
在人工智能领域,我们似乎一直被“越大越好”的观念所束缚。巨大的模型参数、海量的训练数据,仿佛成为了衡量模型性能的唯一标准。然而,Hugging Face 近期的研究却打破了这一固有认知,向我们展示了小模型蕴藏的巨大潜力。他们发现,通过延长模型的“思考时间”,即使是规模较小的模型,也能在复杂任务中展现出惊人的性能,甚至超越那些参数巨大的“巨无霸”模型。
大模型并非万能,小模型也有春天
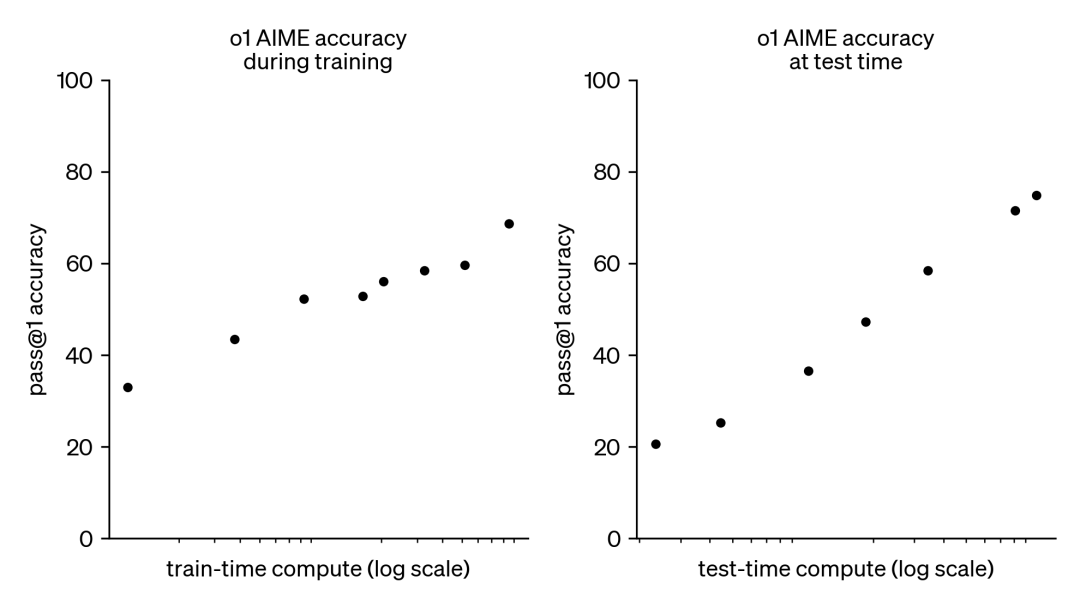
长期以来,大语言模型的发展一直依赖于训练时计算的扩展。我们不断增加模型的参数规模,投入巨额的计算资源进行预训练,以此来提升模型的性能。这种模式虽然有效,但其成本也日益高昂,动辄数十亿美元的投入让许多研究机构望而却步。
面对如此巨大的资源消耗,人们开始将目光转向另一种互补的方法——测试时计算扩展。这种方法不再依赖于庞大的预训练预算,而是通过动态的推理策略,让模型在更难的问题上“思考更长时间”。OpenAI 的 o1 模型就是这种策略的杰出代表。随着测试时计算量的增加,它在困难的数学问题上表现出了持续的进步。
Hugging Face的逆向工程:开源小模型逆袭之路
虽然我们不清楚 o1 模型的具体训练方法,但DeepMind的研究表明,通过迭代自我改进或使用奖励模型在解决方案空间上进行搜索等策略,可以实现测试时计算的最佳扩展。通过自适应地分配测试时计算资源,较小的模型可以与较大、资源密集型模型相媲美,有时甚至超越它们。特别是在内存受限、硬件资源不足以运行较大模型的情况下,扩展测试时计算显得尤为重要。
然而,这种极具前景的方法一直由闭源模型所演示,缺乏实现细节和代码。Hugging Face 在过去的几个月里深入研究,试图对这些结果进行逆向工程和复现。他们成功地揭示了其背后的技术细节,并将其开源,为小模型的崛起铺平了道路。
核心技术揭秘:DVTS与计算最优扩展
Hugging Face 的研究主要围绕以下三个方面展开:
- 计算最优扩展 (Compute-Optimal Scaling): 通过实现 DeepMind 的技巧,Hugging Face 成功提升了开源模型在数学方面的能力。
- 多样性验证器树搜索 (DVTS): 这是为验证器引导树搜索技术开发的扩展。这种简单高效的方法提高了答案的多样性,并在测试时计算预算较大时提供了更好的性能。
- 搜索和学习工具包: Hugging Face 开发了一个轻量级的工具包,用于使用 LLM 实现搜索策略,并使用 vLLM 加速推理过程。
那么,计算最优扩展在实践中效果如何呢?在Hugging Face的实验中,当给予足够“思考时间”时,规模较小的 1B 和 3B Llama Instruct 模型在具有挑战性的 MATH-500 基准上,超越了比它们大得多的 8B 和 70B 模型。这一结果无疑令人震惊,也引发了人们对于小模型潜力的重新审视。
测试时计算扩展策略:三大核心方法
Hugging Face 的研究表明,测试时计算扩展主要有两种策略:
- 自我改进: 模型通过在后续迭代中识别和纠错来迭代改进自己的输出。
- 针对验证器进行搜索: 生成多个候选答案,并使用验证器选择最佳答案。
Hugging Face 专注于基于搜索的方法,并提出了以下三种核心策略:
- Best-of-N: 为每个问题生成多个响应并进行评分,然后选择奖励最高的答案。
- 集束搜索: 探索解决方案空间的系统搜索方法,通常与过程奖励模型(PRM)结合使用,以优化问题解决中间步骤的采样和评估。
- 多样性验证器树搜索 (DVTS): 这是 Hugging Face 开发的集束搜索扩展,旨在提高解决方案的多样性,并在测试时计算预算较大时提高性能。
实验设置:小模型如何一步步超越大模型
Hugging Face 的实验设置主要分为以下几个步骤:
- 问题输入: 向 LLM 提供一个数学问题。
- 部分解生成: 让 LLM 生成 N 个部分解,例如,推导过程中的中间步骤。
- PRM评分: 使用过程奖励模型(PRM)对每个步骤进行评分,PRM 估计每个步骤最终达到正确答案的概率。
- 搜索策略应用: 根据选择的搜索策略,最终候选解决方案将由 PRM 排序以产生最终答案。
Hugging Face 使用以下开源模型和数据集进行实验:
- 模型: meta-llama/Llama-3.2-1B-Instruct (主要模型)
- 过程奖励模型(PRM): RLHFlow/Llama3.1-8B-PRM-Deepseek-Data
- 数据集: MATH-500 子集
从多数投票到DVTS:性能的逐步提升
Hugging Face 从一个简单的基线开始,然后逐步结合其他技术来提高性能:
- 多数投票: 选择出现频率最高的答案。结果表明,多数投票比贪婪解码基线有显著的改进,但其收益在大约 N=64 generation 后开始趋于平稳。
- Best-of-N: 使用奖励模型来确定最合理的答案。加权的 Best-of-N 始终优于普通的 Best-of-N,但仍然无法达到 Llama 8B 模型的性能。
- 集束搜索: 通过允许 PRM 评估中间步骤的正确性,集束搜索可以在流程早期识别并优先考虑有希望的路径。在 N=4 的测试时预算下,集束搜索实现了与 N=16 时 Best-of-N 相同的准确率,即计算效率提高了 4 倍!
- 多样性验证器树搜索(DVTS): DVTS 在 N 较大时提高了简单 / 中等问题的性能,而集束搜索在 N 较小时表现最佳。
计算 - 最优扩展:因材施教的策略
有了各种各样的搜索策略,一个自然的问题是哪一个是最好的?Hugging Face 借鉴 DeepMind 的论文,提出了计算 - 最优扩展策略,该策略可以选择搜索方法和超参数,以便在给定的计算预算 N 下达到最佳性能。
该策略根据问题难度分配测试时的计算资源,例如,对于较简单的问题和较低的计算预算,最好使用 Best-of-N 等策略,而对于较难的问题,集束搜索是更好的选择。
小模型的力量:3B模型超越70B巨头
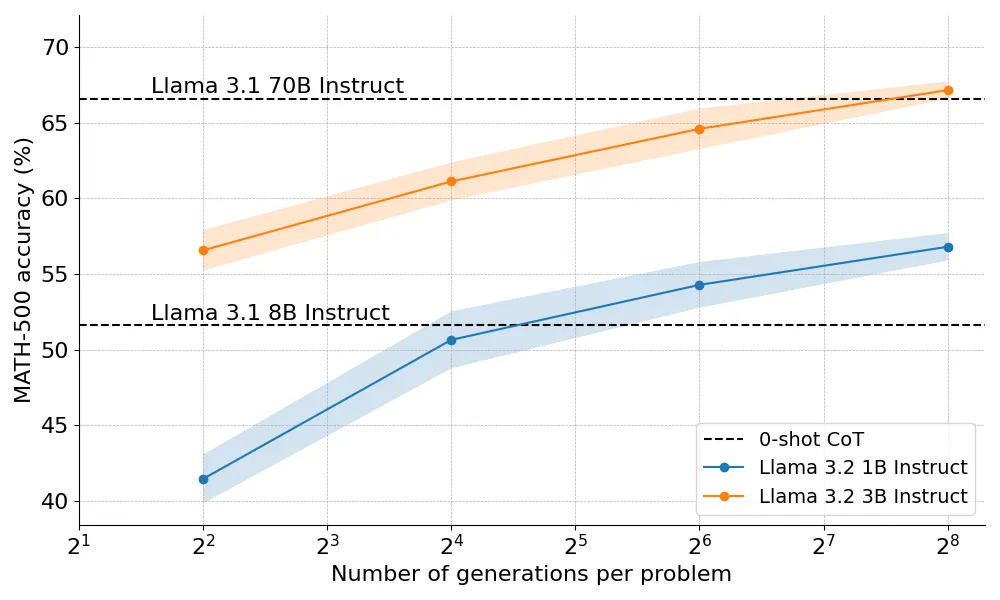
Hugging Face 将计算 - 最优的方法扩展到 Llama 3.2 3B Instruct 模型,结果显示,3B 模型的性能竟然超过了 Llama 3.1 70B Instruct,后者是前者大小的 22 倍!这一结果再次证明了小模型的巨大潜力。
未来展望:小模型发展的新方向
Hugging Face 的研究为我们打开了一扇新的大门,让我们看到了小模型无限的可能。未来,我们可以关注以下几个发展方向:
- 强验证器: 开发更稳健和通用的验证器。
- 自我验证: 实现模型自主验证自己的输出。
- 将思维融入过程: 在生成过程中融入明确的中间步骤或思维。
- 搜索作为数据生成工具: 使用搜索生成高质量的训练数据集。
- 调用更多的 PRM: 为不同领域开发和共享更多 PRM。
总结:小模型也可以很强大
Hugging Face 的研究表明,通过延长思考时间,小模型也能在复杂任务中展现出惊人的性能,甚至超越那些参数巨大的“巨无霸”模型。这一发现不仅颠覆了我们对大模型的盲目崇拜,也为小模型的发展指明了新的方向。未来,我们有理由相信,小模型将在人工智能领域发挥越来越重要的作用。
想体验一下最新的AI技术吗?chatTools:https://chat.chattools.cn 提供了包括o1推理模型、GPT4o、Claude和Gemini等多种模型,欢迎您来探索。








