
在人工智能领域,每天都有新的突破和创新涌现。今天,我们为您带来最新的AI技术进展,涵盖图像生成、软件工程、语音合成等多个热门方向。这些技术不仅提升了效率,也为各行各业带来了新的可能性。
腾讯混元图像2.0:毫秒级实时图像生成
腾讯最新发布的混元图像2.0模型,在图像生成的速度和质量上都实现了显著提升。该模型引入了实时绘画板功能,为用户提供更加流畅的交互体验。参数量的增加使得模型能够以毫秒级的速度响应用户的指令,告别了传统AI图像生成技术的漫长等待。
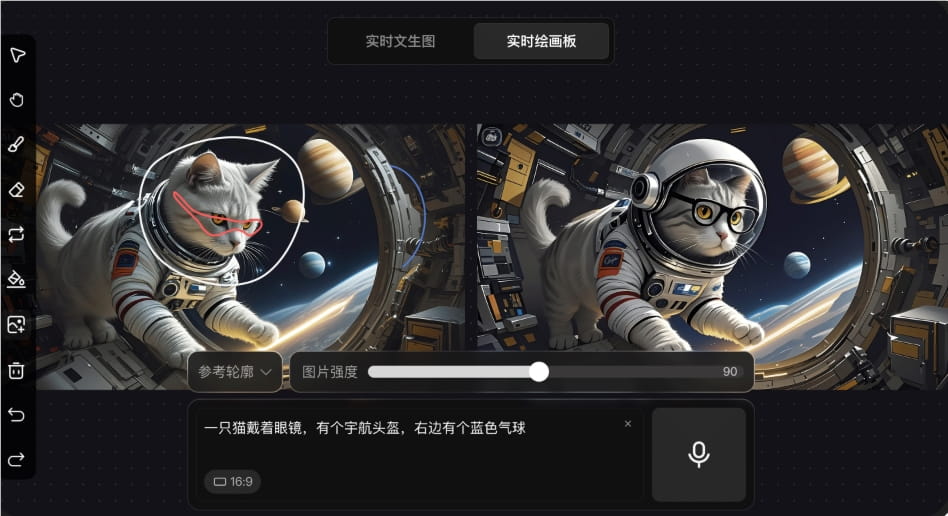
混元图像2.0在图像质量方面也达到了新的高度,对复杂指令的理解准确率超过95%,大大减少了AI生成图像常见的“AI味”。此外,实时绘画板功能支持多图像融合,优化了设计流程,为设计师们提供了更高效的创作工具。这项技术的突破,无疑将加速图像生成在各个领域的应用,从广告设计到游戏开发,都将受益于其高效和高质量。
浪潮SWE-1系列:全流程软件工程AI模型
浪潮推出了自主研发的SWE-1系列AI模型,该系列模型覆盖了从编码到终端操作的整个软件工程流程,极大地提高了开发效率。SWE-1系列包括SWE-1、SWE-1-lite和SWE-1-mini三款模型,旨在满足不同用户的需求,展示了浪潮在软件工程领域的雄心。

SWE-1系列通过流程感知设计优化了整个软件工程流程,将开发效率提升高达99%,解决了复杂任务的处理难题。这三款模型分别面向个人开发者、初创企业和企业团队,提供了定制化的解决方案。SWE-1增强了对多工具协作的支持,降低了部署成本,为开发者提供了更贴近实际工作的AI助手。这一创新有望改变软件开发的模式,让开发者能够更专注于创新和解决复杂问题。
DeepSeek-V3:揭秘低成本大模型训练
DeepSeek团队发布了关于最新模型DeepSeek-V3的技术论文,探讨了大型语言模型训练中的挑战和硬件架构的考量。该论文提出了有效的硬件感知模型设计,旨在实现经济高效的训练和推理。DeepSeek-V3采用了DeepSeekMoE架构和MLA架构,提高了内存效率,每个token仅需70KB的内存。

通过混合专家架构,DeepSeek-V3显著减少了激活参数的数量,从而将训练成本降低了一个数量级。此外,该模型还优化了推理速度,通过双微批重叠架构最大化吞吐量,提高了GPU资源的利用率。DeepSeek-V3的这些创新,为大模型训练提供了一条新的路径,使得更多机构和研究者能够参与到大模型的研发中来。
Manus图像生成代理:文本到视觉的AI任务执行
Manus推出了一款图像生成代理,该代理能够生成高质量的图像,并且理解用户的意图,与各种工具协作完成复杂的任务。这项技术为创意设计、游戏开发、市场营销等领域带来了新的可能性。

Manus图像生成代理能够智能地规划并与多个工具协作,从高层次的目标自主生成特定的图像。它支持多语言输入和上下文理解,适用于全球市场,提高了创作效率和灵活性。在创意设计领域,设计师可以利用该代理快速生成各种设计方案;在游戏开发领域,开发者可以利用该代理快速生成游戏素材;在市场营销领域,营销人员可以利用该代理快速生成广告图像。这项技术的应用前景非常广阔。
ElevenLabs SB-1无限声板:AI定制化音效控制面板
ElevenLabs发布了SB-1无限声板,这是一款基于AI的定制化音效控制面板工具,支持文本驱动的音效生成、多场景应用和创作者友好的功能,颠覆了传统的音效制作方法。

通过输入文本,SB-1无限声板能够生成高质量的逼真音效,打破了传统音效库的限制。它适用于直播、影视、表演等多种场景,增强了沉浸感和创作效率。此外,ElevenLabs还提供了对社区友好的政策,免费账户即可解锁所有功能,降低了技术门槛,受到了创作者的广泛欢迎。
MiniMax Speech-02:全球领先的TTS模型
MiniMax Audio的Speech-02系列语音模型,凭借其超高的语音逼真度和多语言支持,在两个权威榜单上击败了众多竞争对手,成为AI语音技术的新标杆。

Speech-02系列包括Speech-02-HD和Speech-02-Turbo两款模型,分别针对高保真和实时应用场景进行了优化,均表现出卓越的性能。其核心技术突破包括零样本克隆和多语言支持,支持超过30种语言,并具有动态停顿控制功能,增强了语音的自然度。Speech-02系列的架构创新结合了Flow-VAE和可学习编码器,不仅提高了语音的逼真度,还降低了延迟,使其适用于各种实际场景。这项技术的突破,为语音合成领域带来了新的发展机遇。
DeepL翻译服务升级:推出自研AI模型和写作助手
DeepL推出了新的API,用户可以通过该API访问其自研的语言模型和写作助手DeepL Write。DeepL Write不仅是一个文本生成工具,更是一个类似于Grammarly的写作辅助工具,专注于提高文本质量。此外,DeepL的语言模型提高了翻译的准确性,尤其是在复杂场景下。该公司强调数据安全,声明用户的内容不会被用于训练模型。

DeepL Write提供了写作辅助功能,专注于提高文本质量,适用于各种文本创作场景。它支持33种语言,并承诺保护用户数据安全,不使用用户内容来训练模型。这一举措,无疑将提升DeepL在语言服务市场的竞争力。
OpenAI引领AI工具流量市场,谷歌位居第二
在过去的两个月里,OpenAI的AI工具流量显著增长,占据了近80%的市场份额,而谷歌的Gemini流量保持稳定。DeepSeek和Grok则呈现出强劲的增长趋势。

OpenAI的AI工具流量飙升至1.9亿,占据了主导地位。谷歌Gemini的流量稳定在2500万,未能成为首选的AI产品。DeepSeek和Grok正在快速增长,挑战谷歌的市场地位。这一市场格局的变化,反映了AI工具市场的竞争日益激烈。
Llamafile 0.9.3:单文件运行大模型
Llamafile 0.9.3已经发布,支持Qwen3系列大型语言模型,通过单文件集成实现跨平台移植,极大地提高了部署效率。

单文件设计集成了llama.cpp和Cosmopolitan Libc,支持六个操作系统,大大简化了大型模型的部署。Llamafile 0.9.3由Qwen3驱动,性能出色,支持119种语言,适用于聊天机器人和代码生成等本地AI应用。其跨平台兼容性强,支持各种CPU架构,提供Web GUI和API接口,对开发者友好且开源。这项技术的突破,使得大模型的部署更加便捷。
SmolVLM:WebGPU驱动的实时网络摄像头AI
Hugging Face的SmolVLM多模态模型通过WebGPU技术实现了实时网络摄像头图像识别,无需服务器支持,所有计算都在用户设备上完成,增强了隐私保护,提高了AI应用部署的门槛。

SmolVLM模型轻量级,参数规模小,支持4/8位量化,适用于边缘设备。它是一个开源的里程碑,支持包括图像描述、对象识别和视觉问题解答在内的各种任务,展示了多模态AI的包容潜力。这一技术的应用,使得AI应用更加安全和高效。
Hugging Face推出免费MCP教程
Hugging Face推出了一个免费的MCP在线课程,旨在帮助开发者快速掌握AI上下文交互系统,降低AI Agent开发的复杂性,加速AI生态系统的发展。

MCP协议结构:详细解释了客户端-服务器架构和JSON-RPC2.0标准,快速理解核心组件。自托管MCP服务:通过Python或TypeScript示例轻松开发和集成外部资源。社区支持和实践导向:开源项目、Discord通信、真实案例作业辅助高效学习。这项课程的推出,将有助于更多开发者参与到AI Agent的开发中来。
复旦大学和腾讯合作发布DICE-Talk:说话人视频生成工具
DICE-Talk是由复旦大学和腾讯共同开发的视频生成工具。它通过身份-情感分离处理机制解决了面部表情变化的问题,实现了高度逼真和富有表现力的情感表达。
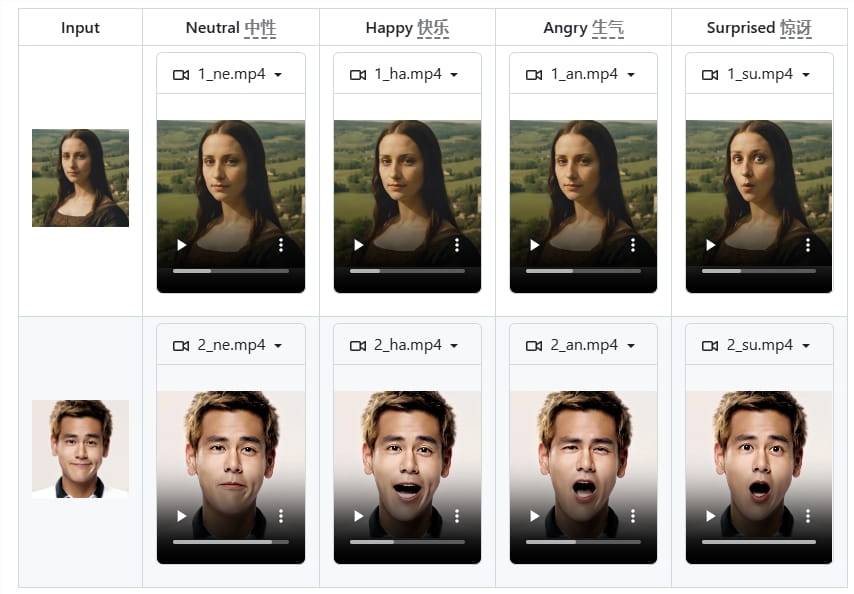
DICE-Talk的核心创新在于身份-情感分离处理机制,确保了角色外观在情感变化过程中的一致性。它可以分解身份信息并与情感生成协同工作,支持多种情感状态之间的自然过渡。用户只需上传图像和音频,即可生成与不同情感相对应的动态视频,操作简单直观。这项技术的应用,将为视频创作带来新的可能性。








