
在人工智能领域,大语言模型(LLM)的快速发展无疑是引人注目的焦点。而支撑这些强大模型高效运行的,则是背后默默无闻的推理框架。近日,Moonshot AI(月之暗面)旗下的Kimi,悄悄地开源了其自研的推理框架——Mooncake,这无疑给整个行业带来了新的惊喜。那么,这个名为“Mooncake”的框架究竟有何特别之处?它又是如何为Kimi提供强大支持的呢?让我们一同揭开其神秘面纱。
Mooncake:专为Kimi打造的性能怪兽
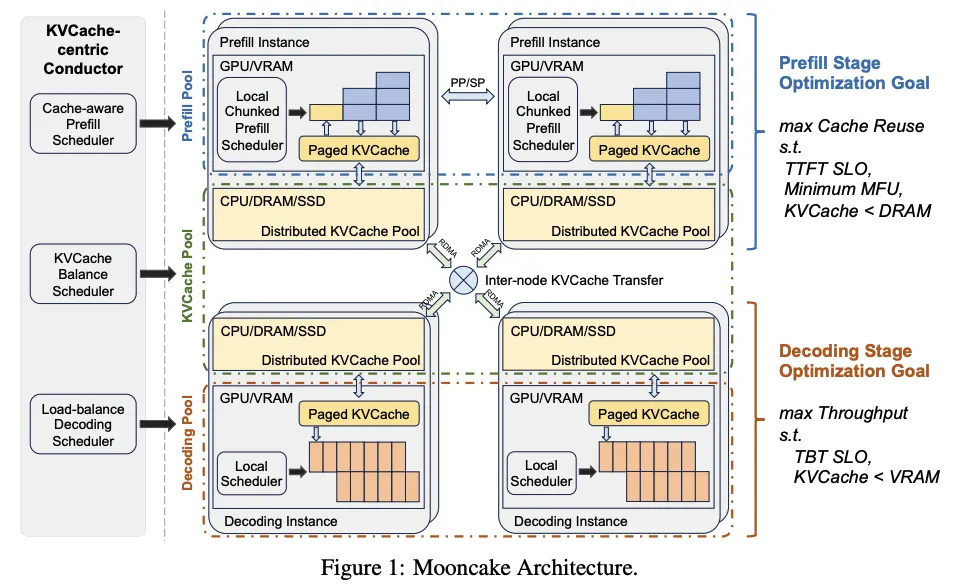
Mooncake并非一个通用的推理框架,而是专门为Kimi量身定制的。Kimi作为一款领先的大型语言模型服务,对推理效率和性能有着极高的要求。为了满足这些严苛的需求,Mooncake采用了以KVCache为中心的解耦架构,巧妙地将预填充(Pre-fill)和解码(Decode)集群分离开来。
KVCache:解耦架构的核心
传统的推理框架往往将预填充和解码过程紧密耦合在一起,这在处理长文本时容易导致资源瓶颈。而Mooncake的创新之处在于,它将KVCache作为核心,将预填充和解码过程解耦。这意味着,预填充阶段生成的KVCache可以被独立地缓存和管理,从而避免了不必要的资源浪费和重复计算。
CPU、DRAM和SSD:闲置资源的有效利用
除了GPU资源外,Mooncake还充分利用了GPU集群中未充分利用的CPU、DRAM和SSD资源。这些资源被巧妙地用于KVCache的解耦缓存,从而进一步提升了整体的推理效率。这种资源利用方式,在业界也算是一种创新。
调度器:最大化吞吐量,满足低延迟要求
Mooncake的核心是一个以KVCache为中心的调度器。它不仅要最大化整体的有效吞吐量,还要满足与延迟相关的服务水平目标(SLOs)要求。这在高度过载场景下尤其具有挑战性。为了应对这些挑战,Mooncake开发了一种基于预测的早期拒绝策略,有效地缓解了过载带来的问题。
吞吐量提升525%:性能飞跃的证明
实验数据是检验技术实力的最好证明。根据官方数据,在某些模拟场景中,Mooncake相比基线方法,实现了高达525%的吞吐量提升,同时仍能满足严格的SLOs要求。在实际工作负载下,Mooncake的创新架构也使得Kimi能够处理比之前多75%的请求,这足以证明其性能的强大。
传输引擎:高速数据传输的基石
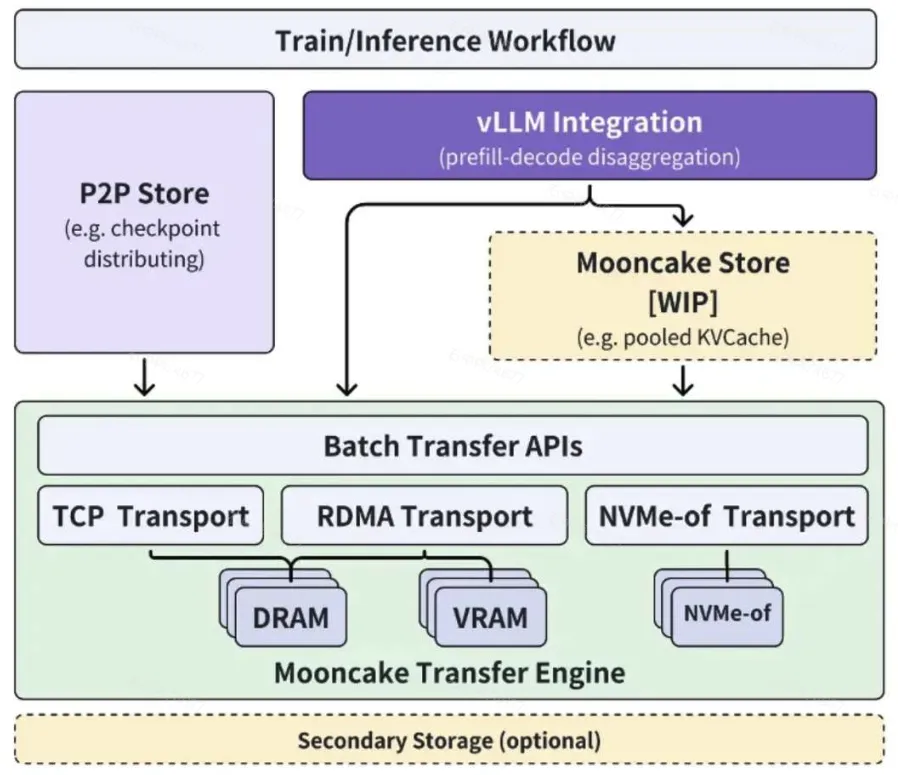
Mooncake的底层部分是传输引擎(Transfer Engine),它支持通过TCP、RDMA、基于NVIDIA GPUDirect的RDMA以及NVMe over Fabric(NVMe-of)协议进行快速、可靠和灵活的数据传输。与gloo(分布式PyTorch使用的)和TCP相比,Mooncake传输引擎具有最低的I/O延迟,这对于大规模分布式推理至关重要。
P2P存储库:打破带宽瓶颈
基于传输引擎,Mooncake还实现了点对点存储库(P2P Store library),支持在集群中的节点之间共享临时对象(例如,检查点文件)。这种方式有效地避免了单台机器上的带宽饱和,提高了数据传输效率。
vLLM的集成:更高效的预填充-解码解耦
Mooncake还对vLLM进行了修改,使其能够集成传输引擎。通过利用RDMA设备,Mooncake使得预填充-解码解耦更加高效,进一步提升了推理性能。
未来展望:池化的KVCache
Mooncake的未来发展蓝图也令人期待。未来,Mooncake计划在传输引擎的基础上构建Mooncake Store,它支持池化的KVCache,以实现更灵活的预填充/解码(P/D)解耦。这将为LLM推理带来更大的灵活性和可扩展性。
Mooncake的开源意义
Mooncake的开源,无疑为整个LLM推理领域注入了新的活力。它不仅展示了Moonshot AI在推理框架方面的强大实力,也为其他研究人员和开发者提供了宝贵的参考。通过开源,Mooncake的技术和经验可以被更广泛地应用,从而推动整个LLM生态的进步。
总结
Mooncake的出现,不仅是Kimi背后的强大支撑,也是LLM推理框架领域的一项重要突破。其以KVCache为中心的解耦架构,高效的资源利用方式,以及强大的传输引擎,都为LLM推理的性能提升提供了新的思路。随着Mooncake的开源,我们有理由相信,LLM推理的未来将更加高效、灵活和强大。

还在为不同的任务寻找不同的 AI 工具吗?chatTools 整合了 o1 推理模型、GPT4o、Claude 和 Gemini 等多种 AI 模型,无论是写作、编程还是创意生成,都能在这里找到合适的 AI 助手。








