
在人工智能领域,将视频数据转化为可交互的世界模型一直是研究的热点。最近,清华大学与重庆大学联合推出了一个名为Vid2World的创新框架,该框架旨在将全序列、非因果的被动视频扩散模型(VDM)转化为自回归、交互式、动作条件化的世界模型。这项研究的突破在于它解决了传统VDM在因果生成和动作条件化方面的不足,为机器人操作和游戏模拟等复杂环境提供了更强大的支持。\n\nVid2World的核心功能与优势\n\nVid2World框架具有多项显著的功能和优势,使其在世界模型领域中脱颖而出。\n\n1. 高保真视频生成:Vid2World能够生成与真实视频在视觉保真度和动态一致性上高度相似的预测,这意味着它不仅可以生成清晰的图像,还能准确地模拟视频中的动态变化。这种高保真度对于许多应用场景至关重要,例如在机器人操作中,机器人需要准确地理解环境的变化才能做出正确的决策。\n\n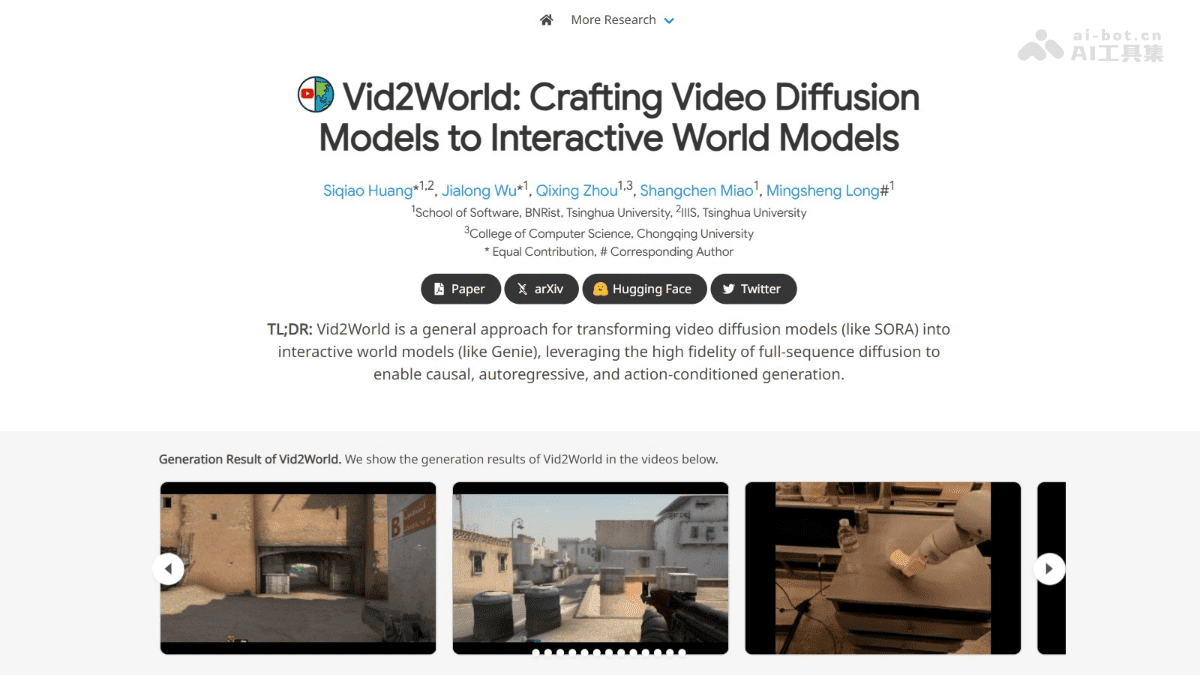 \n\n2. 动作条件化:该框架可以根据输入的动作序列生成相应的视频帧,从而实现细粒度的动作控制。这意味着用户可以通过指定动作来控制视频的生成过程,例如,在游戏模拟中,开发者可以通过控制角色的动作来生成相应的游戏画面。\n\n3. 自回归生成:Vid2World采用自回归的方式逐帧生成视频,每一步的生成仅依赖于过去的帧和动作。这种自回归的生成方式使得模型能够更好地捕捉视频中的时间依赖关系,从而生成更连贯的视频序列。\n\n4. 因果推理:模型能够进行因果推演,预测仅依赖于过去的信息,不会受到未来信息的影响。这一特性对于需要进行预测的任务至关重要,例如在机器人操作中,机器人需要根据当前的状态和过去的经验来预测未来的状态,而不能依赖于未来的信息。\n\n5. 支持下游任务:Vid2World框架可以支持辅助机器人操作、游戏模拟等交互式任务。这意味着该框架不仅可以用于生成视频,还可以用于解决实际问题,例如,在机器人操作中,可以使用Vid2World来生成机器人的操作视频,从而帮助机器人学习如何完成任务。\n\nVid2World的技术原理\n\nVid2World框架的技术原理主要包括视频扩散因果化和因果动作引导两个方面。\n\n1. 视频扩散因果化:\n\n传统的视频扩散模型(VDM)对整个视频序列同时进行去噪,这种全序列的生成方式不适合因果推演,因为未来的帧会影响过去的帧。为了实现因果生成,Vid2World对预训练的VDM进行了修改,时间注意力层基于应用因果掩码,限制注意力机制只能访问过去的帧,从而实现因果性。\n\n此外,Vid2World还推出了混合权重转移方案,保留预训练权重的同时,让模型适应因果卷积层。通过Diffusion Forcing技术,在训练时为每一帧独立采样噪声水平,让模型学习到不同帧之间的噪声水平组合,从而支持自回归生成。\n\n2. 因果动作引导:\n\n为了让模型响应细粒度的动作,Vid2World引入了因果动作引导机制。每个动作基于轻量级的多层感知机(MLP)进行编码,并添加到对应的帧中。在训练时,Vid2World采用固定概率独立丢弃每个动作,迫使模型同时学习条件和非条件得分函数。\n\n在测试时,Vid2World基于线性组合条件得分函数和非条件得分函数,调整对动作变化的响应性。通过独立丢弃动作,模型能够学习到动作对生成结果的影响,从而在自回归生成过程中更好地响应动作输入。\n\nVid2World的应用场景\n\nVid2World框架具有广泛的应用前景,以下是一些典型的应用场景:\n\n1. 机器人操作:\n\nVid2World可以生成高保真预测,辅助机器人任务规划。例如,在机器人抓取物体时,可以使用Vid2World来预测机器人在不同动作下的状态,从而帮助机器人选择最佳的抓取策略。\n\n2. 游戏模拟:\n\nVid2World可以生成与真实游戏高度一致的视频,助力神经游戏引擎开发。例如,可以使用Vid2World来生成游戏的场景和角色动画,从而提高游戏开发的效率和质量。\n\n3. 策略评估:\n\nVid2World可以模拟不同策略执行结果,助力策略优化。例如,在自动驾驶中,可以使用Vid2World来模拟不同的驾驶策略,从而评估这些策略的性能和安全性。\n\n4. 视频预测:\n\nVid2World可以基于已有帧和动作序列预测后续帧,用于视频补全等任务。例如,可以使用Vid2World来补全缺失的视频帧,从而提高视频的质量和观看体验。\n\n5. 虚拟环境构建:\n\nVid2World可以生成响应动作的虚拟场景,提升虚拟现实交互性。例如,可以使用Vid2World来生成虚拟现实环境中的物体和场景,从而提高虚拟现实的真实感和沉浸感。\n\n案例分析:Vid2World在机器人操作中的应用\n\n为了更具体地了解Vid2World的应用,我们来看一个案例:使用Vid2World来辅助机器人操作。\n\n假设我们有一个机器人需要完成一个简单的任务:将一个杯子从桌子上拿起并放到另一个位置。为了完成这个任务,机器人需要进行一系列的动作,例如:\n\n* 伸出手臂\n* 抓住杯子\n* 抬起杯子\n* 移动手臂\n* 放下杯子\n\n在传统的机器人操作中,机器人需要通过编程来完成这些动作。但是,这种方法需要大量的人工工作,并且难以适应不同的环境和任务。\n\n使用Vid2World,我们可以通过以下步骤来辅助机器人完成这个任务:\n\n1. 收集数据:首先,我们需要收集一些关于机器人操作的数据,例如机器人在不同状态下的图像和动作序列。\n2. 训练模型:然后,我们使用这些数据来训练Vid2World模型。\n3. 生成预测:在训练完成后,我们可以使用Vid2World模型来预测机器人在不同动作下的状态。例如,我们可以输入机器人的当前状态和“伸出手臂”这个动作,Vid2World模型会预测机器人在伸出手臂后的状态。\n4. 规划动作:根据Vid2World模型的预测结果,我们可以规划机器人的动作序列。例如,如果Vid2World模型预测机器人在伸出手臂后能够成功抓住杯子,那么我们可以让机器人执行这个动作。\n5. 执行动作:最后,我们让机器人执行规划好的动作序列,从而完成任务。\n\n通过使用Vid2World,我们可以减少人工工作量,并且提高机器人操作的效率和鲁棒性。\n\n未来展望\n\nVid2World作为一种创新的世界模型框架,为视频数据的理解和应用开辟了新的途径。随着人工智能技术的不断发展,Vid2World有望在更多领域发挥重要作用,例如自动驾驶、智能家居、教育娱乐等。\n\n未来的研究方向可能包括:\n\n* 提高Vid2World模型的生成质量和效率\n* 探索Vid2World模型在更多领域的应用\n* 研究如何将Vid2World模型与其他人工智能技术相结合\n\n总的来说,Vid2World是一项具有重要意义的研究成果,它为世界模型领域的发展做出了重要贡献。
\n\n2. 动作条件化:该框架可以根据输入的动作序列生成相应的视频帧,从而实现细粒度的动作控制。这意味着用户可以通过指定动作来控制视频的生成过程,例如,在游戏模拟中,开发者可以通过控制角色的动作来生成相应的游戏画面。\n\n3. 自回归生成:Vid2World采用自回归的方式逐帧生成视频,每一步的生成仅依赖于过去的帧和动作。这种自回归的生成方式使得模型能够更好地捕捉视频中的时间依赖关系,从而生成更连贯的视频序列。\n\n4. 因果推理:模型能够进行因果推演,预测仅依赖于过去的信息,不会受到未来信息的影响。这一特性对于需要进行预测的任务至关重要,例如在机器人操作中,机器人需要根据当前的状态和过去的经验来预测未来的状态,而不能依赖于未来的信息。\n\n5. 支持下游任务:Vid2World框架可以支持辅助机器人操作、游戏模拟等交互式任务。这意味着该框架不仅可以用于生成视频,还可以用于解决实际问题,例如,在机器人操作中,可以使用Vid2World来生成机器人的操作视频,从而帮助机器人学习如何完成任务。\n\nVid2World的技术原理\n\nVid2World框架的技术原理主要包括视频扩散因果化和因果动作引导两个方面。\n\n1. 视频扩散因果化:\n\n传统的视频扩散模型(VDM)对整个视频序列同时进行去噪,这种全序列的生成方式不适合因果推演,因为未来的帧会影响过去的帧。为了实现因果生成,Vid2World对预训练的VDM进行了修改,时间注意力层基于应用因果掩码,限制注意力机制只能访问过去的帧,从而实现因果性。\n\n此外,Vid2World还推出了混合权重转移方案,保留预训练权重的同时,让模型适应因果卷积层。通过Diffusion Forcing技术,在训练时为每一帧独立采样噪声水平,让模型学习到不同帧之间的噪声水平组合,从而支持自回归生成。\n\n2. 因果动作引导:\n\n为了让模型响应细粒度的动作,Vid2World引入了因果动作引导机制。每个动作基于轻量级的多层感知机(MLP)进行编码,并添加到对应的帧中。在训练时,Vid2World采用固定概率独立丢弃每个动作,迫使模型同时学习条件和非条件得分函数。\n\n在测试时,Vid2World基于线性组合条件得分函数和非条件得分函数,调整对动作变化的响应性。通过独立丢弃动作,模型能够学习到动作对生成结果的影响,从而在自回归生成过程中更好地响应动作输入。\n\nVid2World的应用场景\n\nVid2World框架具有广泛的应用前景,以下是一些典型的应用场景:\n\n1. 机器人操作:\n\nVid2World可以生成高保真预测,辅助机器人任务规划。例如,在机器人抓取物体时,可以使用Vid2World来预测机器人在不同动作下的状态,从而帮助机器人选择最佳的抓取策略。\n\n2. 游戏模拟:\n\nVid2World可以生成与真实游戏高度一致的视频,助力神经游戏引擎开发。例如,可以使用Vid2World来生成游戏的场景和角色动画,从而提高游戏开发的效率和质量。\n\n3. 策略评估:\n\nVid2World可以模拟不同策略执行结果,助力策略优化。例如,在自动驾驶中,可以使用Vid2World来模拟不同的驾驶策略,从而评估这些策略的性能和安全性。\n\n4. 视频预测:\n\nVid2World可以基于已有帧和动作序列预测后续帧,用于视频补全等任务。例如,可以使用Vid2World来补全缺失的视频帧,从而提高视频的质量和观看体验。\n\n5. 虚拟环境构建:\n\nVid2World可以生成响应动作的虚拟场景,提升虚拟现实交互性。例如,可以使用Vid2World来生成虚拟现实环境中的物体和场景,从而提高虚拟现实的真实感和沉浸感。\n\n案例分析:Vid2World在机器人操作中的应用\n\n为了更具体地了解Vid2World的应用,我们来看一个案例:使用Vid2World来辅助机器人操作。\n\n假设我们有一个机器人需要完成一个简单的任务:将一个杯子从桌子上拿起并放到另一个位置。为了完成这个任务,机器人需要进行一系列的动作,例如:\n\n* 伸出手臂\n* 抓住杯子\n* 抬起杯子\n* 移动手臂\n* 放下杯子\n\n在传统的机器人操作中,机器人需要通过编程来完成这些动作。但是,这种方法需要大量的人工工作,并且难以适应不同的环境和任务。\n\n使用Vid2World,我们可以通过以下步骤来辅助机器人完成这个任务:\n\n1. 收集数据:首先,我们需要收集一些关于机器人操作的数据,例如机器人在不同状态下的图像和动作序列。\n2. 训练模型:然后,我们使用这些数据来训练Vid2World模型。\n3. 生成预测:在训练完成后,我们可以使用Vid2World模型来预测机器人在不同动作下的状态。例如,我们可以输入机器人的当前状态和“伸出手臂”这个动作,Vid2World模型会预测机器人在伸出手臂后的状态。\n4. 规划动作:根据Vid2World模型的预测结果,我们可以规划机器人的动作序列。例如,如果Vid2World模型预测机器人在伸出手臂后能够成功抓住杯子,那么我们可以让机器人执行这个动作。\n5. 执行动作:最后,我们让机器人执行规划好的动作序列,从而完成任务。\n\n通过使用Vid2World,我们可以减少人工工作量,并且提高机器人操作的效率和鲁棒性。\n\n未来展望\n\nVid2World作为一种创新的世界模型框架,为视频数据的理解和应用开辟了新的途径。随着人工智能技术的不断发展,Vid2World有望在更多领域发挥重要作用,例如自动驾驶、智能家居、教育娱乐等。\n\n未来的研究方向可能包括:\n\n* 提高Vid2World模型的生成质量和效率\n* 探索Vid2World模型在更多领域的应用\n* 研究如何将Vid2World模型与其他人工智能技术相结合\n\n总的来说,Vid2World是一项具有重要意义的研究成果,它为世界模型领域的发展做出了重要贡献。
Vid2World:视频模型转世界模型,清华联合重大突破
5
 最新文章
最新文章 
TalkCody开源AI编程助手:50+模型支持与多模态交互革命
3小时前

Seedream 4.5:字节跳动AI图像创作模型的商业革命
3小时前

可灵2.6革新AI视频创作:音画同步生成技术解析
3小时前

Flowra:开源AI工作流开发工具如何重塑AI应用构建
3小时前

Gemini3 DeepThink:谷歌重塑AI推理边界的革命性突破
3小时前

Workspace Studio:谷歌AI智能体构建工具如何重塑工作自动化
3小时前
RoboCOIN:具身智能数据集如何重塑机器人学习范式
3小时前

NewBie-image-Exp0.1:开源动漫图像生成模型的突破与潜力
3小时前
混元2.0深度解析:腾讯新一代AI模型的突破与应用
3小时前

AI技术革新:从视频生成到语音交互的突破性进展
3小时前