
在人工智能领域,一场新的变革正在悄然发生。当人们还在惊叹于OpenAI等巨头动辄数亿美元的巨额投入时,一款名为DeepSeek V3的国产开源模型,以其惊人的效率和卓越的性能,震撼了整个行业。这款由深度求索公司开发的模型,仅用550万美元的成本,就达到了与OpenAI顶级模型GPT-4o和Claude-3.5-Sonnet相媲美的水平,引发了业界广泛关注,被誉为“国货之光”。
打破算力迷思,DeepSeek V3的“低成本”奇迹
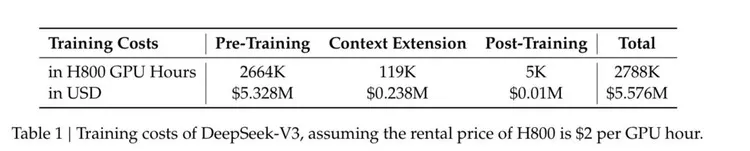
一直以来,AI大模型的训练都被视为一场“烧钱”的游戏,巨额的算力投入似乎是取得成功的必要条件。然而,DeepSeek V3的出现,彻底打破了这一迷思。其技术报告显示,DeepSeek V3仅使用了2000张H800 GPU,耗时不到两个月,总训练成本仅为550万美元左右。这个数字,与OpenAI等公司动辄数亿甚至数十亿美元的投入相比,简直是天壤之别。
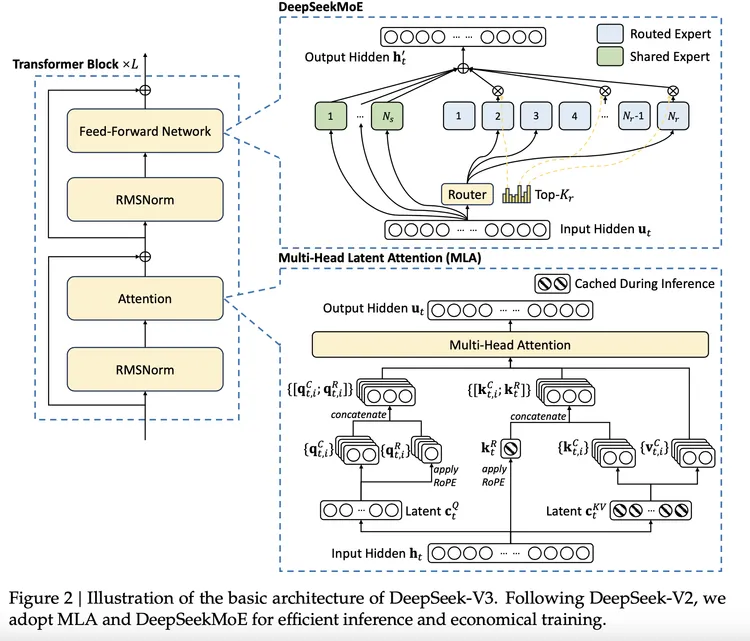
DeepSeek V3之所以能够实现如此高效的训练,并非偶然,而是其在算法和工程上的多项创新共同作用的结果。它采用了混合专家模型(MoE)架构,结合了辅助损失自由负载均衡策略、冗余专家机制等多项技术,最大化地利用了有限的硬件资源,实现了惊人的训练效率。
性能比肩顶尖,DeepSeek V3的全面突破
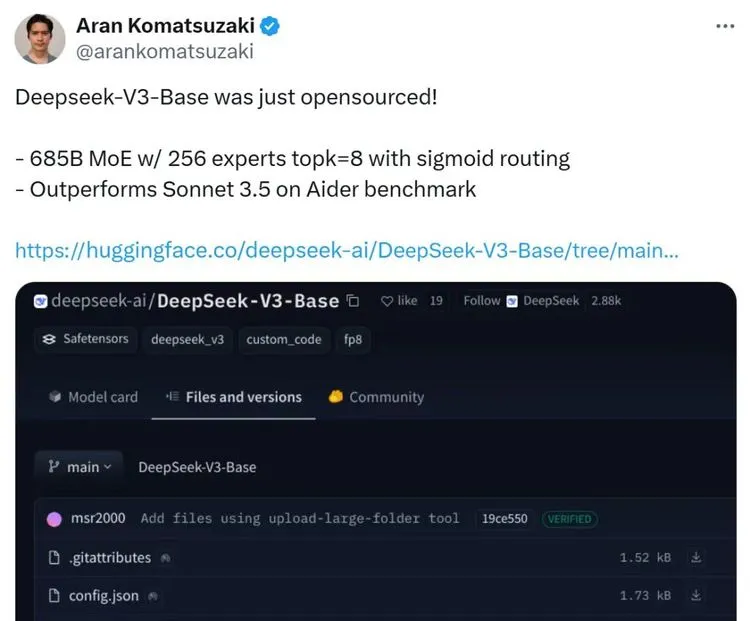
DeepSeek V3不仅在训练成本上令人瞩目,其在性能上的表现也堪称惊艳。官方数据显示,DeepSeek V3在多个评测基准上,均取得了优异的成绩,甚至在某些领域超越了其他开源模型,并与GPT-4o和Claude-3.5-Sonnet等闭源模型不分伯仲。
- 知识领域: DeepSeek V3在MMLU、MMLU-Pro、GPQA、SimpleQA等知识类任务上的表现,接近当前表现最好的模型Claude-3.5-Sonnet-1022,展现了其强大的知识储备和理解能力。
- 长文本处理: 在DROP、FRAMES和LongBench v2等长文本测评中,DeepSeek V3的平均表现超越了其他模型,证明其具备优秀的长文本处理能力。
- 代码能力: DeepSeek V3在算法类代码场景(Codeforces)中,远远领先于市面上已有的全部非o1类模型;在工程类代码场景(SWE-Bench Verified)中,也逼近了Claude-3.5-Sonnet-1022。
- 数学能力: 在美国数学竞赛(AIME 2024, MATH)和全国高中数学联赛(CNMO 2024)上,DeepSeek V3大幅超过了所有开源闭源模型,展示了其强大的逻辑推理和数学运算能力。
- 中文能力: DeepSeek V3在教育类测评C-Eval和代词消歧等评测集上,与Qwen2.5-72B表现相近,但在事实知识C-SimpleQA上更为领先,展现了其出色的中文理解和应用能力。
这些数据充分证明,DeepSeek V3不仅是一款低成本的模型,更是一款性能卓越的AI大模型,其在多个领域都展现出了强大的实力。
技术创新驱动,DeepSeek V3的“秘诀”
DeepSeek V3之所以能够取得如此成就,与其在技术上的创新密不可分。除了前面提到的MoE架构和负载均衡策略外,DeepSeek V3还在以下几个方面进行了创新:
- 辅助损失自由负载均衡策略: 通过动态调整专家的偏置值,使输入Token更均匀地分配给不同的专家,无需引入额外损失,从而在负载均衡和模型性能之间找到了更优解。
- 冗余专家机制: 为高负载专家创建“副本”,将任务分配到不同的副本上,缓解计算压力,提升整体推理速度,特别是在高并发场景下,实现了资源的弹性扩展和更稳定的服务性能。
- 多Token预测目标(MTP): 让模型在每个输入Token的基础上同时预测多个未来Token,提供更多的反馈信号,加速模型的学习,并提升模型在推理时的“规划”能力。
- FP8低精度训练优化: 通过分块量化,将数据分成更小的组进行独立缩放,使模型更灵活地适应输入数据的变化范围,避免低精度带来的精度损失。
- DualPipe流水线并行策略: 通过更精细的任务分解和调度,将计算和通信时间完全重叠,最大限度地利用了每一块GPU的性能,降低了对硬件资源的需求。
这些创新技术的应用,使得DeepSeek V3在训练效率、推理速度和模型性能上都得到了显著提升。
开源共享,DeepSeek V3的行业责任
DeepSeek V3不仅是一款技术领先的模型,更是一款开源共享的模型。它的发布,无疑为广大开发者提供了新的选择,也为AI技术的普及和发展做出了重要贡献。
DeepSeek V3的开源,意味着开发者可以免费使用和修改这个模型,并将其应用到各种场景中,从而加速AI技术的创新和落地。同时,DeepSeek V3的成功,也向业界传递了一个重要的信号:算力不再是唯一决定因素,技术创新才是驱动AI发展的核心动力。
未来展望:DeepSeek V3的启示
DeepSeek V3的成功,不仅是对深度求索公司技术实力的肯定,更是对整个国产AI行业的一次鼓舞。它证明了,中国开发者完全有能力在AI领域取得领先地位,并为全球AI技术的发展做出贡献。
DeepSeek V3的出现,也给那些过度依赖算力的AI企业敲响了警钟:盲目地投入巨额资金购买硬件,并不一定能够带来真正的技术突破。只有坚持创新,不断探索新的算法和技术,才能在激烈的竞争中脱颖而出。
DeepSeek V3的成功,也预示着AI行业的新时代正在到来。未来,我们将会看到更多像DeepSeek V3这样,以技术创新为驱动,打破算力依赖的优秀模型涌现。而这些模型,必将推动AI技术向更加高效、普惠的方向发展,为人类的未来带来更多的可能性。
结语
DeepSeek V3的出现,无疑是今年AI领域最令人兴奋的事件之一。它以其低成本、高性能和开源共享的特点,重新定义了AI大模型的开发模式,也为中国AI的崛起注入了新的活力。DeepSeek V3的成功,不仅是深度求索的骄傲,更是整个中国AI行业的骄傲。让我们共同期待,DeepSeek V3能够为AI的未来带来更多的惊喜!








