
在人工智能领域,每天都有新的突破和创新涌现。本文将深入探讨近期发布的几项重要AI技术进展,涵盖语音合成、视频生成、数字人模型以及搜索引擎的智能化升级,同时分析这些技术对未来产业发展的影响。
一、开源端到端语音大模型Step-Audio-AQAA
语音交互是人机交互的重要方式。近日,一款名为Step-Audio-AQAA的开源端到端语音大模型引起了广泛关注。该模型能够直接从原始音频输入生成自然流畅的语音输出,极大地提升了人机交互的体验。Step-Audio-AQAA模型的核心在于其独特的架构设计,它由三个主要模块组成:双码本音频标记器、骨干LLM(大型语言模型)和神经声码器。
双码本音频标记器负责将输入的原始音频转换成模型可以理解的离散表示。这一过程类似于将连续的音频信号“翻译”成离散的“词汇”,使得模型能够更好地处理和学习音频中的信息。骨干LLM是模型的核心,它负责学习音频标记之间的关系,并生成与输入音频相对应的文本序列。这个LLM通常采用Transformer架构,经过大量的语音数据训练,具备强大的语言建模能力。神经声码器则负责将LLM生成的文本序列转换成最终的语音输出。声码器利用神经网络技术,能够生成高质量、自然流畅的语音,使得整个语音合成过程更加逼真。
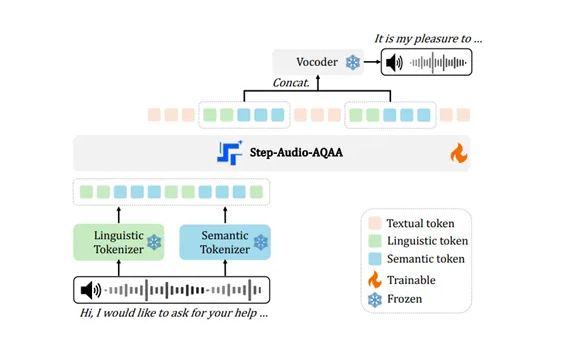
Step-Audio-AQAA模型的优势在于其端到端的训练方式。传统的语音合成系统通常需要多个独立的模块,例如声学模型、语言模型和声码器,这些模块需要分别训练,并且模块之间的优化目标可能不一致。而Step-Audio-AQAA模型将所有模块整合到一个统一的框架中,通过端到端的训练方式,可以直接优化整个系统的性能。这种端到端的训练方式可以避免模块之间的误差传递,提高语音合成的质量和自然度。
二、百度“绘想”平台与MuseSteamer:AI视频生成的革新
视频内容的需求日益增长,如何高效、便捷地生成高质量的视频成为了一个重要的挑战。百度近期发布的“绘想”平台与MuseSteamer,为视频生成领域带来了新的解决方案。MuseSteamer是百度“绘想”平台的核心组件,它通过生成式AI和多模态技术,提供全面的视频生成解决方案,满足搜索、广告等多种场景的需求。
MuseSteamer具备强大的可控性和高性价比。用户只需上传一张图片,即可生成专业级的视频内容,极大地简化了视频制作流程。这一功能的实现依赖于MuseSteamer强大的图像理解和视频生成能力。模型可以分析输入图片的语义信息,例如场景、物体、人物等,并根据这些信息生成与图片内容相关的视频。此外,MuseSteamer还支持用户对视频内容进行精细的控制,例如调整视频的风格、节奏、配乐等,使得用户可以根据自己的需求定制视频内容。
MuseSteamer支持音视频一体化生成,实现电影级的制作效果。模型可以自动为视频添加合适的背景音乐和音效,使得视频内容更加生动有趣。此外,MuseSteamer还支持连续10秒的动态视频生成,进一步提升了创作效率。用户可以使用MuseSteamer快速生成各种类型的视频内容,例如产品宣传片、广告短片、教育视频等,从而降低视频制作的成本和门槛。
三、OmniAvatar:音频驱动全身数字人模型的突破
数字人技术在营销、教育、娱乐等领域具有广泛的应用前景。浙江大学与阿里巴巴联合发布的OmniAvatar模型,在音频驱动数字人技术上取得了重大突破。OmniAvatar模型能够生成自然流畅的全身数字人视频,尤其在歌唱场景中表现出色。该模型支持通过文本提示精细控制生成细节,并具备多场景应用潜力,为各行各业带来了创新可能。
OmniAvatar模型的核心在于其音频驱动技术。模型可以根据输入的音频信号,自动生成与音频内容相匹配的数字人动作和表情。这一技术的实现依赖于深度学习模型对音频和视频数据的学习。模型通过大量的音频和视频数据训练,学习音频信号与数字人动作之间的映射关系。在生成数字人视频时,模型首先分析输入的音频信号,提取音频中的特征,例如音调、节奏、情感等,然后根据这些特征生成相应的数字人动作和表情。为了提高数字人视频的真实感和自然度,OmniAvatar模型还采用了多种先进的渲染技术,例如光照模型、纹理映射、阴影效果等。这些技术可以使得数字人视频更加逼真,从而提升用户的观看体验。
OmniAvatar模型的另一个重要特点是其支持文本提示控制细节。用户可以通过输入文本提示,例如“微笑”、“点头”、“挥手”等,来控制数字人的动作和表情。这一功能使得用户可以更加灵活地定制数字人视频的内容。此外,OmniAvatar模型还具备多场景应用潜力。它可以应用于各种场景,例如在线教育、虚拟直播、智能客服等。在在线教育场景中,OmniAvatar模型可以用于生成虚拟教师,为学生提供个性化的教学服务。在虚拟直播场景中,OmniAvatar模型可以用于生成虚拟主播,为观众提供更加生动有趣的直播内容。在智能客服场景中,OmniAvatar模型可以用于生成虚拟客服,为用户提供更加人性化的服务。
四、百度搜索的智能化升级
搜索引擎是人们获取信息的重要工具。为了提升用户的搜索体验和创作能力,百度搜索进行了十年来最大规模的改版。此次改版引入了智能框、百看和AI助手等创新功能,标志着搜索引擎正在向智能化方向发展。
智能框是百度搜索此次改版的核心功能之一。它支持千字输入,增强了多模态交互能力。用户可以通过智能框输入文字、语音、图片等多种形式的信息,从而更加方便地表达自己的搜索需求。此外,智能框还具备智能推荐功能,可以根据用户的输入内容,推荐相关的搜索结果和应用。百看功能是百度搜索此次改版的另一个亮点。它支持混合内容输出和智能体服务。用户可以通过百看功能浏览各种类型的资讯内容,例如新闻、视频、文章等。此外,百看功能还支持智能体服务,可以为用户提供个性化的推荐和定制服务。AI助手是百度搜索此次改版的又一重要功能。它新增了视频通话功能,提升了创作与搜索能力。用户可以通过AI助手进行视频通话,从而更加方便地获取信息和解决问题。此外,AI助手还具备创作能力,可以帮助用户生成各种类型的文本内容,例如文章、摘要、评论等。
五、xAI的Grok4及Grok4Code:下一代AI模型的展望
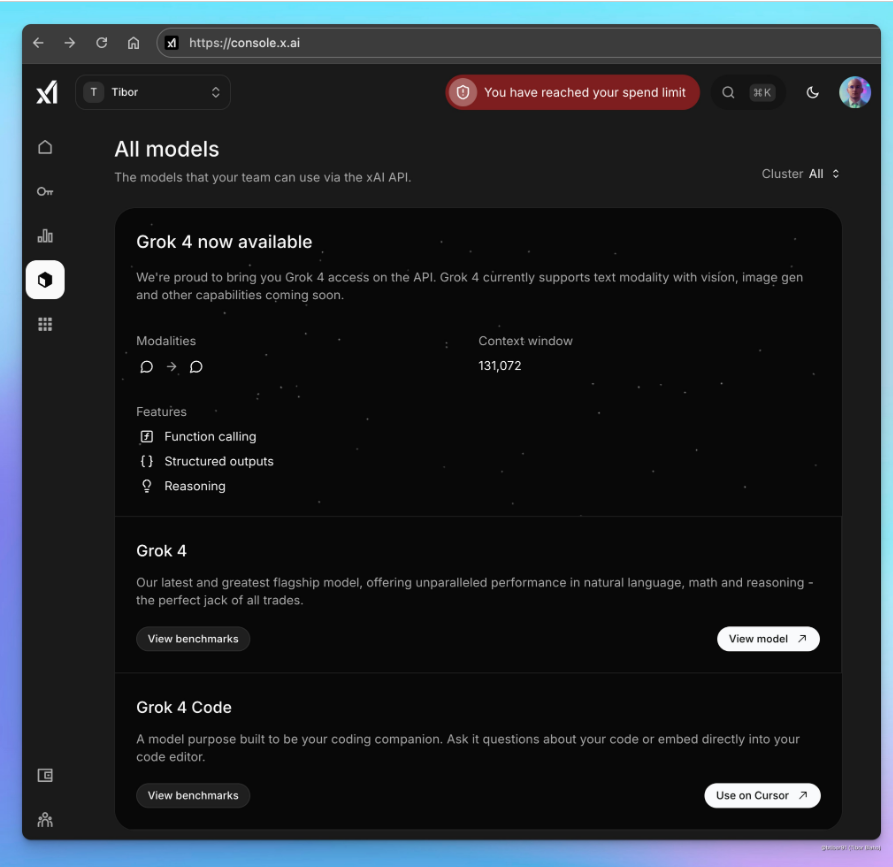
xAI在开发者控制台中新增了对Grok4及Grok4Code的引用,预示着下一代人工智能模型的发布即将来临。Grok4被描述为‘全能型AI的巅峰之作’,而Grok4Code则专注于编程优化。这两款模型的引用表明其公开发布已进入最后准备阶段。
Grok4作为xAI的旗舰模型,专注于自然语言处理、数学推理和综合推理能力的提升。Grok4Code专为编程优化,计划与代码编辑器无缝整合,提高开发效率。xAI通过API提供Grok4访问权限,未来将扩展至多模态能力,降低开发者整合门槛。
六、Gemini Live的升级:智能生活触手可及
Gemini Live的升级通过与Google生态系统的深度整合,提升了用户的智能交互体验,同时兼顾了隐私保护,展现了其在智能助手领域的潜力。Gemini Live将与Google Maps、Calendar等应用深度整合,提升跨应用操作效率。Gemini Live支持多模态交互,如扫描信息自动生成任务或日程,增强实用性。Google注重隐私保护,用户可自主管理权限以确保数据安全。
七、AI外卖配送车的应用:效率的提升
武汉推出全国首辆搭载AI技术的外卖配送车——智音车,配送效率提升显著,标志外卖行业的技术革新。智音车在武汉首发,配备北斗双频芯片,提升外卖配送效率。外卖小哥配送效率提升30%,日均多赚80元。定位精度高达1米,智音车技术前景广阔。
八、Anthropic的崛起:AI市场的竞争加剧
文章指出,AI独角兽Anthropic年化收入已达40亿美元,较年初增长近四倍,同时其竞争对手Cursor也在积极扩展业务,双方竞争加剧。Cursor依赖Anthropic的技术,并通过引入高管和创新提升竞争力。人工智能技术的快速发展推动了编程工具的需求增长,各公司都在争夺市场份额。
总结
人工智能技术的快速发展正在深刻地改变着各行各业。从语音合成到视频生成,从数字人模型到搜索引擎,AI技术的创新正在不断涌现。这些技术的应用将极大地提升生产效率,改善用户体验,并为各行各业带来新的发展机遇。然而,AI技术的发展也带来了一些挑战,例如数据安全、隐私保护、伦理道德等。我们需要在发展AI技术的同时,充分考虑这些挑战,并采取相应的措施加以解决,以确保AI技术能够为人类带来福祉。








