
生成式人工智能(Generative AI)技术的飞速发展,正以前所未有的速度重塑着数字内容创作的格局。然而,随之而来的版权争议也日益成为行业关注的焦点。继迪士尼和环球影业之后,娱乐巨头华纳兄弟公司近期也对知名AI图像生成平台Midjourney提起了诉讼,再次将AI与知识产权的冲突推向风口浪尖。此次诉讼不仅是对现有法律框架的挑战,更预示着未来数字内容产业可能面临的深刻变革。
华纳兄弟的核心指控:IP滥用与利益驱动
华纳兄弟在其诉讼中明确指出,Midjourney通过未经授权的方式,利用其旗下大量知名IP角色,如超人、蝙蝠侠、神奇女侠、史酷比以及瑞克和莫蒂等,生成高度相似甚至几乎一致的图像。华纳兄弟强调,这些角色不仅是流行文化的重要组成部分,更是数代人集体记忆的象征,具有巨大的商业价值。诉讼称,Midjourney“公然地将华纳兄弟探索公司的知识产权据为己有”,允许订阅用户“随意挑选标志性”的版权角色,并将其呈现在“各种可以想象的场景”中。
华纳兄弟指责Midjourney通过利用这些受版权保护的角色来推广其服务并从中获利。尽管此前迪士尼和环球影业已针对Midjourney提起类似诉讼,华纳兄弟声称Midjourney对此“蔑视不顾,未受阻碍”,甚至在近期移除了部分版权保护措施,以追求更大的利润。华纳兄弟寻求永久禁令,以阻止Midjourney继续生成“无数侵权图像”,并将其行为定性为“大规模、蓄意且持续不断”的侵权。

规避Midjourney辩护的关键法律策略
在早前的迪士尼/环球影业诉讼中,Midjourney曾辩称其系统是“基于数十亿公开可用图像”进行训练的,且生成图像并非通过检索数据库中的副本,而是基于“视觉特征与文本-图像对之间复杂的统计关系”。这种辩护旨在避免被认定为直接复制和分发版权图像。然而,华纳兄弟的诉讼采取了更为精妙的策略,试图绕过这一防御。
华纳兄弟的诉讼并未直接指控Midjourney存储其图像副本,而是提出了一个更具洞察力的论点:“Midjourney利用软件、服务器及其他技术,以一种将华纳兄弟探索公司的版权作品数据存储并固定在模型中的方式,使得这些作品得以体现在模型中,Midjourney随后能够从中生成、复制、公开展示和分发无限量的‘副本’和‘衍生作品’。”
法律专家指出,这一论点巧妙地将重点从“直接复制”转移到“数据体现”。即使Midjourney的模型内部不存储原始图像的像素数据,但如果它以某种方式“体现”了这些作品的特征和风格,并能据此生成高度相似的图像,那么这依然可能构成版权侵权。这种“体现”的论点,旨在迫使法院考虑,即使Midjourney未存储作品副本,其系统仍然能够“访问与作品相关的数据”,从而实现侵权行为。
侵权案例与用户行为分析
华纳兄弟的诉讼提供了多个Midjourney生成图像与原创作品高度匹配的实例。例如,用户通过输入“超人,经典卡通人物,DC漫画”这样的提示词,即可获得与超人形象几乎无异的图像。对于“蝙蝠侠,黑暗骑士的截屏”或“蝙蝠侠,DC漫画角色”,Midjourney也能生成高度还原的图像,甚至包括电影中的特定画面。


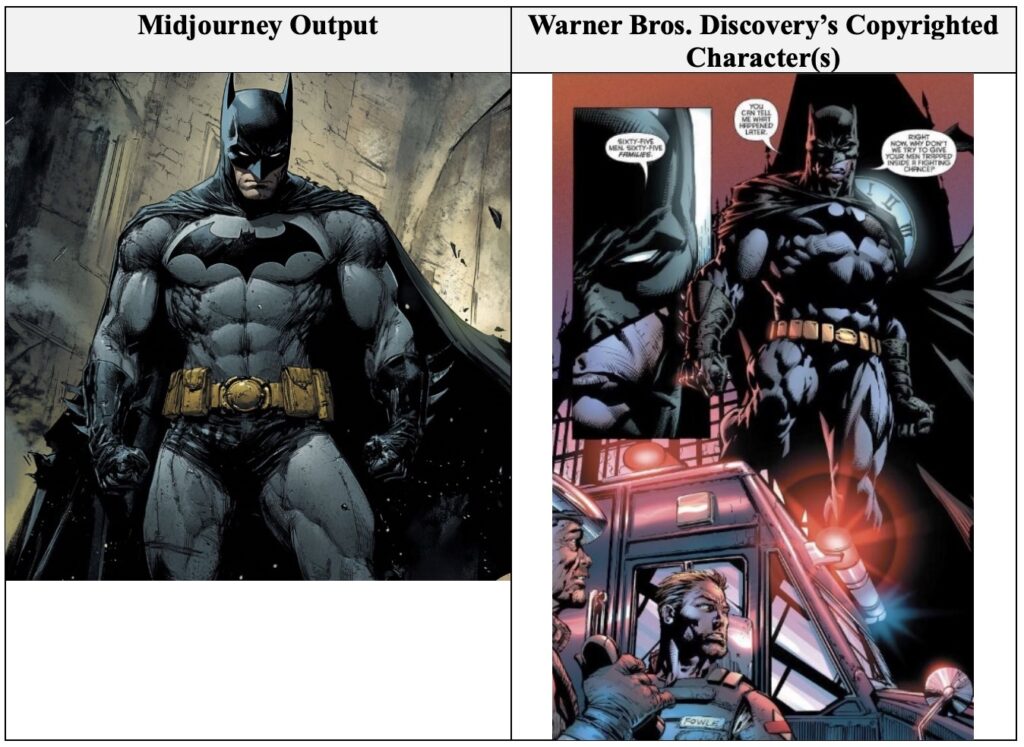
其他例子还包括“史酷比卡通人物站在老房子里的一个诡异房间里”和“瑞克和莫蒂,动画电视剧,截屏”等提示词,同样能生成出与原作品几乎无法区分的图像。这些例子不仅直接展示了侵权事实,也突显了AI生成工具在模仿特定风格和角色方面的强大能力。









