
在科技日新月异的今天,人工智能(AI)正以前所未有的速度渗透到我们生活的方方面面。从办公效率的提升到艺术创作的革新,AI的身影无处不在。本文将深入剖析近期AI领域的重大进展,带您一览这场技术革命的最新动态。
一、百度PaddleOCR 3.0:OCR精度飞跃
百度Paddle团队近日推出了PaddleOCR 3.0版本,这一更新在文本识别精度、多语言支持、手写识别以及文档解析能力上都实现了显著提升。更令人瞩目的是,它还增加了对国产硬件的支持,并引入了PP-OCRv5、PP-StructureV3和PP-ChatOCRv4等核心功能。

PP-OCRv5作为全场景文本识别模型,能够支持五种类型的文本识别,整体精度提升高达13%,实现了无缝部署,为开发者带来了极大的便利。PP-StructureV3则专注于文档解析,通过强化页面检测和表格识别能力,在高精度解析方面表现出色,适用于多种复杂场景。PP-ChatOCRv4是智能文档理解解决方案,它与文心大模型的结合,使得关键信息提取精度提高了15%,能够处理更为复杂的文档。
二、昆仑万维:AI办公的革新者
昆仑万维推出的天工SkyAgents智能体,是一款基于自研Deep Research技术打造的AI办公智能体。它以强大的多模态内容生成能力和仅为OpenAI 40%的成本优势,引发了全球AI社区的广泛关注。

天工SkyAgents智能体采用了多智能体架构,包括五个专家智能体和一个通用智能体,能够一站式生成各种办公内容。其核心技术Deep Research模型以低成本和高效率著称,在GAIA基准测试中,其得分甚至超越了OpenAI Deep Research,达到了82.42分。此外,该智能体的开源框架和低成本部署策略使其成为中小型企业和个人开发者的理想选择。
三、OpenAI:简化智能体开发流程
OpenAI的Responses API增加了对MCP的支持,这大大降低了将AI模型与外部工具集成的难度。同时,OpenAI还推出了一系列功能升级,包括图像生成、代码解释器以及优化的文件搜索功能,这些都将极大地提升开发效率。
通过支持MCP协议,OpenAI Responses API允许开发者以最少的代码连接外部工具。新增的图像生成、代码解释器和文件搜索功能则进一步提高了开发效率。MCP已成为AI智能体开发的行业标准,有助于促进跨平台协作和灵活性。
四、xAI:实时搜索赋能AI
xAI正式推出了Live Search API。该功能允许开发者使用Grok模型实时搜索来自各种数据源的信息,从而极大地增强了AI应用程序的动态信息处理能力。目前,该API正在进行免费公开测试,为开发者提供强大的工具来简化搜索逻辑和数据集成。

Live Search API支持自主搜索决策,Grok可以根据对话上下文自动判断是否需要搜索,无需人工干预。它还提供了多样化的数据来源,包括X平台、网页、新闻和RSS feed,确保信息的全面性和实时更新。此外,该API还具有高度的灵活性和高效的集成能力,支持多种SDK,允许开发者轻松调整基本URL和API密钥以实现快速访问。
五、Google Sparkify:知识理解的新方式
Google的Sparkify利用Gemini和Veo模型将复杂的知识点转化为直观的动画短片,适用于教育、科学普及和内容创作等领域。
通过动画短片直观地呈现复杂的知识点,可以有效提高理解效率。Sparkify使用Gemini2.5和Veo2模型制作高质量的动画视频,未来还将支持多语言扩展,覆盖更多的地区和人群。
六、Mistral AI:开源社区的回归
Mistral AI发布了全新的开源语言模型Devstral,该模型轻量级且专为代理AI软件开发而设计。它具有出色的性能,并支持本地操作,展示了开源社区合作的力量。

Devstral拥有2400万个参数,并以Apache2.0许可证发布,允许自由部署和商业化。其性能卓越,在SWE-Bench验证中超越了大多数闭源模型,适用于本地和私有部署场景。作为Codestral系列的最新进展,Devstral支持跨文件上下文理解,适用于复杂的软件开发任务。
七、Video Ocean:视频生成的普及
Lucheng Technology推出了全新的AI视频生成工具Video Ocean,该工具支持快速生成高质量视频,提供各种效果和功能,且价格亲民,甚至完全免费,引发了一股创作热潮。

Video Ocean支持在5-10秒内生成2K/4K HDR高质量视频,适用于各种场景创作。它还提供了大量的模板和效果,如Laugh、Cakeify等,使初学者也能轻松创建专业级视频。其价格仅为Keling 2.0的1/10,甚至完全免费,受到了各类用户群体的积极反馈。
八、Google SynthID Detector:AI内容检测
Google推出了名为SynthID Detector的新工具,旨在帮助用户检测内容是否由其AI工具生成。该工具可以识别AI生成的内容,并突出显示标有SynthID水印的部分,目前正在向早期测试人员提供。
SynthID Detector可用于识别AI生成的内容,支持图像、文本、音频和视频。该工具可以自动扫描上传的内容,搜索并突出显示SynthID水印。目前仅向早期测试人员提供,未来将逐步推广到更多用户。
九、Google NotebookLM:AI笔记的崛起
在过去的六个月里,Google的AI辅助知识管理工具NotebookLM的月访问量增长率达到了56%。它凭借“音频概述”、多语言支持和多样化的应用场景受到了广泛关注。
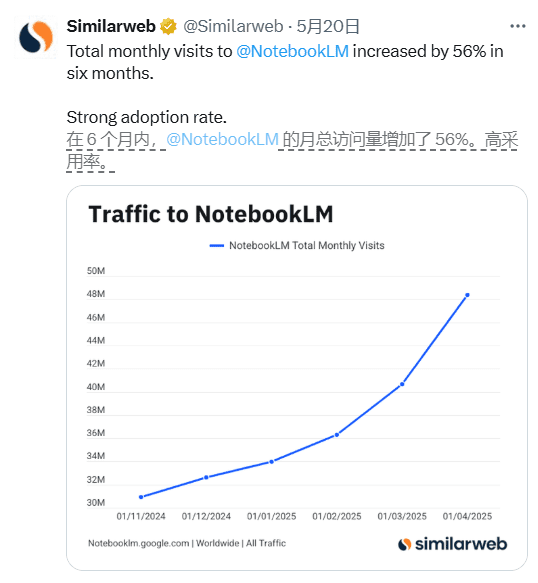
NotebookLM的月访问量增长了56%,成为AI应用领域的一匹黑马。它支持50多种语言的播客内容生成,打破了语言障碍,增强了用户体验。适用于学生、研究人员和内容创作者,可高效应用于学术和娱乐领域。
十、SiliconFlow:推理模型的升级
SiliconFlow升级了其推理模型API,将最大上下文长度显著增加到128K,从而增强了模型的推理能力和输出质量。它还引入了对思维链和回复内容长度的独立控制,使开发者能够更灵活地调整模型性能。
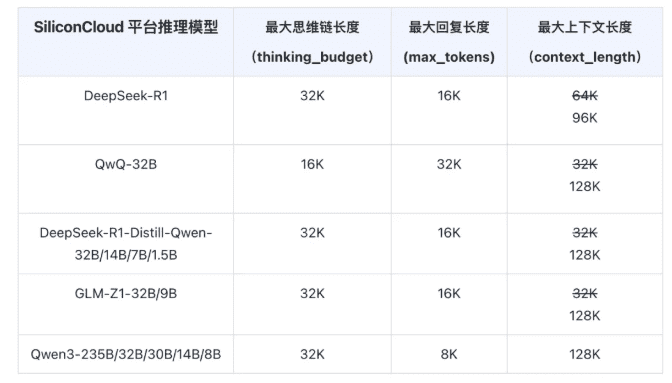
支持最大128K的上下文长度,显著增强了模型的思维深度和输出完整性。引入了对思维链和回复内容长度的独立控制,加强了开发者对模型行为的精确控制。当达到长度限制时,模型输出将被截断并标记原因,确保使用的透明度。
十一、Google DeepMind:AI音乐的新篇章
Lyria2是Google DeepMind发布的最新音乐生成模型。它具有高保真音质、实时交互能力和多风格适应性,为音乐创作带来了革命性的变化。
Lyria2可以生成48kHz立体声音频,精确捕捉音乐细节,适用于专业音乐制作和商业项目。Lyria RealTime功能允许用户即时调整音乐风格、节奏等,激发创作灵感。集成到Music AI Sandbox工具包中,支持文本、乐谱或音频片段输入,涵盖各种音乐风格。
十二、多模态大模型MMaDA:AI的“跨维度思考”
MMaDA是由多所顶尖大学和企业联合开发的多模态大模型,它凭借独特的统一扩散架构、混合长链思维微调和统一强化学习算法,实现了文本、图像和其他模态之间的无缝切换和深度推理,性能优于GPT-4等现有模型。

统一扩散架构打破了传统多模态模型的壁垒,实现了对文本、图像和其他数据类型的无缝处理。混合长链思维微调通过跨模态推理对齐,使AI具有深度思考能力。统一强化学习算法UniGRPO平衡了推理和生成任务,全面提升了AI性能。
十三、Microsoft Magentic-UI:Web智能体的探索
Magentic-UI是一款以人为中心的AI智能体研究原型,通过Web浏览器协助用户实时完成复杂的任务。它引入了协作规划和行为保护功能,确保用户在自动化过程中保持控制,同时确保安全性和灵活性。通过多智能体协作,支持计划学习,从历史任务中优化未来任务的自动化效率。

十四、Framer:AI设计的新纪元
Framer在I/O2025上推出了一系列新的AI功能,包括Wireframer、Workshop、Advanced Analytics和Vectors2.0。这些功能通过Web布局生成、交互式组件设计、矢量绘图升级和高级分析工具,显著降低了网站创建的成本和复杂性。

Wireframer可以快速生成网站线框图,Workshop可以设计交互式组件,Vectors2.0升级了矢量绘图功能,Advanced Analytics提供了高级分析工具。这些AI驱动的功能极大地简化了网站设计流程,降低了设计门槛。








