
在人工智能(AI)技术飞速发展的今天,内容创作领域正经历着前所未有的变革。各大AI巨头纷纷入局,试图通过免费或低成本的方式获取网络内容,以训练其AI模型。然而,这种“免费午餐”的时代或许即将终结。互联网基础设施巨头Cloudflare率先站出来,推出了一项名为“Pay Per Crawl”的实验性产品,旨在改变AI爬虫随意抓取网络内容的现状,为内容创作者争取应有的权益。
Cloudflare,这家被誉为“赛博菩萨”的公司,掌握着全球约20%的网络流量。其推出的“Pay Per Crawl”功能,允许网站内容创作者选择是否允许AI爬虫访问其内容,并根据访问次数收费,或者直接封锁访问。这一举措被视为对AI巨头的一次重要制约,旨在建立一个全新的AI时代内容分发和变现模式。
AI巨头的“免费午餐”时代
长期以来,互联网上的网页内容大多默认是公开可爬取的。搜索引擎如谷歌、Bing等通过为网站带来流量,使得网站可以通过广告或销售订阅等方式变现。然而,随着AI时代的到来,传统搜索流量骤降,内容创作者的收益也随之减少。AI公司利用全网内容作为训练燃料,却几乎不给创作者任何回报。用户直接在AI聊天机器人中获取答案,而非通过点击网站链接,这进一步加剧了内容创作者的困境。
Cloudflare的数据显示,谷歌的爬虫大约每6至7次抓取给网站带回1次点击,而OpenAI则是1500次才换来1次跳转,Anthropic的比例更是高达73300次换1次。这意味着,传统的“内容换流量”模式已经失效。AI巨头们消耗了海量网站内容,却不提供相应的流量,这种失衡的局面让内容生产者难以维持。
此外,AI公司爬取数据还面临着版权问题。近年来,AI巨头因涉嫌“偷内容”训练大模型而面临全球范围的版权诉讼。为了解决这些问题,Cloudflare推出了“Pay Per Crawl”,旨在建立一个“按次付费爬取”的市场。
“Pay Per Crawl”的技术实现
Cloudflare的技术优势在于其全球CDN网络。通过在全球300多个城市部署节点,Cloudflare承载了约20%的Web流量,这使得它能够方便地充当“中介”角色。“Pay Per Crawl”建立在其全球CDN网络的中间层,可以在访问请求到达源站之前识别和处理AI爬虫。站长可以在Cloudflare后台设定三种模式:允许、收费、封锁。
默认情况下,所有新加入Cloudflare的网站都会封锁AI爬虫,除非站长主动允许。只有与Cloudflare建立合作关系的AI公司才能参与支付机制,否则将被封锁。当AI爬虫向付费URL发起请求但尚未付费时,Cloudflare会返回HTTP 402 Payment Required状态码,提示需要支付。AI爬虫可以在请求中附带支付信息,一旦价格匹配,Cloudflare就会放行并返回200 OK状态码,同时自动结算。
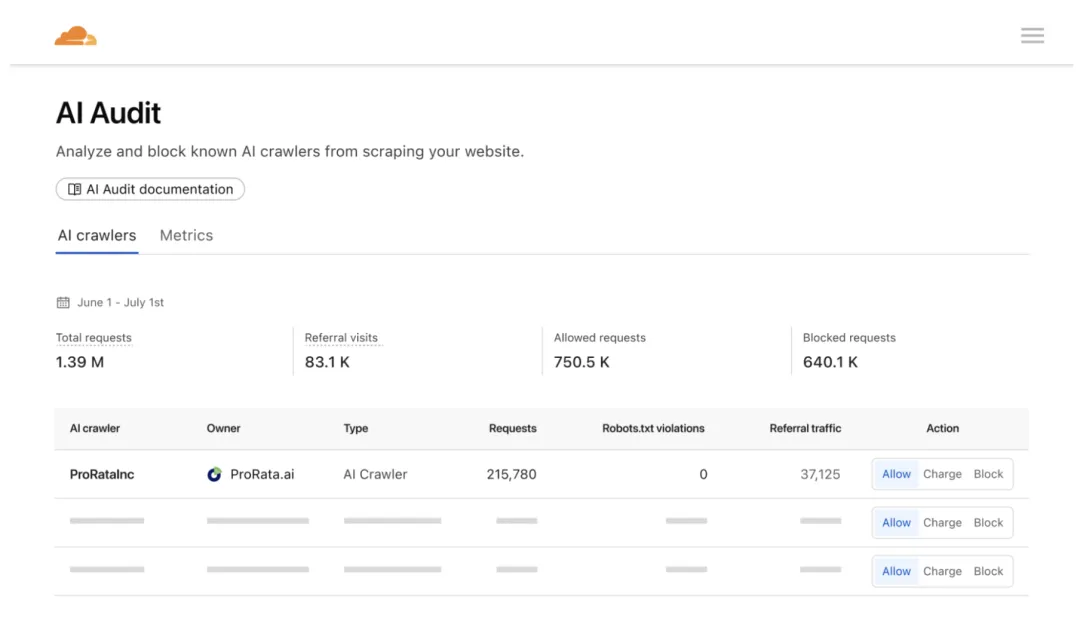
更重要的是,Cloudflare要求AI公司注册密钥,并使用数字签名来验证身份,以防止“山寨爬虫”冒充合规者逃避支付。这种方式改变了过去依赖robots.txt的“软约束”,将其转变为“硬闸门”。
然而,据Cloudflare称,目前排名前10000的域名中,只有约37%拥有robots.txt文件。这意味着,许多网站尚未对爬虫进行任何限制。

要参与Cloudflare的爬取付费市场,爬取方和被爬取方都需要开设Cloudflare账户。目前,“Pay Per Crawl”仍处于内测阶段,仅部分大型出版商参与,如BuzzFeed、《大西洋月刊》和《财富》等。Cloudflare还在持续公开征集有意向的内容创作者和抓取者。
“Pay Per Crawl”的未来
Cloudflare对“Pay Per Crawl”的未来充满信心。他们认为,出版商或其他机构可以针对不同内容类型收取不同费用,或者根据AI应用的用户数量进行动态定价,甚至可以根据训练、推理、搜索等不同领域引入更细粒度的定价策略。
他们还认为,按次付费爬虫的真正潜力或许会在Agent智能代理的世界中显现。例如,用户可以委托智能代理整理最新的癌症研究、法律简报,或者寻找最佳餐厅,并为智能代理提供预算,用于获取最有价值的内容。
对互联网的影响
从经济层面来看,“Pay Per Crawl”可能是AI和广大内容创作者“重新谈判分账”的开端。过去,只有头部大媒体能够与AI公司谈判授权,而绝大多数中小网站、论坛甚至个人作者都被“默默爬走”。Cloudflare的方案可以将这种议价能力普及到更广泛的网站。
据Cloudflare团队称,他们与新闻机构、出版商和大型社交媒体平台进行了数百次对话,他们一致“希望允许AI爬虫访问其内容,但希望获得报酬。”对于支持者来说,“Pay Per Crawl”模式在理念上是“公平”的:创作者有了收入,AI公司也避免了法律风险,长远来看能够推动整个产业走向更合规的内容许可。

然而,AI公司可能对此并不欢迎。互联网数据不再免费,抓取新内容需要付费,这意味着算力之外的成本增加。但另一方面,这也可能抑制滥抓取,促使AI模型开发者在数据上更有选择性。
Matthew Prince认为,AI引擎就像一块瑞士奶酪,真正能够填补这块奶酪孔洞的全新原创内容,比占据网络大部分版面的重复性、低价值内容更有价值。他认为,流量一直以来都无法准确衡量内容的价值。如果能够开始对内容进行评分和评估,不是根据它产生了多少流量,而是根据它对知识的促进程度,那么不仅可以帮助AI引擎更快地进步,而且有可能促进高价值内容创作的新黄金时代。
然而,数字权利倡导者可能会提出疑问:小型AI创业团队、研究者、开源社区能否承担这样的数据成本?学术研究、公益存档这些“良性爬虫”是否会寸步难行,只能访问有限、低价值的数据源?在一个广告收益下滑、流量成本高涨的现实中,会有多少网站愿意无偿开放给AI爬虫?这是否会成为“封闭化”的开始,让互联网失去其自由与共享精神?如果全网都默认封锁收费,这是否会无意中加剧“大厂垄断”?
“Pay Per Crawl”模式在试图解决AI吸血内容却不反哺问题的同时,也有可能在无意中加高AI创新的门槛,回到版权保护与知识开放的老命题。当然,Cloudflare只是给网站更多自主权。网站所有者完全可以选择对公益、非营利项目继续免费开放。权力仍然在创作者手中。
虽然Cloudflare的“Pay Per Crawl”看起来只是一个CDN产品的新功能,但从某种意义上说,它可能成为互联网走到一个分岔口的信号。在搜索时代,内容的价值是通过用户访问转化为广告收益。但在AI时代,用户可能根本不会再点进网站——所有答案都在聊天机器人里总结生成。是继续让AI大模型免费挖掘网络内容,还是在数据获取上回归“互惠”原则,让创作者获得应有的补偿?
这个早期实验可能在为一个新的AI时代数据经济形态铺路。无论成败如何,它的立场很明显:AI不能无限透支创作者的耐心,并在“开放”的名义下把人的劳动变成免费的燃料。网络正在发生变革,其商业模式也将随之改变。在这个过程中,有机会从过去的30年里学到好的地方,让它在未来变得更好。








