
在信息爆炸的时代,如何高效地从浩如烟海的网络数据中提取关键信息,成为各行各业面临的共同挑战。传统的网络爬虫技术往往需要编写复杂的规则和脚本,维护成本高昂,且难以适应网站结构的快速变化。而ScrapeGraphAI的出现,为我们提供了一种全新的解决方案。它巧妙地融合了大型语言模型(LLM)的强大能力与图逻辑引擎的高效性,实现了智能化的网络数据抓取,极大地简化了数据采集的流程。本文将深入剖析ScrapeGraphAI的技术原理、核心功能、应用场景,以及未来发展趋势,带您领略AI驱动的网络爬虫技术的魅力。
ScrapeGraphAI:AI赋能的网络爬虫新范式
ScrapeGraphAI并非简单的爬虫工具,而是一个基于LLM驱动的智能网络爬虫工具包。它不仅仅能够从各类网站和HTML内容中提取结构化数据,更重要的是,它具备理解用户意图的能力。用户无需编写复杂的代码,只需提供简单的提示,ScrapeGraphAI就能自动分析目标网页的结构,精准地抓取所需信息。这种智能化的数据抓取方式,极大地降低了使用门槛,使得非技术人员也能轻松地进行网络数据采集。
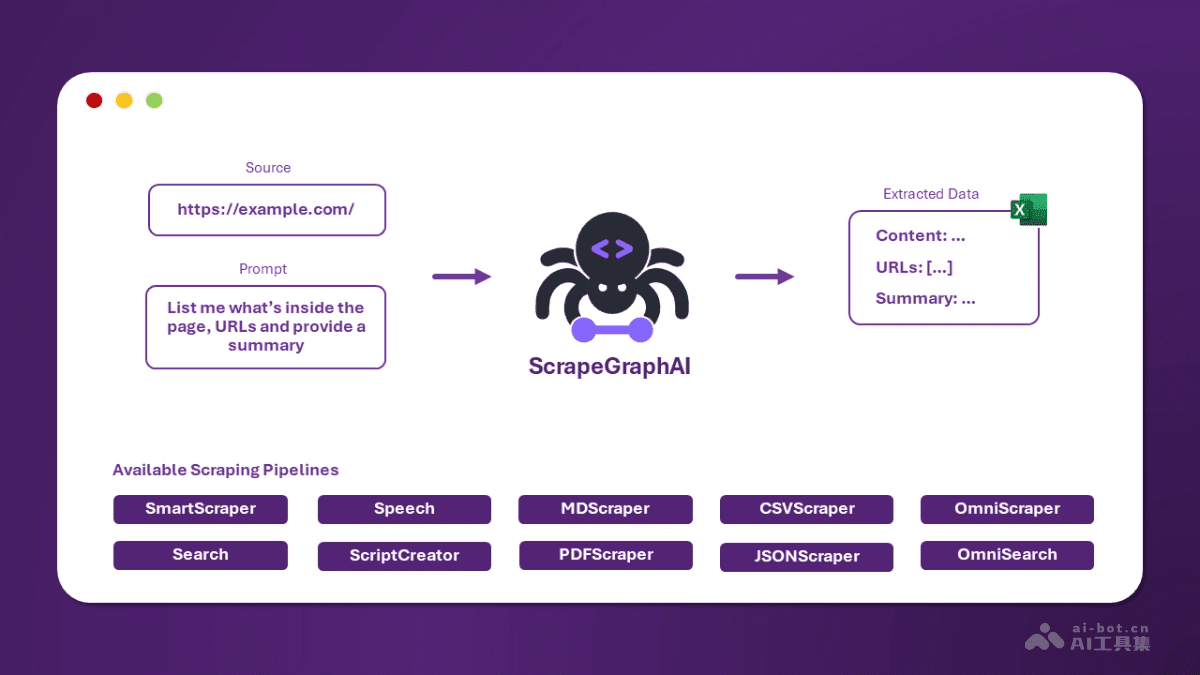
ScrapeGraphAI的核心功能:化繁为简,高效数据采集
ScrapeGraphAI的核心功能可以概括为以下几个方面:
智能单页爬取:用户只需提供简单的提示和网页地址,ScrapeGraphAI就能精准提取所需信息,无需编写复杂规则。例如,用户可以简单地告诉ScrapeGraphAI“提取该网页上的商品名称和价格”,它就能自动识别并提取相关信息,大大节省了人工编写爬虫规则的时间。
多页面搜索爬取:可自动从搜索引擎结果中提取多个页面的相关信息,汇总成统一格式。例如,用户可以要求ScrapeGraphAI从Google搜索结果中提取前10页关于“人工智能”的文章标题和链接,ScrapeGraphAI就能自动完成搜索和数据提取工作。
Markdownify:能将网页内容快速转换为整洁的Markdown格式,便于后续处理和存储。Markdown格式以其简洁、易读的特点,成为内容创作和知识管理的常用格式。ScrapeGraphAI的Markdownify功能,可以将网页内容快速转换为Markdown格式,方便用户进行编辑、整理和存储。
自适应爬取:基于LLM技术,ScrapeGraphAI能自动适应网站结构的变化,大幅降低了对频繁维护和更新的需求。传统的爬虫程序往往需要定期维护,以适应网站结构的调整。而ScrapeGraphAI凭借LLM的强大理解能力,能够自动识别网站结构的变化,并相应地调整爬取策略,大大降低了维护成本。
多模型支持:兼容OpenAI、Groq、Azure、Gemini等云端模型,以及Ollama本地模型,满足不同场景需求。ScrapeGraphAI支持多种LLM模型,用户可以根据自己的需求选择合适的模型。例如,对于需要处理大量文本数据的任务,可以选择性能更强的模型;对于对隐私要求较高的任务,可以选择本地模型。
多平台支持:可以处理XML、HTML、JSON和Markdown等多种文档格式。ScrapeGraphAI支持多种数据格式,可以灵活地处理来自不同来源的数据。这种多平台支持能力,使得ScrapeGraphAI可以应用于更广泛的场景。
格式化输出:自动将爬取结果整理为结构化JSON数据,便于后续处理和分析。JSON格式是一种轻量级的数据交换格式,易于解析和生成。ScrapeGraphAI将爬取结果整理为JSON格式,方便用户进行后续的数据处理和分析,例如数据清洗、数据转换、数据可视化等。
数据存储:支持将提取的数据保存为CSV文件,方便用户进行进一步的数据管理和分析。CSV格式是一种通用的电子表格格式,可以用Excel等软件打开和编辑。ScrapeGraphAI支持将提取的数据保存为CSV文件,方便用户进行进一步的数据管理和分析。
语音生成能力:将网页内容转化为音频文件,方便通勤或其他场景下的内容消费。ScrapeGraphAI可以将网页内容转化为音频文件,用户可以在通勤、运动等场景下收听,充分利用碎片时间。
代码生成器:AI可以自动生成可直接运行的Python或Node.js爬虫代码,方便开发者集成到自己的应用或流程中。ScrapeGraphAI的代码生成器功能,可以根据用户的需求自动生成Python或Node.js爬虫代码,方便开发者将ScrapeGraphAI集成到自己的应用或流程中。
ScrapeGraphAI的技术原理:LLM与图逻辑引擎的完美结合
ScrapeGraphAI之所以能够实现如此强大的功能,离不开其独特的技术原理:
自然语言驱动:ScrapeGraphAI 支持用户通过简单的自然语言指令来描述需要提取的信息。这种自然语言驱动的方式,极大地降低了使用门槛,使得非技术人员也能轻松地使用ScrapeGraphAI。
图逻辑引擎:ScrapeGraphAI 将爬取过程建模为有向图(Directed Graph),图中的节点代表不同的操作或数据处理步骤,如请求发送、HTML解析、数据提取等。通过图逻辑引擎,爬取任务被分解为多个离散的节点,每个节点负责特定的任务,节点之间通过边连接,形成清晰的数据流动方向。这种图逻辑引擎的设计,使得爬取过程更加清晰、可控,便于并行处理和错误隔离,使整个爬取过程更加可解释和可视化。
LLM 的智能解析:ScrapeGraphAI 基于 LLM 的强大语义理解能力,自动解析用户的自然语言指令。LLM 能理解用户的需求,动态生成相应的爬取逻辑。这种智能解析能力,使得 ScrapeGraphAI 能自动适应网站结构的变化,网页布局发生改变,也能准确提取关键信息。LLM 可以理解用户的意图,并将其转化为具体的爬取策略,从而实现智能化的数据抓取。
ScrapeGraphAI的应用场景:赋能各行各业,释放数据价值
ScrapeGraphAI的应用场景非常广泛,几乎可以应用于所有需要从网络上获取数据的领域:
市场趋势分析:定期自动抓取网站上的价格趋势、股票数据等,进行实时监控与分析,帮助用户把握市场动态,为投资决策提供依据。例如,投资者可以使用ScrapeGraphAI定期抓取股票论坛上的评论数据,分析市场情绪,从而辅助投资决策。
学术研究:从在线资源中抓取相关文献信息,为学术研究提供丰富的数据资源,助力研究人员深入了解特定领域的最新进展。研究人员可以使用ScrapeGraphAI从学术数据库中抓取论文信息,构建自己的研究数据库,从而提高研究效率。
产品信息收集:自动抓取电商网站的产品名称、描述、评论等信息,用于产品分析、市场调研或构建产品数据库。电商企业可以使用ScrapeGraphAI抓取竞争对手的产品信息,进行竞品分析,从而优化自己的产品策略。
内容聚合:自动从多种数据源中抓取和整理信息,用于内容聚合平台或知识库,丰富平台内容,提升用户体验。新闻聚合平台可以使用ScrapeGraphAI从各大新闻网站抓取新闻信息,为用户提供全面的新闻资讯。
新闻摘要:从新闻网站抓取文章,使用 LLM 进行文本摘要,快速生成新闻综述或行业报告,帮助用户及时了解最新资讯。企业可以使用ScrapeGraphAI抓取行业新闻,生成行业报告,为决策提供参考。
ScrapeGraphAI的未来发展趋势:智能化、自动化、个性化
随着人工智能技术的不断发展,ScrapeGraphAI的未来发展趋势将更加智能化、自动化、个性化:
- 更智能的语义理解:未来的ScrapeGraphAI将能够更深入地理解用户的意图,即使是模糊的指令也能准确地执行。
- 更强大的自适应能力:未来的ScrapeGraphAI将能够更好地适应网站结构的变化,无需人工干预也能保证数据抓取的准确性。
- 更个性化的数据定制:未来的ScrapeGraphAI将能够根据用户的需求,定制数据抓取和处理流程,提供更个性化的数据服务。
- 更广泛的应用场景:未来的ScrapeGraphAI将应用于更广泛的领域,例如智能客服、智能推荐、智能风控等。
ScrapeGraphAI作为一款AI赋能的网络爬虫工具,正在改变着我们获取和利用网络数据的方式。它以其智能化的数据抓取能力、高效的图逻辑引擎和广泛的应用场景,为各行各业带来了巨大的价值。随着人工智能技术的不断发展,ScrapeGraphAI的未来发展潜力无限,它将成为我们探索和利用网络数据的重要工具。








