
谷歌新型机器人AI:无需云端,自主运行,解锁无限可能
一直以来,我们将诸如 Gemini 和 ChatGPT 这类聊天机器人戏称为“机器人”,但事实上,生成式 AI 在现实世界的物理机器人领域正扮演着日益重要的角色。继今年早些时候谷歌发布 Gemini Robotics之后,Google DeepMind 近日又推出了一款全新的设备端 VLA(视觉语言动作)模型,用于控制机器人。与之前的版本不同,这款新模型无需云端组件,从而使机器人能够完全自主地运行。

谷歌 DeepMind 机器人部门负责人 Carolina Parada 表示,这种 AI 机器人技术方案有望提高机器人在复杂环境中的可靠性。此外,这款模型也是谷歌首个允许开发者针对特定用途进行调整的机器人模型。
机器人技术对于 AI 而言是一个独特的挑战,因为机器人不仅存在于物理世界中,还会改变其环境。无论是让机器人移动物体还是系鞋带,我们都难以预测机器人可能遇到的每一种情况。传统的机器人训练方法依赖于强化学习,但这种方法非常缓慢。而生成式 AI 则能够实现更强大的泛化能力。
Parada 解释说:“它利用了 Gemini 的多模态世界理解能力来完成全新的任务。正如 Gemini 可以生成文本、创作诗歌、总结文章一样,它也可以编写代码、生成图像,甚至生成机器人动作。”
无需云端,通用机器人触手可及
在之前的 Gemini Robotics 版本中(该版本仍然是谷歌“最佳”的机器人技术),平台采用混合系统,即机器人上运行小型模型,云端运行大型模型。我们可能都曾观察到聊天机器人在生成输出时会“思考”几秒钟,但机器人需要快速做出反应。如果你指示机器人拾取并移动一个物体,你肯定不希望它在生成每一个步骤时都停顿下来。本地模型能够实现快速适应,而服务器端模型则可以协助完成复杂的推理任务。现在,Google DeepMind 正在将本地模型作为独立的 VLA 发布,其功能之强大令人惊讶。
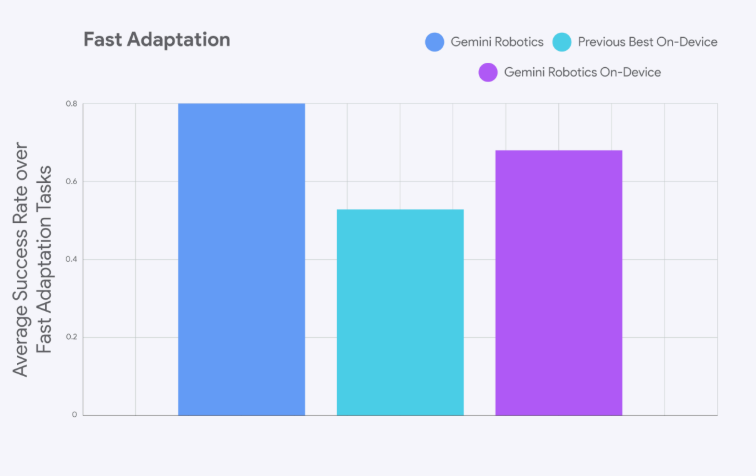
据悉,新款 Gemini Robotics On-Device 模型与混合版本相比,精度仅略有下降。Parada 表示,许多任务都可以直接开箱即用。“当我们与机器人互动时,我们发现它们能够以惊人的速度理解新的情况。”Parada 告诉 Ars。
通过发布包含完整 SDK 的这款模型,该团队希望开发者能够赋予 Gemini 驱动的机器人新的任务,并向它们展示新的环境,从而发现该模型的默认设置无法处理的动作。借助 SDK,机器人研究人员只需进行 50 到 100 次演示,即可将 VLA 调整到新的任务。
在 AI 机器人技术中,“演示”与 AI 研究的其他领域略有不同。Parada 解释说,演示通常涉及远程操作机器人——手动控制机器完成任务,从而调整模型以自主处理该任务。虽然合成数据是谷歌训练的一个要素,但它不能替代真实数据。“我们仍然发现,在最复杂、最灵巧的行为中,我们需要真实数据。”Parada 说,“但是,你可以通过模拟做很多事情。”
然而,这些高度复杂的行为可能超出了设备端 VLA 的能力范围。对于诸如系鞋带(对于 AI 机器人来说,这是一项传统难题)或叠衬衫等简单的动作,它应该没有任何问题。但是,如果你想让机器人为你制作三明治,它可能需要一个更强大的模型来完成将面包放在正确位置所需的多步骤推理。
对于那些与云端的连接不稳定或不存在的环境,该团队认为 Gemini Robotics On-Device 是理想之选。在本地处理机器人的视觉数据也有利于保护隐私,例如在医疗保健环境中。
构建安全的机器人
无论是提供危险信息的聊天机器人,还是变成终结者的机器人,安全始终是 AI 系统的一个重要问题。我们都曾看到生成式 AI 聊天机器人和图像生成器在其输出中产生虚假信息,而为 Gemini Robotics 提供支持的生成式系统也不例外——该模型并非每次都能给出正确答案,但赋予该模型一个拥有冰冷、无情金属抓手的物理形态,会使这个问题变得更加棘手。
为了确保机器人安全运行,Gemini Robotics 采用了一种多层方法。“借助完整的 Gemini Robotics,你可以连接到一个能够推理出什么是安全的模型。”Parada 说,“然后,你可以让它与一个实际生成选项的 VLA 对话,然后该 VLA 调用一个低级控制器,该控制器通常具有安全关键组件,例如你可以移动多少力或你可以以多快的速度移动此手臂。”
重要的是,新的设备端模型只是一个 VLA,因此开发者需要自行构建安全性。不过,谷歌建议他们复制 Gemini 团队所做的工作。建议早期测试计划中的开发者将系统连接到标准的 Gemini Live API,该 API 包含一个安全层。他们还应该为关键安全检查实施一个低级控制器。
任何有兴趣测试 Gemini Robotics On-Device 的人都应该申请访问谷歌的受信任测试者计划。谷歌的 Carolina Parada 表示,在过去三年中,机器人技术取得了许多突破,而这仅仅只是一个开始——当前版本的 Gemini Robotics 仍然基于 Gemini 2.0。Parada 指出,Gemini Robotics 团队通常落后于 Gemini 开发一个版本,而 Gemini 2.5 已被认为是聊天机器人功能的一项重大改进。也许机器人也是如此。
行业白皮书解读:谷歌 Gemini Robotics On-Device 模型的深远影响
引言
谷歌 DeepMind 近期发布的 Gemini Robotics On-Device 模型,标志着机器人技术发展的一个重要里程碑。该模型无需云端连接即可实现自主运行,为机器人应用带来了前所未有的灵活性和可靠性。本文将深入探讨该模型的关键特性、技术优势及其在不同领域的潜在应用,并分析其对机器人产业生态的深远影响。
Gemini Robotics On-Device 模型的关键特性
设备端自主运行:该模型最大的亮点在于其无需依赖云端服务器即可独立运行。这意味着机器人可以在网络连接受限或无法连接的场景中执行任务,例如偏远地区、地下设施或紧急救援现场。
视觉语言动作 (VLA) 模型:VLA 模型使机器人能够理解视觉信息和自然语言指令,并将其转化为实际的动作。这使得用户可以通过简单的语言指令来控制机器人,而无需编写复杂的代码。
可定制化:谷歌为开发者提供了完整的 SDK,允许他们根据特定需求定制 VLA 模型。通过少量的演示数据,开发者即可将模型调整到新的任务,从而大大降低了开发成本和时间。
安全性:Gemini Robotics 采用多层安全机制,确保机器人运行的安全性。该模型不仅能够推理出什么是安全的,还能控制机器人的动作,防止其对环境或自身造成损害。
技术优势分析
更快的响应速度:由于无需与云端服务器通信,设备端模型能够实现更快的响应速度。这对于需要实时反馈的应用场景至关重要,例如工业自动化、自动驾驶和医疗机器人。
更高的可靠性:在网络连接不稳定的情况下,云端机器人可能会出现故障或延迟。而设备端机器人则不受网络影响,能够持续稳定地运行。
更好的隐私保护:设备端模型在本地处理数据,无需将数据上传到云端。这有助于保护用户的隐私,尤其是在医疗保健等敏感领域。
更低的运营成本:由于无需支付云端服务器的费用,设备端机器人能够降低运营成本,从而使其更具竞争力。
应用领域展望
工业自动化:Gemini Robotics On-Device 模型可以应用于各种工业自动化场景,例如物料搬运、质量检测和装配。该模型能够提高生产效率、降低人工成本,并改善工作环境。
物流仓储:在物流仓储领域,该模型可以用于自动分拣、包装和运输货物。这有助于提高物流效率、降低运输成本,并减少人为错误。
医疗保健:该模型可以用于辅助手术、康复治疗和药物配送。这有助于提高医疗质量、降低医疗成本,并改善患者体验。
家庭服务:随着技术的不断发展,Gemini Robotics On-Device 模型有望应用于家庭服务机器人,例如清洁、烹饪和陪伴老人。这将极大地改善人们的生活质量。
对机器人产业生态的影响
加速机器人普及:Gemini Robotics On-Device 模型的出现降低了机器人开发的门槛,使其更易于部署和使用。这将加速机器人在各个行业的普及。
推动产业创新:该模型为开发者提供了更多的创新空间,促使他们开发出更多具有创新性的机器人应用。这将推动机器人产业的快速发展。
重塑竞争格局:随着设备端机器人技术的不断成熟,机器人产业的竞争格局将发生变化。拥有核心技术和创新能力的厂商将占据更有利的位置。
结论
谷歌 DeepMind 的 Gemini Robotics On-Device 模型是一项具有里程碑意义的技术创新。它不仅为机器人应用带来了前所未有的灵活性和可靠性,还将加速机器人在各个行业的普及,推动产业创新,并重塑竞争格局。我们有理由相信,在 Gemini Robotics On-Device 模型的推动下,机器人技术将迎来更加美好的未来。








