
NVIDIA DiffusionRenderer:AI模型引领视频到3D场景的革新
人工智能技术的飞速发展,推动着视频生成技术日新月异。从最初的模糊图像到如今逼真度极高的视频内容,AI在视频领域的应用已经取得了显著的进步。然而,长期以来,对生成视频的控制和编辑能力的不足,一直是制约其发展的瓶颈。最近,NVIDIA及其合作伙伴推出了一项名为DiffusionRenderer的创新研究,为解决这一难题带来了曙光。
DiffusionRenderer是一项突破性的技术,它不仅能够生成视频,还能深入理解和操作视频中的3D场景。通过将生成与编辑功能巧妙地结合,DiffusionRenderer极大地释放了AI驱动内容创作的潜力。与传统的物理基础渲染(PBR)技术相比,DiffusionRenderer在生成高度逼真视频的同时,还能够对场景进行灵活的编辑,从而突破了传统技术的局限。
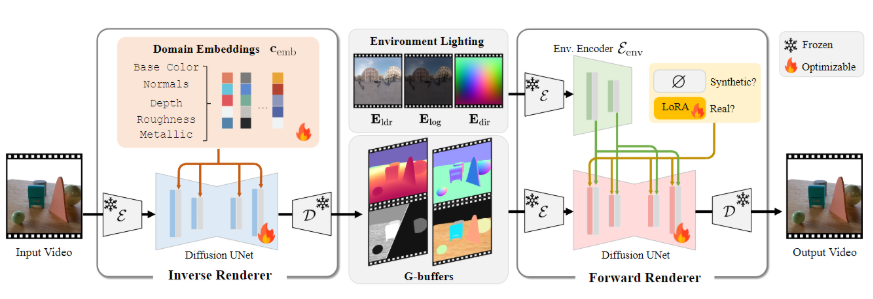
DiffusionRenderer模型的核心在于其独特的双神经渲染器架构。首先,神经逆渲染器负责分析输入的视频,从中提取场景的几何和材质属性,并生成相应的数据缓冲区。然后,神经前向渲染器将这些数据与所需的光照条件相结合,生成高质量的逼真视频。这两个渲染器协同工作,使得DiffusionRenderer在处理现实世界数据时表现出强大的适应能力,能够应对各种复杂的场景和光照条件。
为了训练DiffusionRenderer模型,研究团队设计了一套独特的数据策略。他们构建了一个包含15万个视频的庞大合成数据集,作为模型学习的基础。此外,他们还利用一个包含10,510个真实世界视频的数据集,自动生成场景属性标签,从而使模型能够更好地适应真实视频的特性。这种数据策略有效地提高了模型的泛化能力和鲁棒性。

DiffusionRenderer在多项任务的对比测试中表现出色,全面超越了其他同类方法。它不仅能够在复杂场景中生成更逼真的光影效果,还能在反向渲染时准确估计场景的材质属性。这些优异的表现证明了DiffusionRenderer在视频渲染和编辑领域的领先地位。
DiffusionRenderer的实际应用潜力巨大。用户可以通过该技术进行动态光照调整、材质编辑以及无缝对象插入等操作。只需提供一段视频,用户便可轻松实现对场景的修改和再创作。这项技术的发布标志着视频渲染和编辑领域的一次重大飞跃,它将赋予创作者和设计师更大的创作自由,推动视频内容的创新和发展。
DiffusionRenderer的技术原理
DiffusionRenderer的核心在于其创新的双神经渲染器架构,该架构由神经逆渲染器和神经前向渲染器组成。这种架构的设计灵感来源于传统的渲染流程,但又通过深度学习技术赋予了其更强大的功能和灵活性。
神经逆渲染器:场景理解的基石
神经逆渲染器的主要任务是从输入的视频中提取场景的几何和材质属性。这一过程可以被视为对传统渲染流程的逆向操作,即从最终的图像反推出场景的各种参数。神经逆渲染器通过深度学习模型,学习从像素信息到3D场景表示的映射关系。具体而言,它可以估计场景的深度、法线、反射率、粗糙度等属性,并将这些属性存储在数据缓冲区中。这些数据缓冲区包含了场景的关键信息,为后续的渲染过程提供了基础。
神经逆渲染器的训练需要大量的数据。为了提高模型的泛化能力,研究团队构建了一个包含15万个视频的合成数据集。这些视频涵盖了各种不同的场景和光照条件,可以帮助模型学习到更鲁棒的特征表示。此外,研究团队还利用真实世界的数据来微调模型,以提高其在实际应用中的性能。
神经前向渲染器:逼真视频的缔造者
神经前向渲染器的作用是将神经逆渲染器提取的场景属性与所需的光照条件相结合,生成高质量的逼真视频。这一过程与传统的渲染流程类似,但神经前向渲染器采用了深度学习模型来模拟光照和材质的相互作用。它可以根据场景的几何形状、材质属性和光照条件,计算出每个像素的颜色值,从而生成逼真的图像。
神经前向渲染器的训练也需要大量的数据。研究团队利用合成数据和真实数据来训练模型,以提高其在各种场景下的渲染效果。此外,研究团队还采用了一些先进的渲染技术,如光线追踪和全局光照,来提高生成视频的真实感和细节。
双神经渲染器的协同工作
神经逆渲染器和神经前向渲染器协同工作,共同完成了从视频到3D场景再到视频的转换过程。神经逆渲染器负责理解场景,提取场景属性;神经前向渲染器负责渲染场景,生成逼真视频。这两个渲染器相互配合,使得DiffusionRenderer能够实现对视频的编辑和再创作。
DiffusionRenderer的应用场景
DiffusionRenderer作为一项创新的视频渲染和编辑技术,具有广泛的应用前景。它可以应用于各种不同的领域,为用户带来全新的创作体验。
动态光照调整
DiffusionRenderer可以实现对视频中场景光照的动态调整。用户可以根据自己的需求,改变光照的强度、颜色和方向,从而创造出不同的视觉效果。例如,用户可以将视频中的白天场景转换为夜晚场景,或者改变光照的颜色,营造出不同的氛围。
材质编辑
DiffusionRenderer允许用户对视频中物体的材质进行编辑。用户可以改变物体的反射率、粗糙度和颜色,从而创造出不同的材质效果。例如,用户可以将视频中的木质家具转换为金属家具,或者改变物体的颜色,使其与场景更加协调。
无缝对象插入
DiffusionRenderer可以实现将新的3D对象无缝地插入到视频中。用户可以选择自己喜欢的3D模型,并将其添加到视频场景中。DiffusionRenderer会自动调整对象的光照和阴影,使其与场景融为一体。例如,用户可以将一辆跑车添加到城市街道的视频中,或者将一个人物添加到森林的视频中。
虚拟现实和增强现实
DiffusionRenderer可以应用于虚拟现实(VR)和增强现实(AR)领域。通过将真实世界的视频转换为3D场景,DiffusionRenderer可以为VR和AR应用提供更逼真的内容。例如,用户可以通过VR设备观看由DiffusionRenderer生成的3D场景,或者将虚拟对象叠加到真实世界的视频中。
DiffusionRenderer的未来展望
DiffusionRenderer作为一项新兴的视频渲染和编辑技术,仍然具有很大的发展空间。未来,我们可以期待DiffusionRenderer在以下几个方面取得更大的突破:
- 更高的渲染质量:随着深度学习技术的不断发展,DiffusionRenderer的渲染质量将不断提高。未来的DiffusionRenderer可以生成更加逼真、细节更加丰富的视频。
- 更强的编辑能力:未来的DiffusionRenderer将具有更强大的编辑能力。用户可以更加灵活地修改视频中的场景和对象,实现更复杂的创作效果。
- 更广泛的应用领域:随着技术的成熟,DiffusionRenderer将应用于更广泛的领域。例如,它可以应用于电影制作、游戏开发、广告设计等领域,为这些行业带来新的发展机遇。
DiffusionRenderer的出现,为视频渲染和编辑领域带来了革命性的变革。它不仅提高了视频的生成质量,还赋予了用户更大的创作自由。相信在不久的将来,DiffusionRenderer将成为视频内容创作的重要工具,推动视频行业的创新和发展。
这项技术的突破,无疑将为视频内容的创作领域带来深远的影响。随着技术的不断完善和应用领域的拓展,我们有理由相信,DiffusionRenderer将在未来的视频制作领域扮演越来越重要的角色,为创作者们带来前所未有的创作体验。








