
在科技日新月异的今天,人工智能(AI)正以惊人的速度渗透到我们生活的方方面面。最近,一项名为“3DTown”的创新框架,由普林斯顿大学、哥伦比亚大学以及Cyberever AI公司联合推出,再次刷新了我们对3D世界构建的认知。这项黑科技能够仅凭一张俯视图,生成逼真且连贯的3D城镇场景,无疑为3D建模领域带来了一场革命。更令人惊喜的是,3DTown 采用免训练(training-free)模式,无需耗费大量资源进行数据训练,即可直接投入使用,极大地降低了3D场景构建的门槛。

传统3D建模的困境
长期以来,高质量3D场景的构建被视为一项高成本、高技术门槛的“烧钱游戏”。传统3D建模方式面临诸多挑战:
- 设备成本高昂: 专业级3D扫描设备价格动辄数十万甚至上百万,让许多开发者望而却步。
- 数据采集繁琐: 需要从多角度、多视角采集数据,以避免模型出现“盲区”,增加了数据处理的复杂性。
- 人工建模耗时费力: 建模师需要花费大量时间和精力进行精细化处理,工作强度极大。
尽管近年来AI在3D对象生成方面取得显著进展,但要将这些技术扩展到整个复杂场景的生成,仍然面临诸多挑战。常见的“翻车”现象包括:几何结构不一致、布局与输入图像不符、网格质量差等问题,严重影响了3D场景的真实感和可用性。
3DTown:化腐朽为神奇的“造城术”
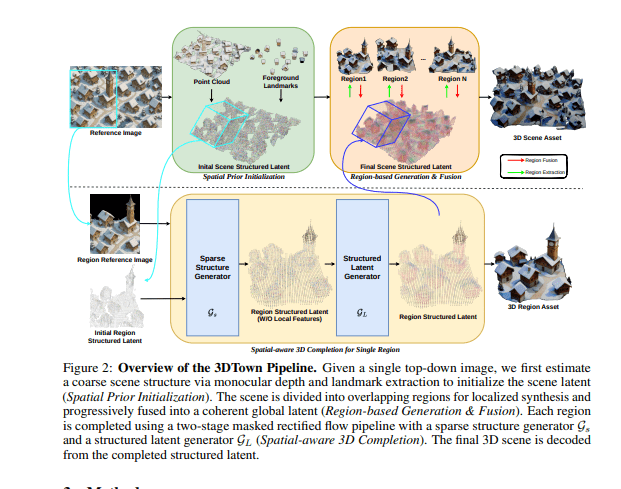
3DTown 的出现,旨在解决传统3D建模的痛点,通过最少的输入(一张俯视图),生成高质量的3D场景。用户只需提供一张俯视图,无论是网络图片还是手绘草图,3DTown 都能将其转化为逼真的3D模型。这种“化腐朽为神奇”的能力,源于其两大核心技术:区域生成和空间感知3D修复。

1. 区域生成:化整为零,各个击破
面对复杂3D场景的生成难题,3DTown 采用了“化整为零”的策略。它将输入的俯视图分解为多个重叠区域,然后对每个区域进行独立的3D生成。这种方式类似于将一张巨大的拼图拆分成小块,然后集中精力拼好每一块。区域生成策略的优势在于:
- 提升分辨率和细节: AI可以集中资源生成每个区域的高分辨率几何结构和纹理,从而实现更丰富的细节。
- 改善图像到3D的对齐: 针对局部区域进行生成,AI能够更精确地理解图像细节,生成与图片高度匹配的3D模型。
2. 空间感知3D修复:让“碎片”完美拼接
将场景分解成独立区域进行生成后,如何将这些“碎片”完美拼接成一个连贯的整体?3DTown 的第二个“黑科技”——空间感知3D修复(spatial-aware 3D inpainting)应运而生。
首先,该技术会根据输入的图片,估算出粗略的3D结构,相当于为AI绘制了一张“草稿图”,标明建筑物和道路的位置。然后,利用蒙版矫正流(masked rectified flow)修复过程,填充缺失的几何结构,同时保持整体结构的连续性。这一过程就像一位专业的“3D瓦工”,在AI拼好每块“积木”后,自动填补积木之间的缝隙,确保整体结构不走样。
免训练模式:效果超越同行
3DTown 最令人称道的特性之一是其“免训练”模式。它直接利用预训练好的3D对象生成器(如Trellis),结合独特的区域生成和空间修复策略,合成复杂的3D场景。这种模式如同顶级厨师直接从市场采购优质食材,再以精湛的厨艺烹饪出米其林星级菜肴,无需从零开始。
实验结果表明,3DTown 在多项指标上全面超越了当前最先进的Image-to-3D生成模型:
- 几何质量: 人类评分和GPT-4o评分均显示,3DTown 生成的3D模型几何结构更精细、更接近真实。其几何质量得分比Trellis高出37个百分点,比TripoSG高出55个百分点。
- 布局连贯性: 生成的场景布局与输入图片完美对齐,避免了“跑偏”现象。在布局连贯性方面,3DTown 的人类偏好得分比Trellis高出40个百分点,在GPT-4o评估中更是达到87.9%,而Hunyuan3D-2仅为12.1%。
- 纹理保真度: 模型表面的纹理逼真且一致,与现实世界高度相似。
无论是雪镇、沙漠小镇还是荷兰风格小镇,3DTown 都能轻松驾驭,生成高度连贯且逼真的3D场景。相比之下,其他模型常常出现结构过于简化、布局扭曲或物体重复等问题。
拆解与缝合的艺术
3DTown 的成功,再次印证了“空间分解”和“先验引导修复”策略在提升2D图像到高质量3D场景转换过程中的重要性。
区域分解使AI能够在每个局部区域充分发挥其预训练优势,避免了处理整个复杂场景时的“力不从心”。地标引导则为AI提供了“定海神针”,确保了场景的整体结构和关键物体的连续性,防止生成结果“跑偏”。
这项技术在游戏开发、电影制作、元宇宙构建乃至机器人仿真训练等领域都具有巨大的应用潜力。未来,我们或许只需一张草图,就能快速生成一个可供探索的3D世界,极大地提升效率。
未来的展望
当然,任何新技术都不是完美的。3DTown 目前也存在一些局限性:
- 由于其依赖的预训练3D生成器基于单个物体训练,因此在某些区域生成时可能会出现“幻觉”,如重复的立面或不真实的屋顶形状。
- 对初始粗略3D结构的估计有时存在“漏洞”,导致生成的表面出现空洞或过于平滑。
但这些问题都可以通过未来的优化来解决,例如结合多视角数据、引入语义先验或进行场景级别的微调等。
3DTown 的出现,无疑是3D内容生成领域的一个重要里程碑。它以巧妙、高效且无需训练的方式,为我们打开了从2D到3D快速构建复杂场景的大门。展望未来,我们每个人都有可能成为3D世界的“创世神”,只需一张图,就能创造出心中的“理想之城”。
3DTown的创新之处在于其区域生成与空间感知修复两大核心技术,前者将复杂场景分解为多个小区域独立处理,后者则确保这些区域能够无缝衔接,形成一个整体连贯的3D环境。这种化繁为简的设计思路,极大地降低了3D建模的门槛,使得即使没有专业技能的用户也能轻松创建出逼真的3D场景。此外,免训练的特性也大大节省了时间和资源,加速了3D内容生成的效率。
然而,3DTown并非完美无缺。由于其依赖于预训练的3D对象生成器,在处理特定区域时可能会出现一些不真实的细节,例如重复的立面或不自然的屋顶形状。此外,初始3D结构的估计也可能存在误差,导致生成的表面出现空洞或过于平滑。这些问题表明,3DTown在细节处理和整体结构的精确性方面仍有提升空间。未来的研究方向可以包括多视角数据融合、语义先验知识引入以及场景级别的微调等,以进一步提升3DTown的性能和可靠性。
尽管存在一些局限性,3DTown的潜力依然巨大。它为游戏开发、电影制作、元宇宙构建以及机器人仿真训练等领域带来了新的可能性。想象一下,未来我们只需一张简单的草图,就能快速生成一个可供探索的3D世界,这将极大地提升相关行业的生产效率和创造力。更重要的是,3DTown的出现 democratizes 3D content creation,使得更多的人能够参与到3D世界的构建中来,这将推动3D技术的普及和发展。








