
随着人工智能技术的飞速发展,大语言模型(LLM)已成为诸多应用的核心驱动力。然而,LLM在实际部署中面临的最大挑战之一便是其高昂的推理成本和相对缓慢的响应速度。传统的自回归生成模式,即逐个生成并验证词元(token),极大地限制了其在实时交互场景下的应用潜力。为了突破这一瓶颈,腾讯团队创新性地提出了FastMTP——一种针对大语言模型推理加速的开创性技术,它承诺在不牺牲输出质量的前提下,显著提升推理效率。
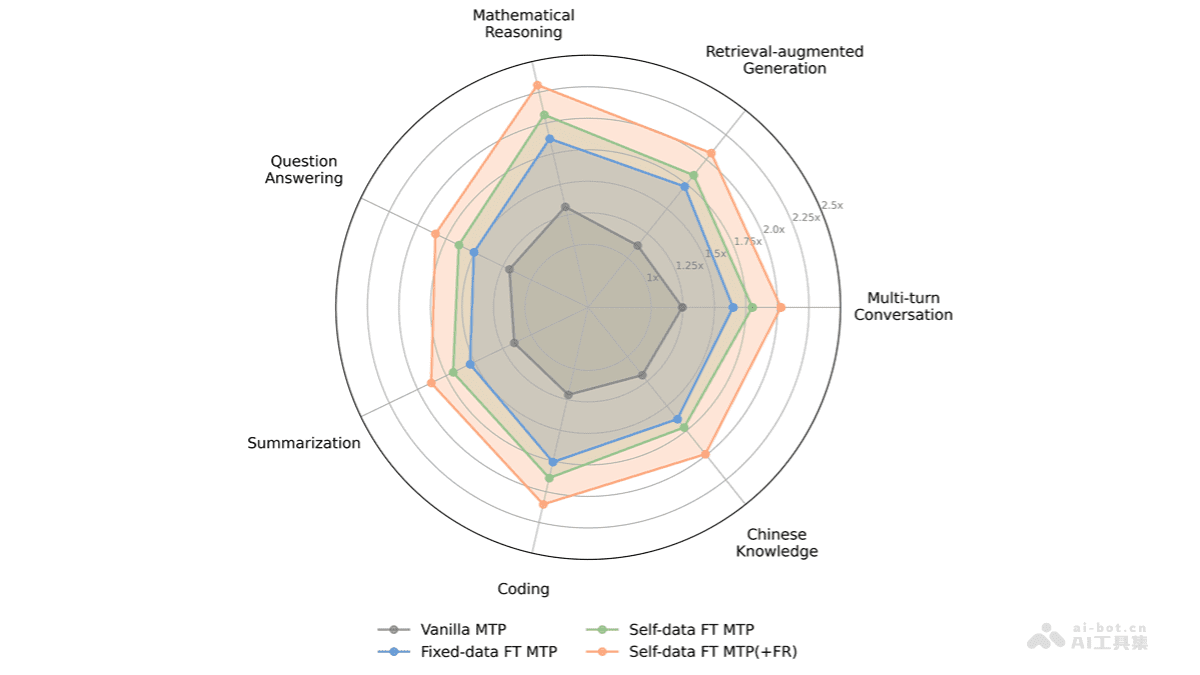
FastMTP的核心价值在于其对多标记预测(MTP)技术的深度优化。它颠覆了传统MTP中使用多个独立预测模块的设计,转而采用一种共享权重的单一MTP头。这种设计不仅极大地减少了内存占用,更迫使模型学习并生成更加连贯和高质量的“草稿序列”,为后续的主模型并行验证奠定了基础。结合语言感知词汇压缩和自蒸馏训练机制,FastMTP能够平均将LLM的推理速度提升2.03倍,为大模型的普适性应用开启了新的篇章。
FastMTP的变革性技术原理
FastMTP的卓越性能源于其精妙而协同工作的技术体系,主要涵盖以下几个核心支柱:
1. 投机解码(Speculative Decoding)策略
投机解码是一种受到人类阅读行为启发的智能加速策略。它引入了一个“草稿模型”(通常是一个更小、速度更快的模型)来先行预测一批未来的词元序列。这些预测并非最终输出,而是一种“猜测”。随后,主模型会并行地对这批草稿词元进行批量验证。如果草稿词元与主模型的预测一致,则可以一次性接受多个词元,从而显著减少主模型的计算步数。这种“先快速预读,再集中校验”的模式,有效打破了传统自回归生成中逐字逐句的瓶颈。
2. 共享权重的单一多标记预测(MTP)头
这是FastMTP区别于以往MTP方法的核心创新点。传统的MTP可能为每个预测位置配置独立的模块,导致模型庞大且内存消耗高昂。FastMTP则独辟蹊径,使用一个拥有共享权重的MTP头递归地生成多个候选标记。这种设计巧妙地减少了模型参数量和内存开销,同时通过强制模型在多步预测中复用同一套知识,促使其学习到更具泛化性和连贯性的长距离依赖关系,从而生成质量更高、更易被主模型接受的草稿序列。
3. 自蒸馏训练机制
为了确保MTP头生成的草稿序列能够最大程度地被主模型采纳,FastMTP引入了自蒸馏训练。在这种机制下,MTP头不是通过外部标注数据进行训练,而是直接以主模型生成的输出作为“教师信号”。通过一种指数衰减加权的交叉熵损失函数,MTP头被训练得能够优先学习生成与主模型风格和逻辑高度一致的词元。这种自我强化的学习过程,使得MTP头能够产生高质量的、与主模型预期更为接近的草稿,从而大幅提高投机解码的接受率,进一步增强了整体的推理效率。
4. 语言感知词汇压缩
在生成草稿阶段,为了进一步降低计算负担,FastMTP采用了语言感知词汇压缩技术。这意味着MTP头在预测词元时,会根据当前的输入语境智能地识别并仅计算与高频或高相关性词汇对应的logits。这种策略极大地减少了不必要的计算量,使得草稿生成过程更加迅速。而在主模型验证阶段,为了确保输出的精确性,则会使用完整的词汇表进行校验。这种分阶段、智能化的词汇处理方式,在保证输出质量的同时,实现了计算效率的最大化。
FastMTP带来的变革性优势
FastMTP不仅仅是一项技术优化,它为大语言模型的应用和普及带来了多方面的变革性优势:
显著的推理加速,提升用户体验:平均2.03倍的推理速度提升意味着LLM应用能够以更快的速度响应用户请求。在实时对话、智能客服或编程辅助等场景中,秒级的响应速度能够极大提升用户满意度,使AI工具更加实用和普及。
无损的输出质量,保障应用核心价值:与一些通过简化模型结构或量化来加速的方法不同,FastMTP承诺在加速推理的同时,完全保持主模型原有的输出质量。这意味着在追求速度的同时,无需担心生成内容的准确性、连贯性或逻辑性受损,这对于需要高精度输出的应用至关重要。
极佳的集成与部署灵活性,降低研发门槛:FastMTP不需要对主模型进行任何结构上的修改,只需引入一个轻量级的MTP头并进行微调。这种设计使其能够与现有的各类LLM推理框架(如SGLang)无缝集成,大大降低了开发者将其引入现有系统的技术成本和工作量,加速了创新应用的落地。
优化硬件资源利用率,推动普惠AI:通过共享权重的单一MTP头设计以及语言感知词汇压缩,FastMTP有效减少了模型的内存占用和计算需求。这意味着原本可能需要昂贵企业级GPU才能高效运行的大模型,现在可以在更经济的消费级GPU上实现更高效率的推理,从而降低了AI部署的门槛,使得更多个人和中小企业能够享受到大模型带来的便利。
多元化应用场景的潜力
FastMTP的加速能力使其能够广泛应用于需要快速响应和高质量输出的LLM任务中:
数学推理与科学计算:在智能数学辅导系统或科学研究中,FastMTP能够驱动LLM迅速生成复杂的解题步骤、逻辑推导或实验方案,将从问题输入到答案输出的时间缩短至毫秒级别,实现流畅的互动式学习和探索体验。
高效代码生成与辅助编程:对于开发者而言,编程辅助工具的响应速度直接影响开发效率。FastMTP能够使这类工具更快地生成代码片段、函数实现或错误修复建议,极大提升编码效率,并赋能更智能的集成开发环境。
长文本摘要与信息提炼:在处理海量新闻、报告或文献时,FastMTP可使模型快速阅读并提炼核心信息,生成高质量的摘要内容。这不仅节省了用户宝贵的时间,也提高了信息检索和处理的效率。
多轮对话与智能客服:在智能客服机器人、虚拟助理或开放域聊天中,FastMTP通过加速对话生成,实现了接近人类对话的秒级响应速度,显著提升了用户体验和交互的自然流畅度,让AI交流不再有明显的延迟感。
展望与行业影响
FastMTP作为腾讯开源的一项前沿技术,不仅代表了大模型推理加速领域的重大突破,更体现了开源社区在推动AI技术普及和创新方面的重要作用。通过提供一个高效、易用且无损质量的加速方案,FastMTP有望成为LLM部署的标准组件之一,进一步降低高性能AI模型的应用壁垒。它的出现预示着大语言模型将能够更加深入、广泛地融入我们的日常生活和各行各业,推动新一代智能应用的加速迭代和发展,为构建更加智能、高效的数字未来奠定坚实基础。这项技术证明了持续优化底层基础设施对于释放AI潜力的关键意义,并激励着业界共同探索更高效的AI解决方案。






