
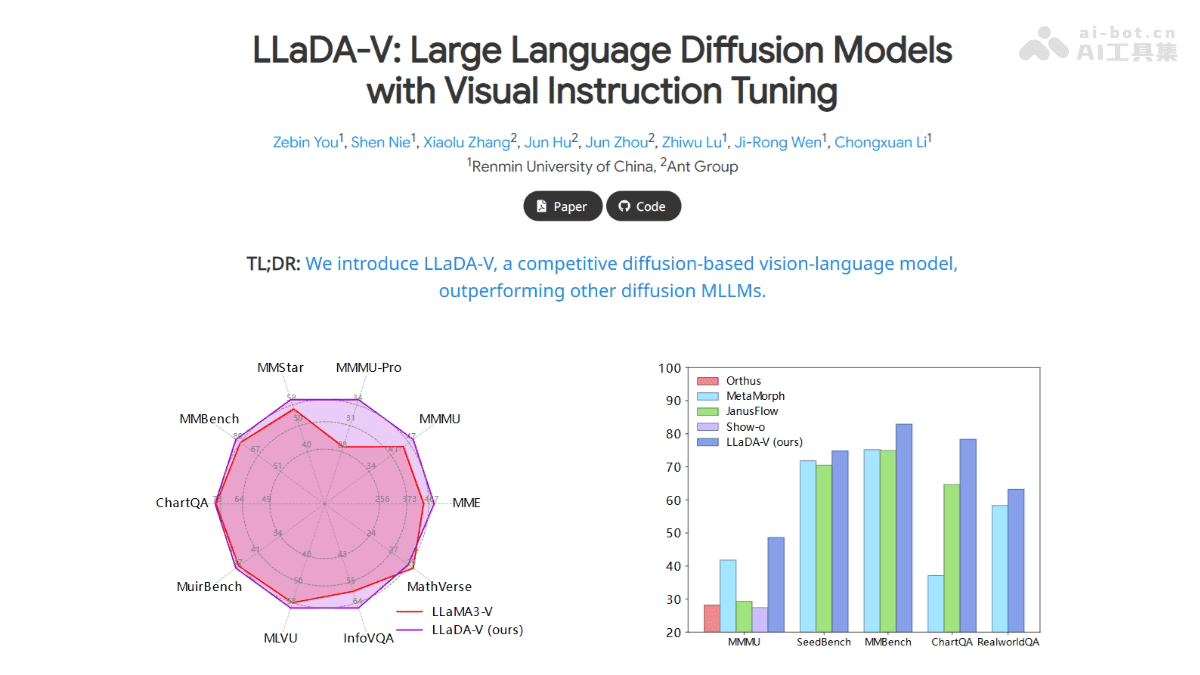
在人工智能领域,多模态大语言模型(MLLM)正逐渐成为研究和应用的热点。最近,由中国人民大学高瓴人工智能学院与蚂蚁集团联合推出的 LLaDA-V 模型引起了广泛关注。该模型基于纯扩散模型架构,专注于视觉指令微调,并在多模态理解方面达到了新的高度。本文将深入探讨 LLaDA-V 的技术原理、功能特点、应用场景以及未来的发展趋势,为读者提供一个全面而深入的了解。
LLaDA-V:多模态理解的新突破
LLaDA-V 模型的核心在于其独特的多模态对齐方式。传统的 MLLM 通常采用混合自回归-扩散模型或者纯自回归模型,但在处理视觉和语言信息的融合时,往往面临信息损失和对齐困难的问题。LLaDA-V 则通过引入视觉编码器和 MLP 连接器,有效地将视觉特征映射到语言嵌入空间,从而实现多模态信息的有效融合。这种方法的优势在于,它能够更好地保留视觉信息的细节,并在语言模型中实现更准确的语义表达。
技术原理:扩散模型与视觉指令微调
LLaDA-V 的技术核心在于扩散模型和视觉指令微调。扩散模型是一种生成模型,它通过逐步去除噪声来生成数据。在 LLaDA-V 中,采用了掩码扩散模型(Masked Diffusion Models),该模型通过随机掩码句子中的一些词,并训练模型预测掩码词的原始内容,从而提高模型的语言理解能力。掩码扩散模型的优势在于,它能够迫使模型更好地理解上下文信息,并在预测时考虑到整个句子的语义。
视觉指令微调是 LLaDA-V 的另一个关键技术。该框架包括视觉塔(Vision Tower)和 MLP 连接器(MLP Connector)。视觉塔负责将图像转换为视觉表示,而 MLP 连接器则将视觉表示映射到语言模型的词嵌入空间。通过这种方式,视觉特征和语言特征能够有效地对齐和融合。具体来说,视觉塔采用了 SigLIP 模型,该模型在图像特征提取方面具有很强的能力。MLP 连接器则通过多层感知机将视觉特征转换为语言特征,从而实现多模态信息的对齐。
此外,LLaDA-V 还采用了多阶段训练策略。在第一阶段,训练 MLP 连接器以对齐视觉表示和语言嵌入。在第二阶段,对整个模型进行微调,以理解和遵循视觉指令。在第三阶段,进一步增强模型的多模态推理能力,训练模型处理复杂的多模态推理任务。这种多阶段训练策略能够有效地提高模型的性能,并使其在各种任务中表现出色。
LLaDA-V 还采用了双向注意力机制,以支持模型在预测掩码词时考虑整个对话上下文。这种机制有助于模型更好地理解对话的整体逻辑和内容,并在多轮对话中生成更准确的回答。
主要功能:多场景应用
LLaDA-V 具备多种功能,使其在多个领域具有广泛的应用前景:
- 图像描述生成:根据输入的图像生成详细的描述文本。这项功能可以应用于图像检索、图像标注等领域,帮助用户更好地理解图像内容。
- 视觉问答:回答与图像内容相关的问题。这项功能可以应用于教育、旅游等领域,为用户提供更便捷的信息查询服务。
- 多轮多模态对话:在给定图像的上下文中进行多轮对话,理解生成与图像和对话历史相关的回答。这项功能可以应用于智能客服、虚拟助手等场景,提供更自然、更智能的对话体验。
- 复杂推理任务:在涉及图像和文本的复合任务中进行推理,例如解决与图像相关的数学问题或逻辑问题。这项功能可以应用于科研、教育等领域,帮助用户解决复杂的实际问题。
以下将分别讨论这些功能的具体应用。
图像描述生成
图像描述生成是指模型能够根据输入的图像,自动生成一段描述图像内容的文本。这项功能在很多场景中都有应用价值。例如,在电商领域,可以利用图像描述生成技术自动生成商品描述,提高商品信息的丰富度和吸引力。在新闻领域,可以利用图像描述生成技术自动生成新闻配图的描述,方便读者更好地理解新闻内容。在社交媒体领域,用户可以通过图像描述生成技术为自己的照片添加描述,增加互动性。
LLaDA-V 在图像描述生成方面的表现非常出色。它可以生成非常详细、准确的描述文本,并且能够捕捉到图像中的细节信息。例如,对于一张包含多个物体的图像,LLaDA-V 能够准确地识别出每个物体,并描述它们之间的关系。此外,LLaDA-V 还能够根据图像的整体氛围,生成具有情感色彩的描述文本。
视觉问答
视觉问答是指模型能够根据输入的图像和问题,生成与图像内容相关的答案。这项功能在教育、旅游等领域具有广泛的应用前景。例如,在教育领域,可以利用视觉问答技术开发智能辅导系统,帮助学生解答与图像相关的题目。在旅游领域,可以利用视觉问答技术为游客提供景点介绍和导览服务。
LLaDA-V 在视觉问答方面的表现同样出色。它可以准确地理解问题的意图,并根据图像内容生成准确的答案。例如,对于一张包含建筑物的图像,用户可以提问“这座建筑物是什么?”,LLaDA-V 能够准确地回答出建筑物的名称。此外,LLaDA-V 还能够处理一些复杂的视觉问答问题,例如“图中哪个人在做什么?”、“图中的天气如何?”等。
多轮多模态对话
多轮多模态对话是指模型能够在给定图像的上下文中,进行多轮对话,并生成与图像和对话历史相关的回答。这项功能在智能客服、虚拟助手等场景中具有重要的应用价值。例如,在智能客服领域,可以利用多轮多模态对话技术开发智能客服机器人,为用户提供更自然、更智能的客户服务。在虚拟助手领域,可以利用多轮多模态对话技术开发虚拟助手,帮助用户完成各种任务。
LLaDA-V 在多轮多模态对话方面的表现非常出色。它可以准确地理解对话的上下文信息,并根据图像内容和对话历史生成相关的回答。例如,用户可以先提问“图中有什么?”,LLaDA-V 回答“图中有一只猫和一只狗”。然后,用户可以继续提问“猫在做什么?”,LLaDA-V 能够根据图像内容回答“猫在睡觉”。这种多轮对话的能力使得 LLaDA-V 在智能交互方面具有很大的潜力。
复杂推理任务
复杂推理任务是指模型在涉及图像和文本的复合任务中进行推理,例如解决与图像相关的数学问题或逻辑问题。这项功能在科研、教育等领域具有重要的应用价值。例如,在科研领域,可以利用复杂推理任务解决一些需要结合图像和文本信息的科学问题。在教育领域,可以利用复杂推理任务开发智能教育系统,帮助学生提高解决问题的能力。
LLaDA-V 在复杂推理任务方面的表现也十分出色。它可以准确地理解问题的意图,并结合图像和文本信息进行推理,最终生成正确的答案。例如,对于一道与图像相关的数学题,LLaDA-V 能够识别出图像中的数字和符号,并进行计算,最终得出正确的答案。这种复杂推理能力使得 LLaDA-V 在解决实际问题方面具有很大的潜力。
项目地址与资源
对于有兴趣深入了解 LLaDA-V 模型的读者,以下是一些相关的项目地址和资源:
- 项目官网:https://ml-gsai.github.io/LLaDA-V
- GitHub 仓库:https://github.com/ML-GSAI/LLaDA-V
- arXiv 技术论文:https://arxiv.org/pdf/2505.16933
通过这些资源,读者可以更全面地了解 LLaDA-V 的技术细节和应用案例,并进行进一步的研究和开发。
应用场景:无限可能
除了上述功能之外,LLaDA-V 还可以应用于以下场景:
- 多图像与视频理解:分析多图像和视频内容,适用于视频分析和监控等场景。
多图像与视频理解是 LLaDA-V 的一个重要应用方向。随着视频内容的爆炸式增长,如何有效地理解和分析视频内容成为了一个重要的研究问题。LLaDA-V 可以通过分析视频中的每一帧图像,并结合语音和文本信息,实现对视频内容的全面理解。这项技术可以应用于视频监控、智能安防、视频推荐等领域。
在视频监控领域,可以利用 LLaDA-V 自动识别视频中的异常行为,例如入侵、盗窃等,并及时发出警报。在智能安防领域,可以利用 LLaDA-V 分析监控视频,识别潜在的安全隐患,并采取相应的措施。在视频推荐领域,可以利用 LLaDA-V 分析用户的观看历史,并推荐相关的视频内容,提高用户体验。
LLaDA-V 的出现,为多模态大语言模型的发展注入了新的活力。其独特的技术原理和强大的功能,使其在多个领域具有广泛的应用前景。随着技术的不断发展,LLaDA-V 将在未来发挥更大的作用,为人们的生活和工作带来更多的便利。
未来展望:持续创新
LLaDA-V 作为多模态大语言模型领域的一个重要进展,无疑为未来的研究方向提供了新的思路。我们可以预见,未来的 MLLM 将会更加注重以下几个方面:
- 模型的可解释性:提高模型的可解释性,使用户能够更好地理解模型的决策过程。这对于在一些高风险领域应用 MLLM 非常重要,例如医疗、金融等。
- 模型的鲁棒性:提高模型的鲁棒性,使其在面对噪声数据和对抗攻击时仍能保持良好的性能。这对于保证 MLLM 的稳定性和可靠性非常重要。
- 模型的泛化能力:提高模型的泛化能力,使其能够适应不同的任务和领域。这对于扩大 MLLM 的应用范围非常重要。
- 模型的效率:提高模型的效率,使其能够在资源有限的设备上运行。这对于在移动设备和嵌入式设备上应用 MLLM 非常重要。
为了实现这些目标,研究人员需要不断探索新的技术和方法,例如:
- 知识图谱:将知识图谱引入 MLLM,提高模型的知识推理能力。
- 自监督学习:利用自监督学习方法,减少对标注数据的依赖。
- 模型压缩:采用模型压缩技术,减小模型的体积和计算复杂度。
- 联邦学习:利用联邦学习技术,保护用户数据的隐私。
我们有理由相信,在未来的发展中,多模态大语言模型将会取得更大的突破,为人工智能领域带来更多的惊喜。








