
在人工智能领域,每天都有新的突破和创新涌现。今天,我们为您带来最新的AI Daily,深入探讨昆仑万维天工超智能Agent、OpenAI核心API对MCP的支持、百度PaddlePaddle OCR 3.0开源等重要进展。这些技术不仅推动了AI技术的发展,也为各行各业带来了新的可能性。
一、百度PaddleOCR 3.0:OCR精度提升13%
百度Paddle团队正式发布PaddleOCR 3.0版本,这一版本在文本识别精度、多语言支持、手写识别以及文档解析能力上都实现了显著提升。更重要的是,PaddleOCR 3.0全面支持国产硬件,并引入了PP-OCRv5、PP-StructureV3和PP-ChatOCRv4等核心功能。

PP-OCRv5作为全场景文本识别模型,在五种类型的文本识别上实现了13%的精度提升,为无缝部署提供了有力保障。PP-StructureV3则专注于文档解析,强化了页面检测和表格识别能力,在高精度解析方面表现卓越。PP-ChatOCRv4结合了文心大模型,将关键信息提取精度提升了15%,能够处理复杂的文档。
二、昆仑万维天工超智能Agent:AI办公新革命
昆仑万维发布了基于自研Deep Research技术的AI Office智能Agent——天工超智能Agent。该Agent以强大的多模态内容生成能力和仅为OpenAI 40%的成本优势,引发了全球AI社区的广泛关注。

天工超智能Agent采用了多Agent架构,包含五个专家Agent和一个通用Agent,支持一站式生成各类办公内容。其核心技术Deep Research模型以低成本和高效率著称,在GAIA基准测试中,Deep Research模型取得了82.42分,超越了OpenAI Deep Research模型。此外,该Agent的开源框架和低成本部署策略,使其成为中小型企业和个人开发者的理想选择。
三、OpenAI核心API:简化智能Agent开发
OpenAI的Responses API新增了对MCP的支持,显著降低了AI模型与外部工具集成的难度。此外,OpenAI还推出了一系列功能升级,包括图像生成、代码解释器和优化的文件搜索功能。
通过支持MCP协议,OpenAI Responses API允许开发者以最少的代码连接外部工具,极大地提高了开发效率。MCP已成为AI智能Agent开发的行业标准,促进了跨平台协作和灵活性。
四、xAI Live Search API:AI实时获取信息
xAI正式推出了Live Search API,允许开发者使用Grok模型实时搜索来自各种数据源的信息,从而显著增强了AI应用程序的动态信息处理能力。目前,该API处于免费公开测试阶段,为开发者提供了强大的工具,以简化搜索逻辑和数据集成。

Live Search API支持自主搜索决策,Grok能够根据对话上下文自动判断是否需要搜索,无需人工干预。它还提供了多样化的数据来源,包括X平台、网页、新闻和RSS feed,确保信息的全面性和实时更新。此外,该API具有高度的灵活性和高效的集成能力,支持多种SDK,允许开发者轻松调整基础URL和API密钥,实现快速访问。
五、Google Sparkify:知识转化为动画短片
Google的实验性产品Sparkify利用Gemini和Veo模型,将复杂的知识点转化为直观的动画短片,适用于教育、科普和内容创作领域。

Sparkify通过动画短片直观地呈现复杂知识点,提高了理解效率。Gemini2.5和Veo2模型保证了高质量的动画视频制作。未来,Sparkify还将支持多语言扩展,覆盖更多地区和人群。
六、Mistral Devstral:高效代码AI模型
Mistral AI发布了全新的开源语言模型Devstral,该模型轻量级,专为代理AI软件开发而设计。Devstral具有出色的性能,支持本地操作,彰显了开源社区合作的力量。

Devstral拥有2400万参数,并以Apache2.0许可证发布,允许自由部署和商业化。在SWE-Bench验证中,Devstral的性能超越了大多数闭源模型,适用于本地和私有部署场景。作为Codestral系列的最新进展,Devstral支持跨文件上下文理解,适用于复杂的软件开发任务。
七、Video Ocean:2K/4K HDR视频生成工具
lucidtech于5月21日推出了新的AI视频生成工具Video Ocean,支持快速生成高质量视频,并提供各种特效和功能,价格完全免费,引发了创作热潮。

Video Ocean支持在5-10秒内生成2K/4K HDR高质量视频,适用于各种场景创建。它还提供了大量的模板和特效,如Laugh、Cakeify等,使初学者也能轻松创建专业级视频。价格仅为Keling 2.0的1/10,完全免费,受到了各用户群体的积极反馈。
八、Google SynthID Detector:识别AI生成内容
Google推出了一款名为SynthID Detector的新工具,旨在帮助用户检测内容是否由其AI工具生成。该工具可以识别AI生成的内容,并突出显示标有SynthID水印的部分,目前正向早期测试者提供。
SynthID Detector是一种用于识别AI生成内容的新工具,支持图像、文本、音频和视频。该工具可以自动扫描上传的内容,搜索并突出显示SynthID水印。目前,该工具仅向早期测试者提供,未来将逐步推广到更多用户。
九、Google NotebookLM:AI辅助笔记工具
在过去六个月中,Google的AI辅助知识管理工具NotebookLM的月访问量增长率达到了56%。凭借其创新的“音频概述”、多语言支持和多样化的应用场景,NotebookLM受到了广泛关注。
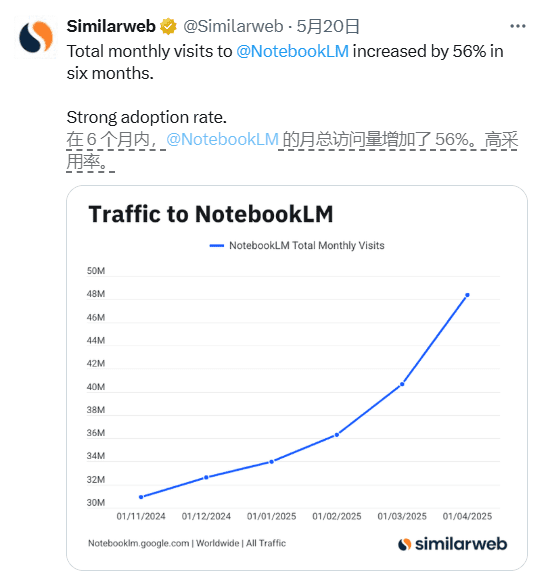
NotebookLM的月访问量增长了56%,成为AI应用领域的一匹黑马。它支持50多种语言的播客内容生成,打破了语言障碍,提升了用户体验。适用于学生、研究人员和内容创作者,在学术和娱乐领域均得到高效应用。
十、SiliconFlow:升级推理模型API
SiliconFlow升级了其推理模型API,将最大上下文长度显著增加到128K,从而增强了模型的推理能力和输出质量。它还引入了对思维链和回复内容长度的独立控制,允许开发者更灵活地调整模型性能。
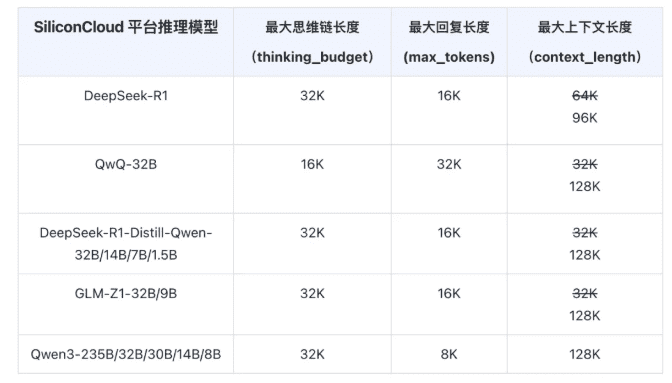
SiliconFlow支持最大128K的上下文长度,显著增强了模型的思维深度和输出完整性。引入了对思维链和回复内容长度的独立控制,加强了开发者对模型行为的精确控制。当达到长度限制时,模型输出将被截断并标记原因,确保使用的透明度。
十一、Google DeepMind Lyria2:AI音乐生成模型
Lyria2是Google DeepMind发布的最新音乐生成模型。它具有高保真音质、实时交互能力和多风格适应性,为音乐创作带来了革命性的变化。
Lyria2能够生成48kHz立体声音频,精确捕捉音乐细节,适用于专业音乐制作和商业项目。Lyria RealTime功能允许用户即时调整音乐风格、节奏等,激发创作灵感。集成到Music AI Sandbox工具包中,支持文本、乐谱或音频片段输入,覆盖各种音乐风格。
十二、多模态大模型MMaDA:AI学会“跨维度思考”
MMaDA是由多所顶尖大学和企业联合开发的多模态大模型,凭借其独特的统一扩散架构、混合长链思维微调和统一强化学习算法,实现了文本、图像和其他模态之间的无缝切换和深度推理,性能优于GPT-4等现有模型。

MMaDA的统一扩散架构打破了传统多模态模型的障碍,实现了对文本、图像和其他数据类型的无缝处理。通过跨模态推理对齐,使AI具有深度思考能力。统一强化学习算法UniGRPO平衡了推理和生成任务,全面提升了AI性能。
十三、Microsoft Magentic-UI:Web智能Agent
Magentic-UI的设计理念是以人为本,强调透明性和可控性,为用户提供安全感。这款工具不仅提高了工作效率,还为开发者提供了一个强大的开源平台。

Magentic-UI是一个以人为中心的AI智能Agent研究原型,通过Web浏览器协助用户实时完成复杂任务。它引入了协作规划和行为保护功能,确保用户在自动化过程中保持控制,同时确保安全性和灵活性。通过多Agent协作,支持计划学习,从历史任务中优化未来任务的自动化效率。
十四、Framer:AI驱动的网站构建
Framer在I/O2025上推出了一套新的AI功能,包括Wireframer、Workshop、Advanced Analytics和Vectors2.0。这些功能通过AI驱动,显著降低了网站创建的成本和复杂性,包括Web布局生成、交互组件设计、矢量绘图升级和高级分析工具。

这些创新技术正在重塑我们与AI互动的方式,预示着一个更加智能、高效和创造性的未来。从OCR精度的提升到多模态Agent的涌现,再到AI辅助工具的普及,人工智能正在以前所未有的速度渗透到我们生活的方方面面。这些进展不仅为开发者提供了更强大的工具,也为各行各业带来了无限的可能性。未来,随着技术的不断进步和创新,我们有理由相信,人工智能将继续引领我们走向更加美好的未来。








