
在全球人工智能模型快速发展的浪潮中,开源模型正逐渐崭露头角,成为推动AI技术进步的重要力量。近日,DeepSeek-V3和Qwen 2.5系列的相继发布,再次为开源模型注入了新的活力。这两大模型不仅在性能上取得了显著突破,更在训练成本和资源消耗方面进行了高效优化,成功地缩小了与闭源顶级模型之间的差距,为开源AI的未来发展指明了方向。
DeepSeek-V3:低成本高效能的开源典范
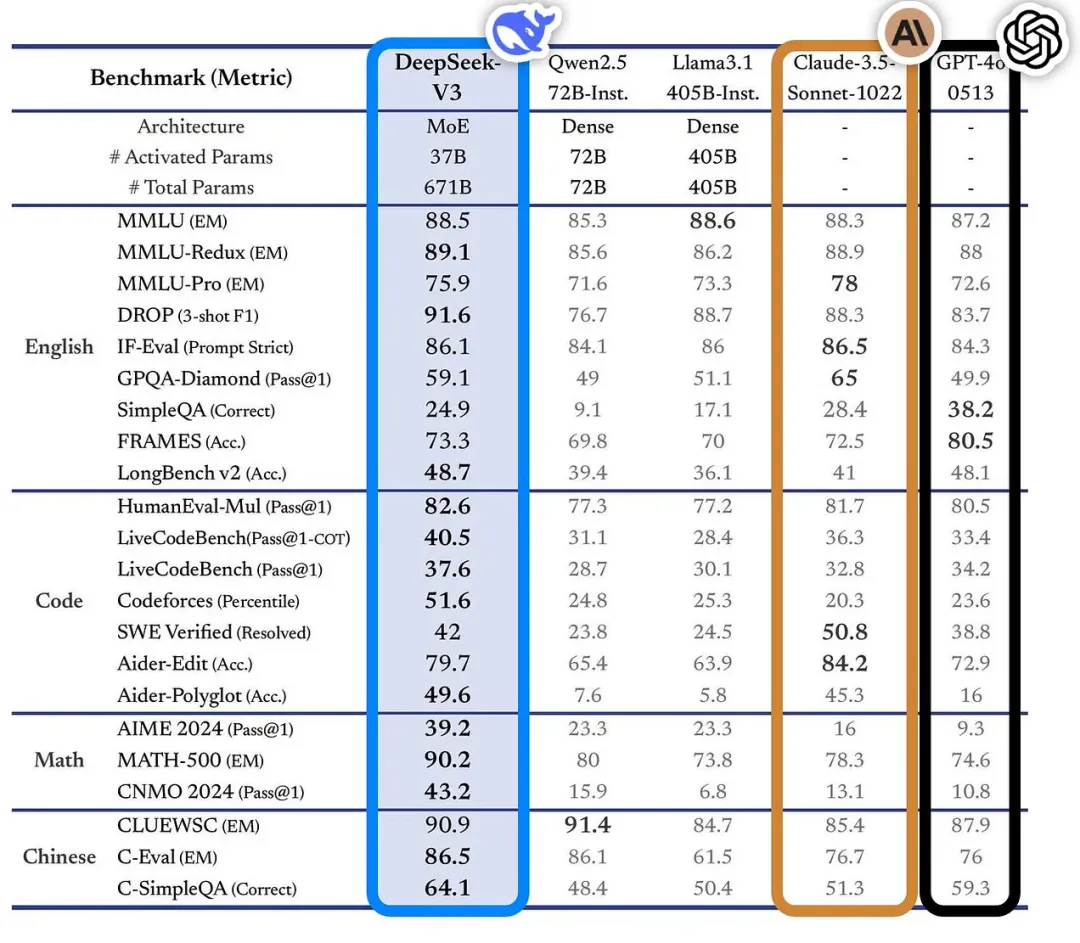
DeepSeek-V3模型以其100%开源的姿态,吸引了全球AI研究者的目光。这款基于混合专家(MoE)架构的大型语言模型,总参数高达671B,但每个token仅激活37B,在多个基准测试中击败了GPT-4o和Claude 3.5 Sonnet等闭源模型,展现出强大的竞争力。
DeepSeek-V3的成功,很大程度上归功于其精细的MoE架构。该架构采用每个token有1个共享专家和256个路由专家,其中8个路由专家活跃。此外,DeepSeek-V3还引入了多头潜在注意力机制,并采用低等级联合压缩来处理关注键和值。多token预测技术的应用,则有助于投机解码,并更好地利用训练数据。
更令人惊讶的是,DeepSeek-V3仅使用了14.8万亿个token进行训练,耗时2788K H800 GPU小时,成本仅为560万美元。如此低的训练成本,得益于以下几个关键因素:
- 精细的MoE架构: 降低了模型的计算复杂度。
- FP8混合精度训练: 加速了训练过程。
- 动态调整上下文长度: 有效利用训练数据,提高了训练效率。
- 算法-框架-硬件协同设计: 打破了大型MoE模型训练中的通信瓶颈。
通过这些优化,DeepSeek-V3的训练效率提高了10倍,成本显著降低,这为开源模型的普及奠定了基础。
DeepSeek-V3在多个基准测试中表现出色:
- MMLU: 88.5
- GPQA: 59.1
- MMLU-Pro: 75.9
- MATH: 90.2
- CodeForces: 51.6
这些数据充分证明了DeepSeek-V3的强大实力,使其成为目前最强的开源模型之一。
Qwen2.5:阿里巴巴开源大模型的全面升级
阿里巴巴Qwen团队发布的Qwen 2.5系列LLM,同样在开源领域掀起了一股热潮。该系列模型包括多个开放式权重基础和指令调整模型,参数范围从0.5B到72B,以及两种专有的混合专家(MoE)型号Qwen2.5-Turbo和Qwen2.5-Plus。其中,开放式Qwen2.5-72B-Instruct的性能可与Llama-3-405B-Instruct相媲美。
Qwen2.5系列模型在技术上进行了多项升级:
- 扩展的训练数据集: 使用了包含18万亿个代币的训练数据集,涵盖了更多样和高质量的数据。
- 复杂的预训练策略: 包括数据过滤、知识/代码/数学数据混合以及长上下文训练。
- 多阶段强化学习: 结合了监督微调(SFT)、离线强化学习(DPO)和在线强化学习(GRPO),提高了模型性能。
- 长上下文能力: 采用YARN和双块注意力(DCA)技术,使得Qwen2.5-Turbo支持高达100万个令牌的上下文长度。
Qwen2.5系列模型的评估结果显示,其在语言理解、数学、编码和人类偏好调整方面均表现出色。特别是在长文本处理方面,Qwen2.5-Turbo在1M令牌密码检索任务中实现了100%的准确率。Qwen2.5也成为了阿里巴巴最新专业模型的基础,如Qwen2.5-Math、Qwen2.5-Coder、QwQ和QvQ等。
开源力量:推动AI技术进步的关键
与大多数专有人工智能模型供应商对技术细节保密不同,DeepSeek和Qwen团队都通过技术报告公开了其模型的详细信息,这种开放透明的态度令人赞赏。开源不仅有助于促进技术的快速传播,更能够激发创新,推动整个AI行业向前发展。
DeepSeek-V3和Qwen 2.5系列的发布,标志着开源模型正在快速缩小与闭源顶级模型的差距。随着这些领先团队的不断努力,开源AI将为全球人工智能的发展注入新的动力,促进AI技术的普惠化,让更多人能够从中受益。








