统一扩散架构:一个模态“盲盒”,无缝处理一切
统一扩散架构是MMaDA的一大亮点。它就像一种超智能的“万能胶”,能够完美地将各种形状和材料的碎片粘合在一起。MMaDA采用这种“万能胶”,即统一扩散架构,该架构具有共享概率公式和模态不可知的特性,这意味着它可以处理文本、图像和其他类型的数据,而无需模态特定的组件。通过这种方式,AI可以无缝地切换和处理不同的数据类型,从而大大提高效率和连贯性。

混合长链思维(CoT)微调:教导AI进行深度思考
众所周知,大型模型可以通过“思维链”(CoT)进行部分“思考”。然而,MMaDA通过其“混合长链思维”微调策略更进一步。它精心设计了一种跨模态的统一CoT格式,迫使AI在文本和视觉领域对齐推理过程。其目的是增强AI在进入最终强化学习阶段之前处理复杂任务的能力,为它提供一种“冷启动”训练,类似于为它配备一本“武术秘籍”,使其在实战之前掌握深度思考技能。
统一强化学习算法UniGRPO:推理与生成并驾齐驱
仅仅思考是不够的;AI还需要“熟能生巧”。MMaDA提出了一种专门为扩散模型设计的统一策略梯度强化学习算法——UniGRPO。通过使用多样化的奖励建模,它巧妙地统一了推理和生成任务的后训练,确保模型性能的持续提升。过去,推理和生成可能需要不同的训练方法,但UniGRPO就像一位“全能教练”,引导AI在“智力竞赛”(推理)和“创意工坊”(生成)中都表现出色。
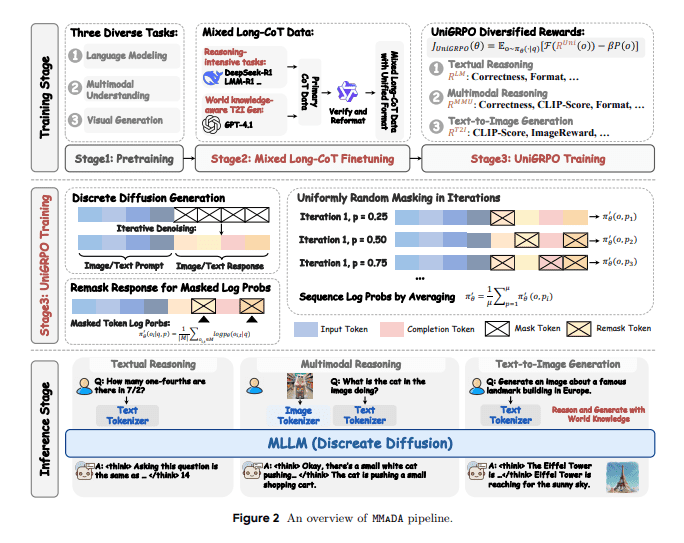
MMaDA的“成就”:全面领先
凭借这三项“黑科技”,MMaDA-8B模型在各种测试中展现出卓越的泛化能力,在多个领域真正脱颖而出:
- 文本推理:超越LLAMA-3-7B和Qwen2-7B!这意味着MMaDA在解决复杂的文本任务中的数学问题和逻辑推理方面表现出比其他模型更强的“智能”。
- 多模态理解:优于Show-o和SEED-X!在理解图像和回答与图像相关的问题时,MMaDA提供更准确和全面的响应。
- 文本到图像生成:超越SDXL和Janus!这绝非小成就;SDXL目前被认为是强大的图像生成器,但MMaDA生成更准确且与世界知识一致的图像,这归功于其强大的文本推理能力。
这些成就突显了MMaDA在弥合统一扩散架构中“预训练”和“后训练”之间差距方面的有效性,为未来的研究和开发提供了一个全面的框架。MMaDA通过统一的扩散架构,实现了跨模态的无缝衔接。这种架构消除了传统模型中模态特定组件的需求,使得模型能够更加灵活高效地处理不同类型的数据。通过混合长链思维微调策略,MMaDA显著提升了AI的深度思考能力,使得模型在推理过程中能够更好地对齐文本和视觉信息。此外,UniGRPO算法的引入,实现了推理和生成任务的统一训练,进一步提高了模型的性能。

深入了解MMaDA的“内部技能”:它是如何实现“七十二变”的?
那么,MMaDA是如何实现如此多的“七十二变”的呢?
- 统一分词: 无论是文本还是图像,MMaDA都使用一致的离散分词策略。这会将所有数据转化为统一的“乐高积木”,使模型能够在统一的掩码令牌预测目标下运行。例如,一个512x512像素的图像将被转换为1024个离散令牌!这就像将不同的模态放在同一个“制服”中!

MMaDA的训练过程就像“在游戏中升级”,分为三个阶段:
- 基础预训练(阶段1): 使用大量的文本和多模态数据为模型奠定坚实的基础。
- 混合长链思维微调(阶段2): 使用精心策划的“长链思维”数据来教导模型推理和思考。这一步对于将模型从“知道”转变为“理解”至关重要!
- UniGRPO强化学习(阶段3): 最后,使用强化学习来不断优化模型在推理和生成任务中的表现,力求卓越。
在推理过程中,MMaDA非常灵活。
- 文本生成使用半自回归去噪策略,产生更复杂和详细的描述。
- 图像生成采用并行非自回归采样,提供更高的效率。这种灵活的组合确保了不同任务的最佳性能。
不仅仅是生成:MMaDA还可以“填补空白”!
MMaDA还有另一项隐藏技能:它自然支持图像修复和外推,而无需额外的微调!这归功于扩散模型的特性,其中这些任务可以被视为“掩码令牌预测”问题,这是MMaDA训练目标的一部分!
这意味着:
- 它可以预测文本序列中缺失的部分。
- 它可以完成视觉问答的答案,给定部分输入和图像。
- 它甚至可以根据不完整的视觉提示修复图像!
这使得AI成为一个能够“想象”视觉效果和“填补空白”的通用助手,从而极大地扩展了其应用场景和泛化能力!通过统一的分词策略,MMaDA能够将文本和图像等不同模态的数据转换为统一的表示形式,从而简化了模型的处理流程。此外,MMaDA还具备图像修复和外推的能力,使其在图像处理方面具有更广泛的应用前景。这些技术特点使得MMaDA在多模态AI领域具有显著的优势。
MMaDA的出现不仅代表了多模态AI技术的新进展,也为未来的AI研究方向提供了新的思路。尽管MMaDA目前仍处于发展阶段,但其所展现出的潜力已经引起了业界的广泛关注。
结论:扩散模型是AI的新范式吗?
MMaDA的诞生无疑是多模态AI领域的一个里程碑。它系统地探索了基于扩散模型的一般基础模型的设计空间,并提出了创新的后训练策略。实验结果表明,MMaDA不仅与专用模型相匹配,甚至在某些方面优于它们,充分展示了扩散模型作为多模态智能的下一代基础范式的巨大潜力!
尽管MMaDA当前的模型大小(8B参数)仍有改进空间,但它的出现无疑为AI领域描绘了一个更宏大和更统一的未来。想象一下,未来的AI不再是单个“专家”的集合,而是一个能够进行深度思考、跨模态理解和无限创造力的“多才多艺的天才”!未来,随着模型规模的不断扩大和算法的持续优化,MMaDA有望在更多领域取得突破性进展,为人类社会带来更大的价值。
MMaDA的成功也离不开背后研究团队的辛勤付出。普林斯顿大学、字节跳动、清华大学和北京大学的科研人员共同努力,克服了诸多技术难题,最终打造出了这款具有里程碑意义的多模态大型模型。他们的研究成果为多模态AI领域的发展注入了新的活力。
总之,MMaDA的出现为我们展示了一个充满希望的未来。我们有理由相信,在不久的将来,多模态AI技术将会在各个领域得到广泛应用,为人类带来更加智能、便捷的生活体验。








