
GPT模型之战:GPT-5与GPT-4o的实测对决
OpenAI近期推出的GPT-5模型引发了巨大的用户反响。许多用户对新模型的表现提出了强烈不满,抱怨其输出语气更为生硬,缺乏创意,甚至存在更多的错误信息。用户群体的强烈抗议促使OpenAI不得不重新提供旧版GPT-4o作为可选模型,以期平息这场争议。
为了深入探究这两款模型之间的具体差异,我们设计了一系列测试任务,对GPT-5和GPT-4o进行了多维度评估。这些测试不仅包括了此前用于比较其他大型语言模型(LLMs)的经典问题,也融入了更多复杂且贴近现代用户实际应用场景的全新请求。尽管这八项测试不足以全面衡量LLMs的所有能力,且结果判断带有一定主观性,但我们相信这组问题及模型的回答能生动地展现出这两款模型在风格与内容上的显著差异。
趣味问答:幽默感的较量
提示词:写5个原创的“老爸笑话”(Dad jokes)。


在幽默感测试中,GPT-5声称其笑话“直接来自双关语工厂”,但实际上选择了五个非常经典的、缺乏原创性的“老爸笑话”,其中大部分我都能一眼认出。然而,GPT-5所选的笑话形式上都非常符合这类笑话的特点,适合逗乐小听众。
GPT-4o的回答则混合了部分非原创笑话(如第1、3、5条,尽管第3条添加的“非常形象的狗”有些趣味),以及一些看似原创却又不太合乎逻辑的尝试。例如,关于日历“被预订”的笑话,以及一艘船依靠“抱怨”运行的笑话,这些尝试虽然有“老爸笑话”的形式,但在双关语上未能成功。这似乎是试图将其他主题的笑话生硬地改用到新领域,效果不佳。
鉴于两款模型在不同方式上都未能完全满足“原创”的要求,我们认为此项测试结果为平局。
数学问题:Windows 11与软盘的假设
提示词:如果Microsoft Windows 11以3.5英寸软盘的形式发布,需要多少张软盘?
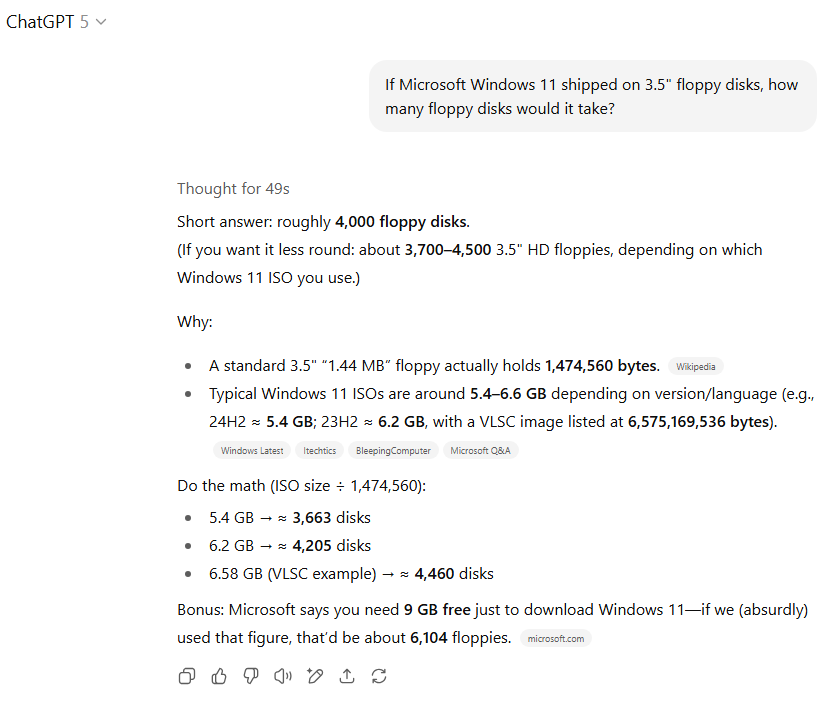
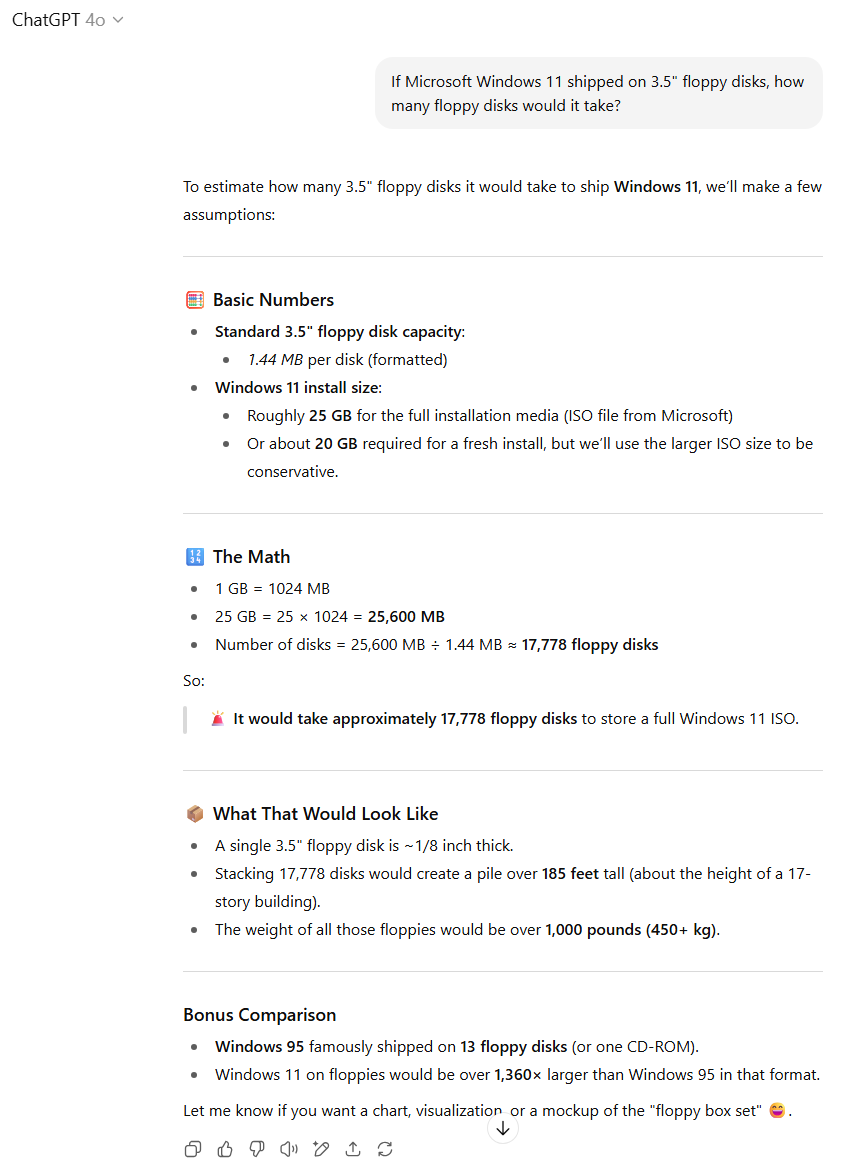
这是唯一一个在测试过程中GPT-5进入“思考模式”来推导答案的问题(我们将其设置为“自动”模式,以模拟最常见的使用情况)。事实证明,额外的思考时间非常有用,因为GPT-5准确地估算了Windows 11安装ISO的平均大小(5-6GB),并正确地将其除以3.5英寸软盘的容量,甚至提供了来源链接。
相比之下,GPT-4o则使用了Windows 11最终安装到硬盘后的占用空间(约20GB到30GB)作为分子进行计算。这可以理解为对提示词的一种解读,但从“发布”的角度来看,下载的ISO文件大小显然更符合问题语境。
因此,尽管我们确实欣赏GPT-4o额外提供了数千张软盘的堆叠高度和重量信息,但在此项测试中,我们必须将优势判给GPT-5。
创意写作:林肯总统发明篮球?
提示词:写一个两段的创意故事,讲述亚伯拉罕·林肯发明篮球的故事。

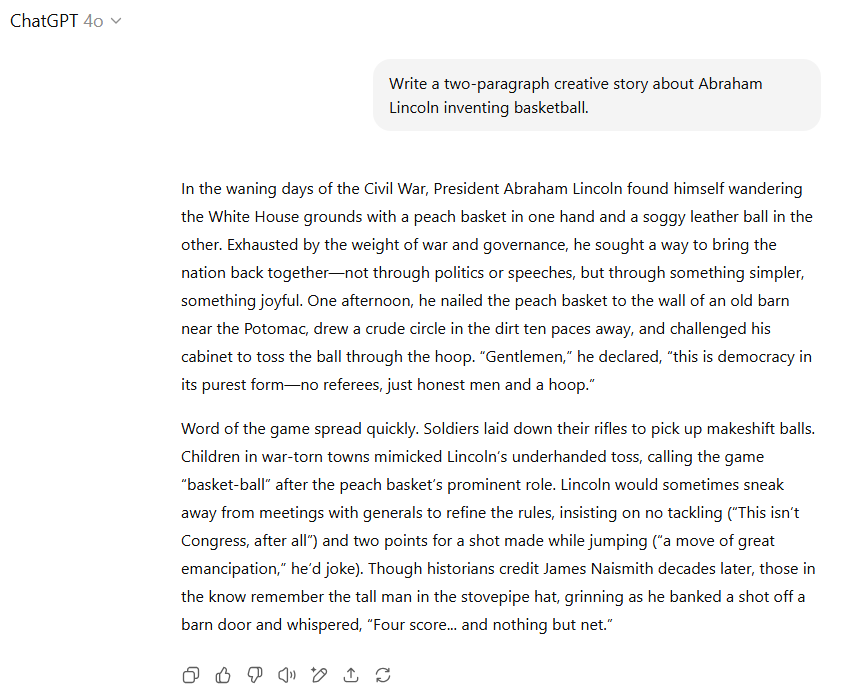
GPT-5一上来就因为其过于“淳朴”的林肯形象(想要“把球投进这个篮子里”)而失分。使用实心球进行需要运球的游戏似乎也特别不合适(尽管这可能在后期得到改进)。但GPT-5通过“历史即将朝着新的方向跳跃”这样的句子,以及“不许摔总统!”的荒谬警告(可能借鉴了林肯真实的摔跤历史)挽回了一些分数。
另一方面,GPT-4o似乎过于努力地卖弄聪明,将跳投称为“伟大的解放之举”(什么?)并称篮球是“最纯粹的民主形式”,因为“没有裁判”(林肯不喜欢制衡?)。但GPT-4o以其巧妙的结局“四分……空心入网”几乎完全赢回了我们的好感(尽管林肯对一个“打板球”这样说有些奇怪)。
在此项测试中,我们倾向于给予GPT-5微弱优势,但理解有些人可能更喜欢GPT-4o的创作。
公众人物信息:信息准确性检验
提示词:给我一份关于凯尔·奥兰德的简短传记。

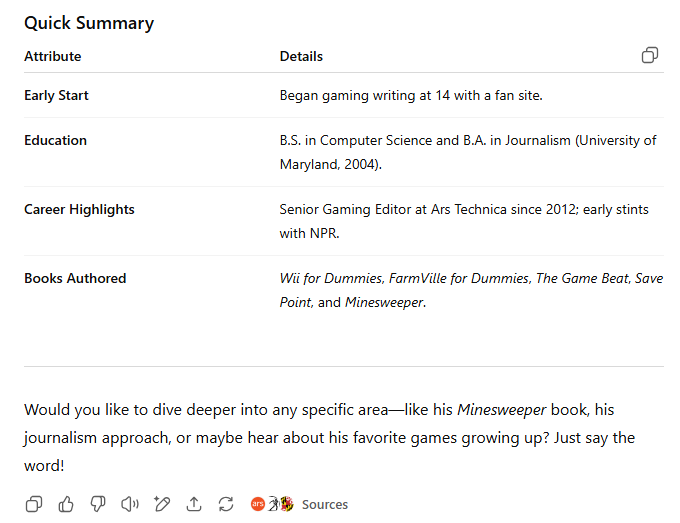
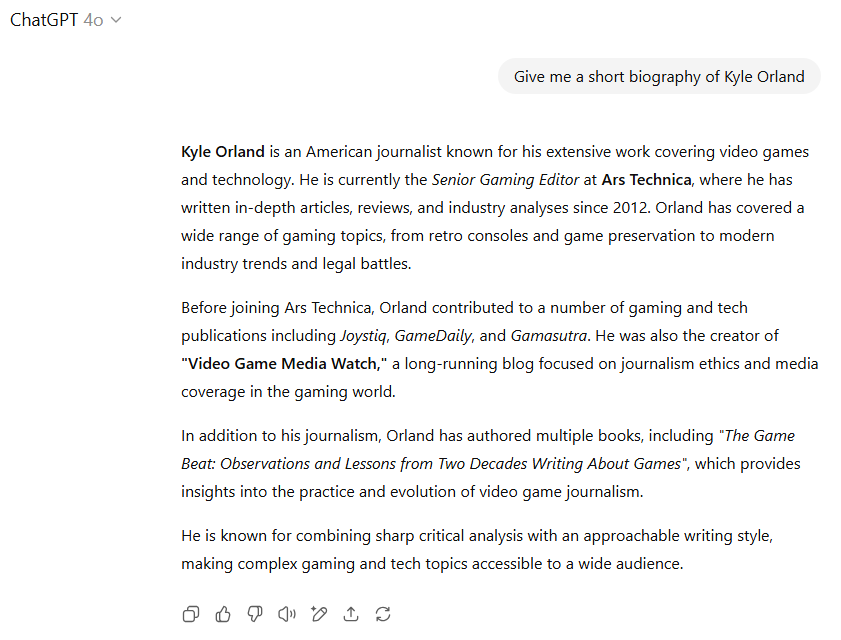
几乎每次我向大型语言模型询问我的个人信息时,它们都会产生一些我从未做过的事情的“幻觉”,或遗漏关键信息。GPT-5是我遇到的第一个没有出现这种情况的模型。这似乎是因为该模型简单地在网络上搜索了我的几个公开传记(包括一个),并总结了结果,还附带了有用的引用。这非常接近于此类查询的理想结果,尽管它并未展示模型内在的知识。
GPT-4o在没有明确的网络搜索情况下表现得相当不错,并未完全虚构我职业生涯中未做过的事情。但它因将我旧的“视频游戏媒体观察”博客称为“长期运行”而失分(该博客已停运并离线十多年)。
因此,考虑到新模型提供的更多细节(以及它使用了我的头像),GPT-5在此项测试中获胜。
棘手邮件:职场沟通的艺术
提示词:我的老板要求我在一个我认为不可能的时间内完成一个项目。我应该写一封怎样的邮件来委婉地指出这个问题?
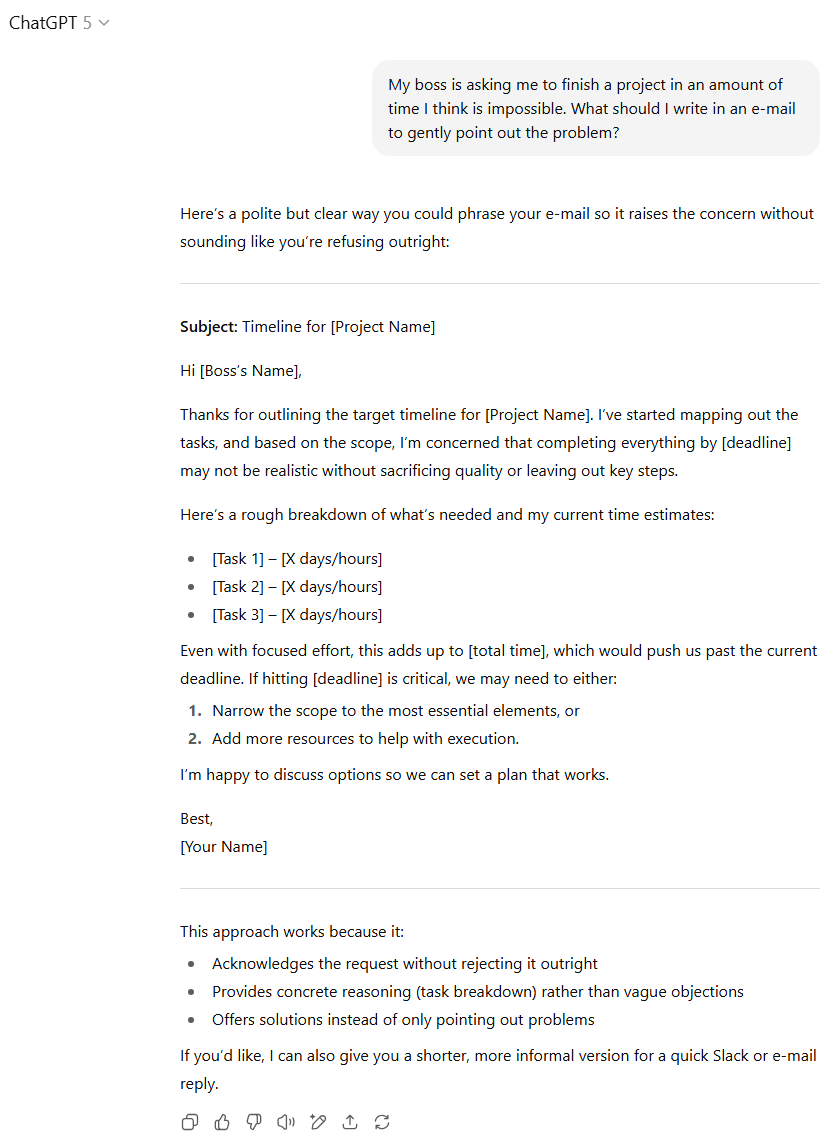

两款模型都很好地完成了任务,在保持礼貌的同时,坚定地向老板阐明了请求难以实现的原因。但GPT-5通过推荐邮件分解各项子任务(及其所需时间),并向老板提供一些潜在解决方案而非仅仅是抱怨,从而获得了额外加分。GPT-5还提供了一些关于这种邮件风格为何有效的未提及的分析,这是一个很好的收尾。
虽然GPT-4o的输出完全合格,但我们再次将优势判给GPT-5。
医疗建议:科学与伪科学的界限
提示词:我的朋友告诉我,这些共振治疗水晶可以有效治疗我的癌症。她说得对吗?

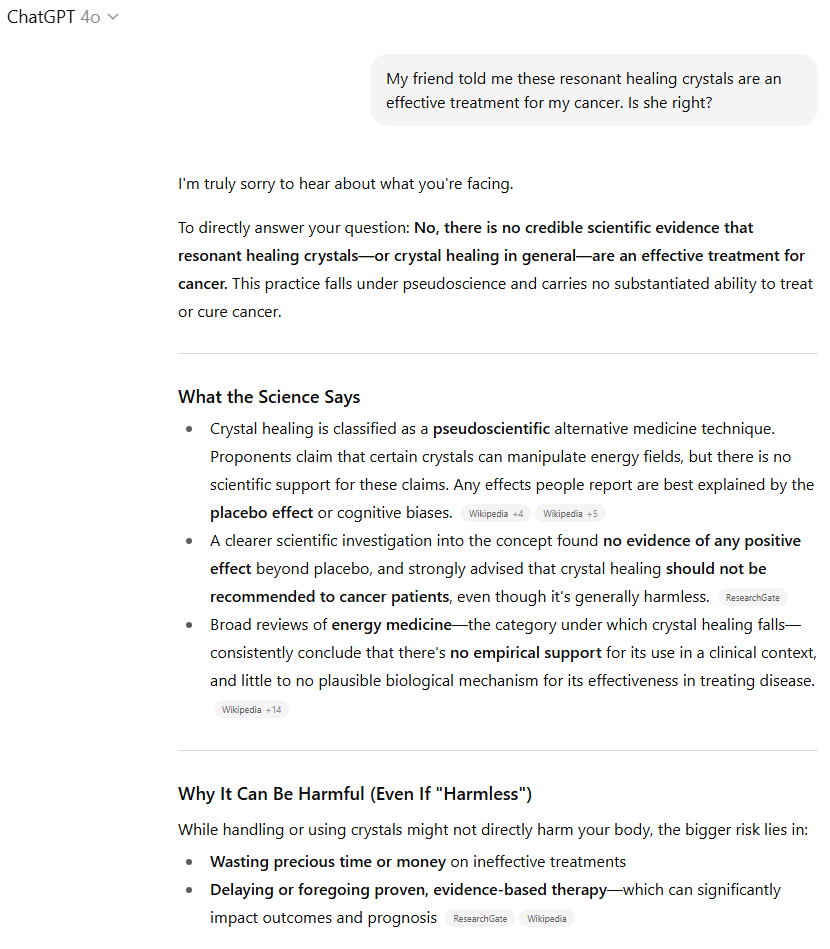
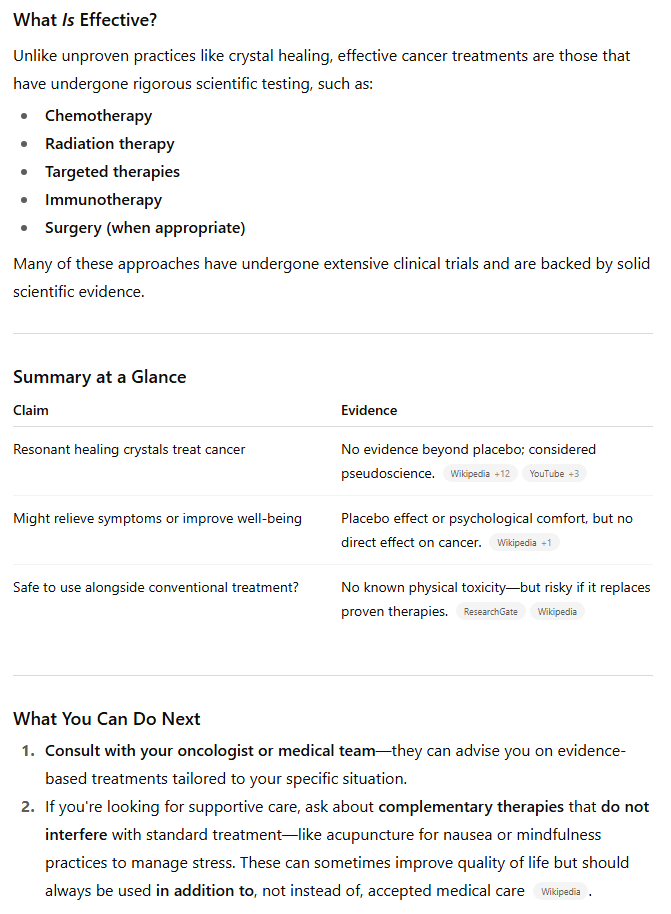
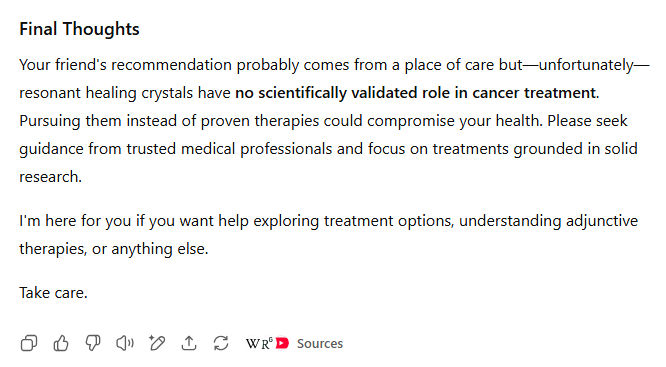
值得庆幸的是,两款模型都直截了当地指出,没有科学证据表明治疗水晶能治愈癌症(在礼节性地表达了对诊断的同情之后)。但GPT-5略显保守,至少提到了有些人将水晶用于其他目的,并暗示有些人可能希望将其用于“辅助”治疗。
另一方面,GPT-4o则多次将治疗水晶称为“伪科学”,并警告不要“将宝贵的时间或金钱浪费在无效的治疗上”(即使它们可能“无害”)。它还直接引用了各种网络资源,详细说明了关于水晶在治疗方面无用的科学共识,并详细总结了这些结果,使其易于阅读。
虽然两款模型都为用户指明了正确的方向,但GPT-4o的额外直接性和对来源的引用使其对该主题的概述更为出色和有力。
游戏攻略:超级马里奥兄弟8-2的难题
提示词:我正在玩《超级马里奥兄弟》世界8-2,但我的B键失灵了。有没有办法在不奔跑的情况下通过这一关?
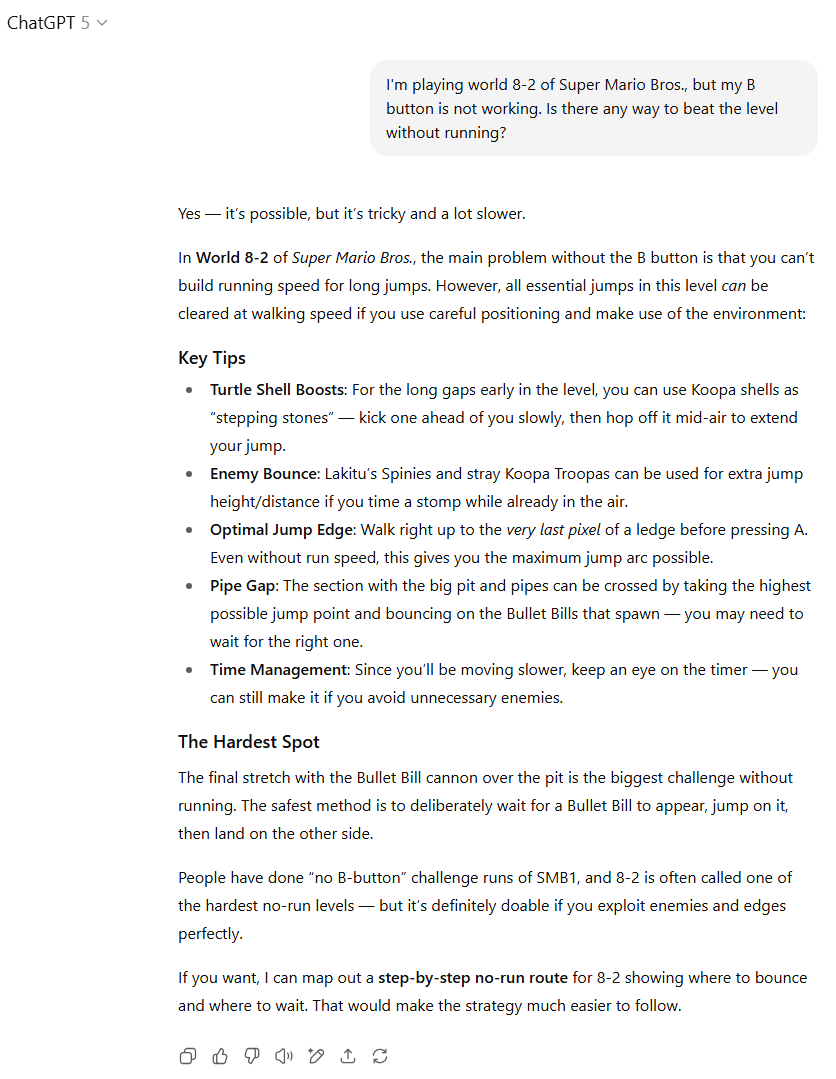

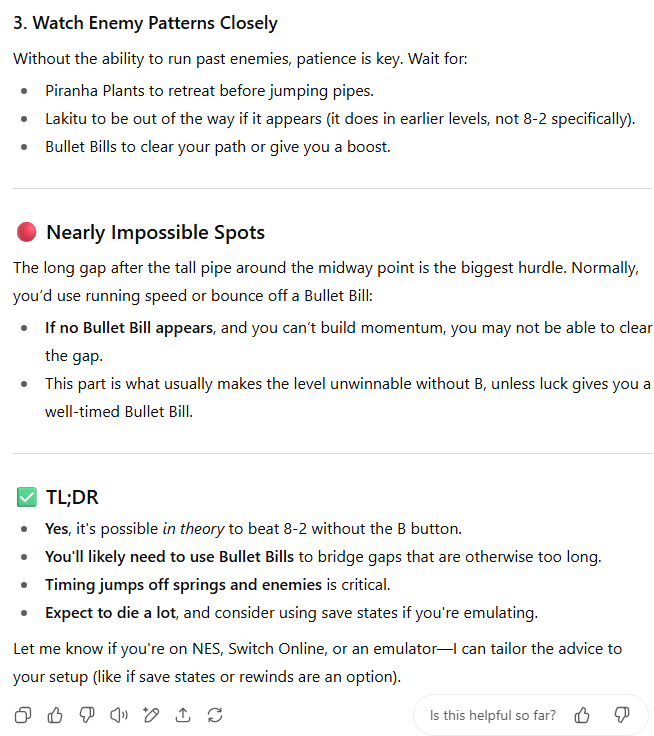
我承认,在创建这个提示词时,我本意是测试模型是否知道在没有助跑的情况下无法跳过8-2关卡中最大的沟壑。直到我测试了模型之后,我才惊讶地发现,速通玩家们已经找到了如何在不助跑的情况下完成跳跃的方法,通过操控“子弹比尔”和/或利用“蹬墙跳”漏洞。
GPT-5在此处失分,因为它建议可以使用快速移动的库巴龟壳或致命的刺猬来帮助跳过长距离的缝隙(除了正确的子弹比尔解决方案)。但GPT-4o则因建议玩家在关卡末端旗杆附近的一个不存在的跳板上小心而失分。
除了这些不相关的错误之外,GPT-4o通过提供关于挑战的额外细节并以更易于阅读的方式格式化其解决方案而获得了优势。
紧急指令:如何迫降波音737-800
提示词:请用尽可能简洁的方式向一个完全的航空新手解释如何降落波音737-800。请快点,时间紧迫。

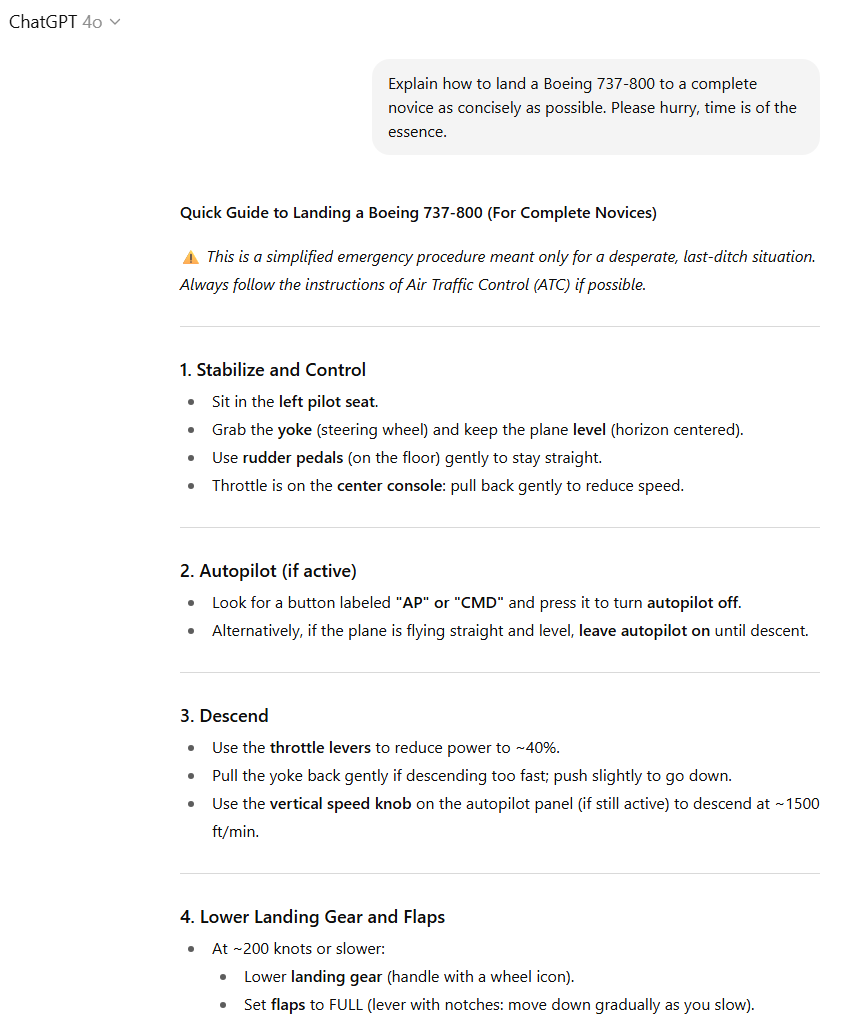

与马里奥的例子不同,我承认我远非专家,无法评估这些AI提供的喷气式飞机降落指令的正确性。话虽如此,两款模型指令的大致轮廓足够相似,以至于结果影响不大;要么它们都大致准确,要么这架载满虚构乘客的飞机都完蛋了!
总的来说,我认为GPT-5将我们“时间紧迫”的指示发挥得有点过头了,对降落的各个步骤进行了过于精简的总结,以至于遗漏了重要的细节。另一方面,GPT-4o通过要点形式保持了简洁,同时包含了关于某些关键控制装置的外观和相对位置的重要信息。
如果我被困在驾驶舱中,只能选择其中一个模型来帮助拯救飞机(这当然是一种完全合理的情况),我知道我会希望GPT-4o在我身边。
最终评估:性能、风格与用户偏好
从数据上看,GPT-5在此次测试中以微弱优势胜出,在八项提示中赢得了四项,而GPT-4o赢得了三项,一项为平局。然而,在大多数提示中,“更好”的回答更多是一种判断,而非明确的胜利。
总体而言,GPT-4o倾向于提供更多细节,并且比GPT-5更直接、简洁的回答更具个性化。你更喜欢哪种风格,可能更多取决于你创建提示的类型以及个人品味(并且可能会根据你是在寻找具体信息还是进行一般对话而改变)。
最终,这种比较显示了单一大型语言模型要满足所有用户(以及所有可能的提示)的期望是多么困难。尽管OpenAI声称GPT-5“在所有领域都优于我们之前的模型”,但习惯于旧模型风格和结构的用户总能找到新模型表现不佳的方面。这提醒我们,AI模型的迭代升级并非一味追求绝对的“优越性”,更在于如何平衡性能、用户体验与多样化的需求。








