
人工智能前沿洞察:驱动未来创新的多维度演进
当前,全球人工智能领域正经历前所未有的快速发展,技术突破层出不穷,应用场景持续拓展。从多模态内容的深度融合,到3D生成技术的民主化,再到边缘智能设备的算力跃升,以及大模型训练范式的革新,人工智能正以其强大的生命力重塑着数字世界的面貌。本文将对近期AI领域一系列重要进展进行深入剖析,以期为行业专业人士提供前瞻性的技术洞察与战略参考。
多模态智能:深度融合与创作边界的拓宽
多模态AI作为人工智能发展的重要方向,其目标在于使机器能够像人类一样,同时理解和处理来自不同感官的数据。近期模型在视频与音频同步生成、超长语音合成以及文本转图像质量提升方面的突破,正引领内容创作进入一个全新的纪元。
阿里通义万相Wan 2.2-S2V:视频音频同步生成的里程碑
阿里通义万相团队预告的Wan 2.2-S2V模型,标志着多模态AI生成技术在视频与音频同步生成方面取得了重大进展。传统的视频生成模型往往侧重于视觉内容的输出,音频部分通常独立生成或后期合成,导致两者在情感表达、节奏匹配上存在天然的鸿沟。Wan 2.2-S2V模型的核心创新在于其能够实现视频与音频的深度融合,即在生成视频画面的同时,精准同步生成匹配的音频内容,甚至包括带有唱歌音频的AI视频。这种一体化生成能力,不仅显著提升了生成内容的真实感和沉浸感,更极大地简化了多媒体内容的制作流程。对于内容创作者而言,这意味着可以更高效地制作高质量的数字人表演、虚拟偶像演唱会,或是拥有叙事连贯且情感饱满的虚拟教学视频。其潜在应用价值涵盖了娱乐、教育、虚拟现实和数字营销等多个领域,有望重新定义AI视频生成领域的标准。

微软VibeVoice-1.5B:长文本语音合成的突破
微软开源的VibeVoice-1.5B音频模型,在语音合成技术领域实现了多项突破。最引人注目的是其支持90分钟超长语音合成的能力。在过往的语音合成实践中,长时间的语音生成往往面临音色一致性、情感连贯性和计算效率等多重挑战。VibeVoice-1.5B通过创新的架构设计,有效解决了这些问题。此外,该模型支持最多四位发言人同时合成,极大地丰富了语音内容的表现力,使其适用于播客、有声读物和多角色对话场景。高达3200倍的音频压缩率,则在保证高保真语音效果的同时,显著降低了存储和传输成本。其采用的双tokenizer架构更是解决了音色与语义不匹配的长期难题,使得合成语音无论在音色、语调还是情感表达上都能与文本内容高度契合。这些技术进步将对无障碍交流、智能助手以及多媒体内容的自动化生产产生深远影响。
谷歌Imagen 4:文本到图像生成的精度与效率提升
谷歌Imagen 4文本转图像生成模型的正式上线,通过Gemini API和Google AI Studio平台向用户开放,标志着图像生成技术在质量、速度和成本效益方面达到了新的高度。Imagen 4提供了标准版、快速版和超清版三个版本,以满足不同用户的多样化需求。标准版在整体图像生成质量上有所提升,特别是在文本渲染的准确性方面表现突出,这对于品牌营销、广告设计等对文字视觉呈现有严格要求的场景至关重要。快速版则专注于优化生成速度和大批量处理任务,将每次生成成本降至0.02美元,极大地降低了创意实现的门槛,尤其适合需要快速迭代设计方案的团队。而超清版则致力于生成更精细的图像细节,并能更准确地遵循用户输入的文本提示,确保生成结果与创作者意图的高度一致性。Imagen 4的发布将进一步推动AI在艺术创作、产品原型设计、数字内容营销等领域的应用,为用户提供更强大、更灵活的视觉内容创作工具。
3D生成与边缘智能:技术普及的加速器
人工智能的普及不仅体现在云端大模型的强大能力上,更在于其向更广泛的应用场景,尤其是3D内容创作和边缘设备的渗透。这些技术正共同降低专业门槛,让更多人能够利用AI实现复杂的创意与计算。
字节跳动“3D Model Generator”:民主化3D内容创作
字节跳动旗下豆包团队内测的“3D Model Generator”工具,旨在通过AI技术降低3D建模的门槛。传统的3D建模过程需要专业技能和耗时操作,是许多创意项目面临的瓶颈。该工具支持基于单一或多张图像生成3D模型,还可结合图像与现有的模型文件进行生成,极大地增强了创作的灵活性。这意味着设计师、开发者甚至普通用户,无需掌握复杂的3D软件操作,也能快速将2D图像转化为3D资产。特别是在游戏开发、虚拟现实(VR)/增强现实(AR)以及工业设计等领域,这一工具将显著缩短开发周期,降低成本,加速3D内容的生产与创新。预计未来对外开放后,“3D Model Generator”将为更广泛的用户群体提供强大的3D创作能力,推动数字内容生态的蓬勃发展。
面壁智能MiniCPM-V4.5:端侧多模态大模型的性能标杆
面壁智能与清华大学NLP实验室联合推出的MiniCPM-V4.5,作为一款端侧多模态大模型,以其卓越的性能和高效的部署能力受到了广泛关注。该模型仅拥有4.1亿参数,却在多项基准测试中表现出色,甚至超越了某些参数量更大的模型,如GPT-4.1-mini。其核心优势在于支持多语言、视频理解和高分辨率图像处理,并能高效部署于边缘设备,如智能手机和物联网终端。这意味着MiniCPM-V4.5可以在不依赖云端算力的情况下,在设备本地处理复杂的视觉和语言任务,大大提升了响应速度和数据隐私性。其OCR(光学字符识别)性能更是领先主流模型,使其在文档识别、图像文字提取等场景中表现优异。MiniCPM-V4.5的出现,不仅推动了AI技术向移动、离线等边缘场景的普及,也为开发者提供了构建轻量级、高性能AI应用的强大基石,降低了AI开发的门槛,加速了AI普惠化的进程。

AI训练范式与机器人智能:底层能力的重塑
人工智能的进步离不开其核心驱动力——训练方法的持续优化和硬件算力的不断提升。苹果公司在大语言模型训练上提出了创新方法,而英伟达则在机器人计算平台方面发布了革命性产品,二者共同构筑了未来智能系统的坚实基础。
苹果RLCF:大语言模型训练的新范式
苹果公司研究团队提出了一种名为基于清单反馈的强化学习(RLCF)的创新训练方法,旨在大幅提升大语言模型(LLM)执行复杂指令的能力。传统的LLM训练往往依赖于人工的点赞或评分机制来提供反馈信号,这种主观且粒度粗糙的反馈难以有效指导模型处理多步骤、高难度的复杂任务。RLCF方法通过用具体任务清单替代传统的人工评分,为模型提供了更明确、更客观的反馈信号。通过大规模模型生成详细的检查清单,小模型能够获得更精准的优化指导。在FollowBench、InFoBench等多个评测基准中,采用RLCF训练的模型性能提升显著,最高达到8.2%。这一方法的突破性在于,它为LLM如何更精确地理解并执行复杂指令提供了有效路径,尤其在需要逻辑推理、多步骤规划的场景下,展现出巨大的潜力。尽管RLCF的实施需要强大的计算资源支持,但其为未来LLM的精细化训练和复杂任务处理开辟了新的研究方向。
英伟达Jetson Thor:下一代机器人计算平台
英伟达推出的Jetson Thor机器人计算平台,是机器人和自主系统领域的一项重大技术飞跃。该平台采用了最新的Blackwell GPU架构,其AI算力高达2070 TFLOPS(每秒万亿次浮点运算),相较于上一代平台提升了7.5倍。如此巨大的算力提升,意味着Jetson Thor能够同时运行更多、更复杂的AI模型,处理海量的传感器数据,从而实现更高级别的感知、决策与控制。平台配备的128GB超大内存,为多任务处理和复杂场景下的高效运行提供了充足支持。Jetson Thor的另一大亮点是集成了NVIDIA Isaac仿真平台,为开发者提供了一个从云端到边缘的统一开发环境。通过Isaac平台,开发者可以在虚拟环境中进行机器人设计、训练和测试,极大地加速了开发周期,降低了物理实验的成本和风险。Jetson Thor的发布,将加速机器人技术在工业自动化、物流、医疗、农业以及自动驾驶等领域的创新应用,推动机器人走向更高智能、更广普及的阶段。

AI在垂直领域的创新应用与行业动态
人工智能的触角已延伸至各行各业,催生出颠覆性的解决方案。从品牌设计到平台安全,AI的赋能无处不在,同时也伴随着人才流动等行业关注点。
Genspark AIDesigner:重塑AI设计新格局
Genspark AI Designer是一款革命性的AI设计工具,旨在通过人工智能技术实现品牌设计流程的自动化和智能化。它能够“一键生成”完整的品牌设计方案,涵盖了Logo、包装、网站设计等多个关键领域。该工具的核心优势在于其支持多模态输入,用户可以通过自然语言指令,轻松生成矢量图标、3D渲染图和动画视频等多种设计资产。这极大地降低了专业设计软件的使用门槛,使得非专业人士也能创作出高质量的设计作品。对于品牌而言,AI Designer不仅能够显著缩短品牌创建周期,降低设计成本,还能通过快速迭代和个性化定制,更好地满足市场需求。它重新定义了品牌设计流程,为广告公司、初创企业和个人创作者提供了高效且经济的创意解决方案,预示着AI在设计领域的巨大潜力和广泛应用。

字节跳动AI人才流失与豆包未成年人保护模式
在人工智能技术飞速发展的背景下,行业内的人才流动也日益频繁,顶级人才的去留往往牵动着技术发展方向。字节跳动Seed大模型视觉基础研究团队的核心负责人冯佳时正式离职,这一事件无疑对字节跳动在AI领域的布局产生了一定影响。冯佳时在计算机视觉领域拥有深厚的学术背景和丰富的经验,他在字节跳动期间领导了多模态基础模型和生成模型等前沿技术的研究,为公司的技术创新做出了重要贡献。顶级AI人才的流动是行业常态,也反映了AI领域竞争的激烈和对人才的渴求。
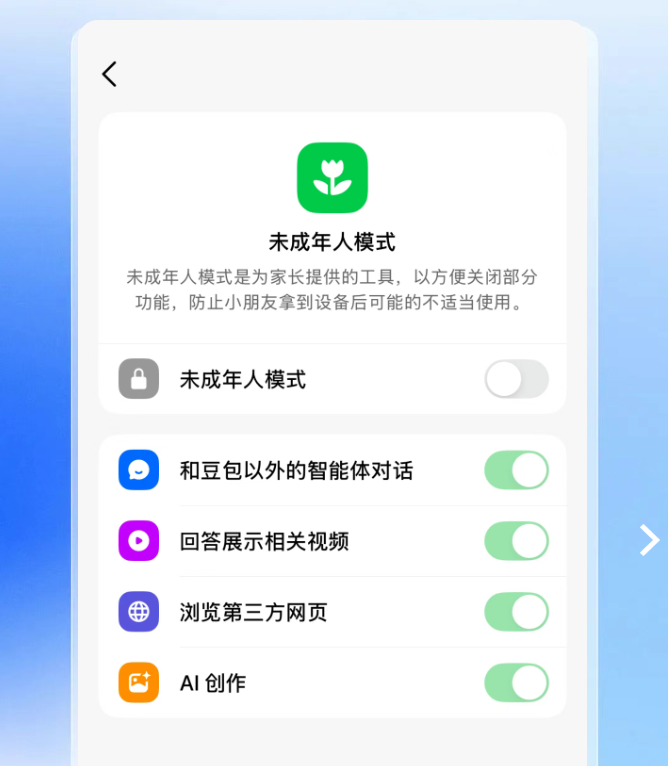
与此同时,字节跳动旗下的豆包团队也推出了未成年人保护模式,旨在帮助家长有效管理孩子使用AI产品时的行为。该模式通过密码开启,关闭了部分可能不适合未成年人的功能,如推荐视频和第三方网页浏览,但保留了翻译和深入研究等有助于学习和探索的功能。这一举措体现了AI产品在快速发展的同时,对社会责任和伦理规范的日益重视。在AI技术日益普及的今天,如何平衡技术创新与用户保护,尤其是在未成年人使用场景下的安全考量,是所有AI公司必须面对的重要课题。
结语:AI浪潮下的机遇与挑战
综上所述,人工智能正以前所未有的速度和广度渗透到社会的各个层面。从多模态内容的融合创新,到3D生成与边缘智能的普及,再到训练范式的优化和机器人算力的飞跃,AI技术正在不断突破自身边界,重塑我们对智能的认知。这些进展不仅为各行业带来了前所未有的发展机遇,也提出了新的技术挑战和伦理考量。未来,如何持续推动技术创新,同时确保AI的负责任发展,平衡好效率与安全,将是全球科技界共同面临的重要议题。人工智能的无限潜力正在逐步释放,而我们正身处这场技术变革的核心,共同见证并塑造着智能化的未来。








