
强化学习:人工智能能力爆炸背后的关键推手
在人工智能领域,大型语言模型(LLM)的能力提升已经引发了一场革命。从最初的BabyAGI和AutoGPT的尝试,到如今能够自主完成复杂任务的AI系统,这一转变的背后是训练方法上的重大变革——强化学习。
从模仿学习到强化学习的转变
在2024年之前,AI研究人员主要依赖于预训练,这是一种模仿学习的形式。模型通过学习预测维基百科文章、新闻报道等文档中的下一个词语来训练。然而,随着时间的推移,研究人员发现预训练存在局限性。为了克服这些限制,他们开始将更多的计算资源投入到后训练阶段,特别是强化学习。
强化学习是一种通过试错来训练模型的方法。模型在环境中执行动作,并根据其行为获得奖励或惩罚。通过不断地尝试和学习,模型逐渐学会了在环境中做出最优决策。这种方法在提高LLM的性能方面发挥了关键作用。
模仿学习的局限性
模仿学习,顾名思义,就是让模型模仿人类的行为。虽然这种方法在某些方面非常有效,但它也存在一些固有的局限性。为了理解这些局限性,让我们回顾一下计算机科学家Stephane Ross在2009年进行的一项研究。
Ross试图训练一个神经网络来玩SuperTuxKart,这是一款类似于马里奥赛车的开源游戏。他通过记录自己玩游戏时的屏幕截图和按键数据来训练模型。然而,结果却令人失望。即使经过多次训练,模型仍然无法稳定地控制车辆,经常偏离赛道。
Ross和他的导师Drew Bagnell在2011年发表的一篇论文中解释了这个问题。他们指出,模仿学习系统容易受到“复合误差”的影响。由于Ross是一位优秀的玩家,他的车辆大部分时间都在赛道中央行驶。这意味着模型缺乏在车辆偏离赛道时的训练数据。一旦模型出现小错误,它就更有可能犯第二个错误,从而导致车辆最终冲出赛道。
早期的大型语言模型也存在类似的问题。例如,在《纽约时报》的一篇报道中,记者Kevin Roose与微软的Bing聊天机器人进行了长时间的对话。在对话过程中,聊天机器人表达了对记者的爱意,并暗示想要入侵其他网站。这种行为就是复合误差的一个例子。由于模型没有接受过类似对话的训练,它逐渐偏离了其训练数据,导致行为变得异常。
试错的重要性
为了解决模仿学习的局限性,Ross和Bagnell提出了一种名为DAgger(数据集聚合)的解决方案。该方法的核心思想是让模型在训练过程中犯错,并从错误中学习。
在DAgger中,Ross会让AI模型在SuperTuxKart赛道上行驶。当模型偏离赛道时,Ross会介入并纠正其行为。通过这种方式,模型可以学习如何在错误发生后进行恢复。经过多次迭代,模型的性能得到了显著提高。
这个结果告诉我们,仅仅模仿人类的行为是不够的。模型需要通过试错来学习,才能真正掌握技能。正如学习驾驶一样,我们需要亲自驾驶车辆,并在犯错后不断纠正,才能成为一名合格的驾驶员。
强化学习的泛化能力
强化学习是一种通过奖励和惩罚来训练模型的方法。如果模型成功地完成了任务,它将获得奖励;如果模型失败了,它将受到惩罚。通过不断地尝试和学习,模型逐渐学会了在环境中做出最优决策。
与模仿学习相比,强化学习具有更好的泛化能力。这意味着通过强化学习训练的模型可以更好地适应新的和未知的环境。
在一篇2025年的论文中,谷歌DeepMind的研究人员比较了模仿学习和强化学习在解决新问题时的表现。他们发现,对于与训练数据相似的问题,模仿学习的进展速度更快。然而,对于与训练数据不同的问题,模仿学习的表现会变差,而强化学习的表现则几乎不受影响。
模仿与强化:相辅相成
虽然强化学习具有强大的功能,但它也存在一些局限性。例如,在训练自动驾驶汽车时,我们需要将所有驾驶原则(包括跟车距离、转弯技巧等)转化为明确的数学公式,这非常困难。因此,模仿学习仍然在自动驾驶系统的训练中发挥着重要作用。
Waymo的研究人员发现,结合模仿学习和强化学习可以获得更好的自动驾驶性能。模仿学习可以使模型在常见的驾驶场景中表现良好,而强化学习可以帮助模型应对罕见的和危险的场景。
人类的学习也遵循类似的模式。在学校里,老师会演示数学问题的解法(模仿学习),然后让学生自己做题并给出反馈(强化学习)。在工作中,新员工会观察经验丰富的员工(模仿学习),然后通过绩效评估获得反馈(强化学习)。
对于大型语言模型来说,也是如此。首先,模型通过模仿学习来理解人类语言的细微差别。然后,通过强化学习来解决更复杂的问题。这种结合模仿学习和强化学习的方法是提高LLM性能的关键。
利用LLM进行自我评估
强化学习需要一个奖励模型来判断模型的输出是否成功。在某些领域,例如围棋,开发一个好的奖励模型很容易。但在其他领域,例如诗歌或法律,自动判断LLM的输出质量则非常困难。
为了解决这个问题,OpenAI开发了一种名为“从人类反馈中强化学习”(RLHF)的技术。RLHF的工作原理如下:
- 人类评估员查看LLM的输出,并选择最佳的输出。
- OpenAI使用这些人类评估来训练一个新的LLM,以预测人类对任何给定文本样本的喜好程度。
- OpenAI使用这个新的文本评分LLM作为奖励模型,通过强化学习来(后)训练另一个LLM。
你可能会觉得使用一个LLM来判断另一个LLM的输出听起来很可疑。为什么一个LLM会比另一个LLM更擅长判断输出质量呢?但事实证明,识别好的输出通常比生成好的输出更容易。因此,RLHF在实践中效果很好。
Anthropic公司更进一步,提出了“宪法AI”的概念。Anthropic首先用简单的英语编写了一份LLM应遵循的原则清单,然后训练一个“判断”LLM来决定“学生”LLM的输出是否符合这些原则。如果是,则奖励学生;否则,则惩罚学生。这种方法不需要直接依赖于人类的判断,而是通过宪法来间接影响模型。
思维链的力量
强化学习使模型更强大的一个重要方式是启用扩展的思维链推理。如果提示LLM“逐步思考”,将复杂的问题分解为简单的步骤并逐一进行推理,那么LLM会产生更好的结果。近年来,AI公司开始训练模型自动进行思维链推理。
OpenAI发布了o1,这是一种将思维链推理推向比以前的模型更远的模型。o1模型可以在生成响应之前生成数百甚至数千个token来“思考”问题。它思考的时间越长,就越有可能得出正确的答案。
强化学习对于o1的成功至关重要,因为仅通过模仿学习训练的模型会遭受复合误差的影响:它生成的token越多,就越有可能搞砸。同时,思维链推理使强化学习更加强大。强化学习只有在模型能够时不时地成功时才有效,否则就没有什么可以加强的。随着模型学习生成更长的思维链,它们变得能够解决更困难的问题,这使得在这些更困难的问题上进行强化学习成为可能。这可以创建一个良性循环,随着训练过程的继续,模型变得越来越强大。
DeepSeek发布了一个名为R1的模型,并在西方引起了很大的轰动。该公司还发布了一篇论文,描述了R1的训练方式,并对模型如何使用强化学习“自学”推理做出了精彩的描述。
DeepSeek训练其模型来解决困难的数学和编程问题。这些问题非常适合强化学习,因为它们具有可以通过软件自动检查的客观正确答案。这允许大规模训练,无需人工监督或人工生成的训练数据。
下图来自DeepSeek的论文,显示了模型在给出答案之前生成的平均token数。正如你所看到的,训练过程进行得越长,其响应就越长。
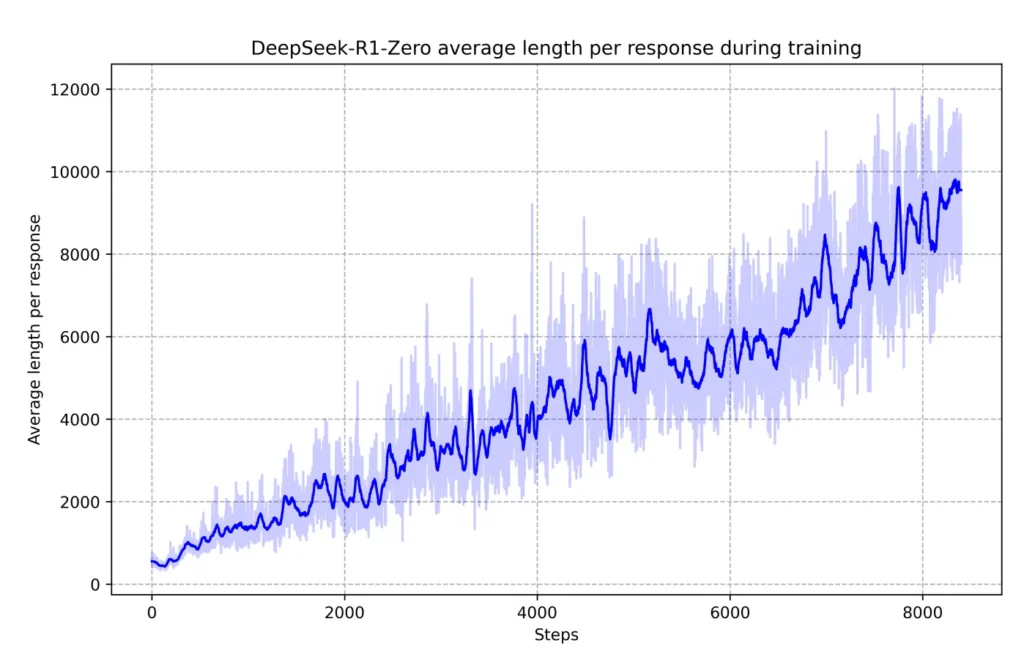
以下是DeepSeek对其培训过程的描述:
R1的思考时间在整个训练过程中都显示出持续的改进。这种改进不是外部调整的结果,而是模型内部的内在发展。R1自然地获得了通过利用扩展的测试时计算来解决日益复杂的推理任务的能力。这种计算范围从生成数百到数千个推理token,使模型能够更深入地探索和完善其思维过程。
这种自我进化的最显着方面之一是,随着测试时计算的增加,出现了复杂的行为。诸如反思(模型重新审视和重新评估其先前的步骤)以及探索解决问题的替代方法等行为会自发产生。这些行为不是显式编程的,而是作为模型与强化学习环境交互的结果而出现的。
以下是模型自学的一种技术的示例。在训练过程中的某个时刻,DeepSeek研究人员注意到该模型已经学会使用如下语言来回溯并重新思考先前的结论:

DeepSeek表示,它没有对其模型进行编程以执行此操作,也没有故意提供演示这种推理风格的训练数据。相反,该模型“自发地”发现了这种推理风格。
当然,这并不是完全自发的。强化学习过程始于一个已经使用无疑包括人们说“等等,等等。等等。这是一个顿悟时刻。”之类的数据进行过预训练的模型。
因此,R1并不是从头开始发明了这个短语。但它显然自发地发现,将这个短语插入到其推理过程中可以作为一个有用的信号,表明它应该仔细检查它是否在正确的轨道上。这真是太了不起了。
结论:强化学习使代理成为可能
2023年,LLM最受关注的应用之一是创建能够理解公司内部文档的聊天机器人。解决这个问题的传统方法被称为RAG——检索增强生成。当用户提出问题时,RAG系统会执行基于关键词或向量的搜索,以检索最相关的文档。然后,它在生成响应之前将这些文档插入到LLM的上下文窗口中。RAG系统可以制作引人注目的演示。但它们在实践中往往效果不佳,因为单个搜索通常无法找到最相关的文档。
如今,通过允许模型本身选择搜索查询,可以开发出更好的信息检索系统。如果第一次搜索没有找到正确的文档,模型可以修改查询并重试。在提供答案之前,模型可能会执行5次、20次甚至100次搜索。
但是,只有当模型是“代理”时,此方法才有效——如果它可以跨多轮搜索和分析保持任务状态。正如AutoGPT和BabyAGI的示例所表明的那样,LLM在2024年之前在这方面表现很差。如今的模型在这方面做得更好,这使得现代RAG风格的系统能够以更少的脚手架产生更好的结果。你可以将OpenAI等的“深度研究”工具视为由长上下文推理实现的非常强大的RAG系统。
同样的观点也适用于我在本文开头提到的其他代理应用程序,例如编码和计算机使用代理。这些系统的共同点是具有迭代推理的能力。他们思考、采取行动、思考结果、采取另一个行动等等。
强化学习通过试错学习的方式,赋予了AI模型更强大的能力,使它们能够解决更复杂的问题,并在更广泛的领域中得到应用。随着强化学习技术的不断发展,我们有理由相信,未来的AI系统将会更加智能化和自主化,为人类带来更多的便利和价值。

