
人工智能领域在2025年末迎来了一系列突破性进展,从开源模型发布到国际化布局,从大模型研发到音乐版权合作,这些创新不仅重塑了技术边界,也为开发者和用户带来了前所未有的应用体验。本文将深入分析这些最新动态,探讨它们对AI行业生态的影响与未来发展趋势。
FLUX.2开源发布:图像生成领域的新里程碑
Black Forest Labs正式发布的FLUX.2系列模型标志着图像生成技术进入新阶段。该系列包含pro、flex、dev和klein四个版本,其中dev版本开源了32B参数的权重与代码,为开发者提供了前所未有的透明度和可定制性。
核心技术突破
FLUX.2系列模型的最大亮点在于其多项技术创新:
- 多图参考功能:支持最多10张风格/构图样例,生成一致性超过95%,解决了传统图像生成中风格难以控制的痛点
- 4MP分辨率编辑:提供高分辨率编辑能力,支持局部重绘、去水印及背景替换等精细化操作
- 文本渲染优化:显著提升了文本生成质量,解决了以往AI图像中文字识别率低的问题
- 现实逻辑增强:生成的图像更符合物理规律和视觉常识,减少了不合理元素的出现

开发者友好型生态
FLUX.2不仅技术先进,更注重开发者体验:
- 提供PyTorch、Diffusers和ComfyUI等多种框架支持,降低接入门槛
- 配备完善的在线Demo,开发者可快速体验模型能力
- 开源代码库包含详细文档和示例代码,加速应用开发
这些特性使FLUX.2成为开发者探索图像生成新可能性的理想工具,预计将催生一批创新应用,从游戏资产创建到产品可视化,再到艺术创作等多个领域。
腾讯混元3D创作引擎:国际化战略的关键一步
腾讯混元3D创作引擎国际站的上线,标志着腾讯在3D内容生成领域的全球化布局加速。这一举措不仅为海外用户提供了便捷的3D创作工具,也为开发者打开了新的商业机会。
简化3D创作流程
混元3D创作引擎的核心优势在于其极简的用户体验:
- 零配置环境:用户无需下载复杂工具或配置专业环境,直接通过浏览器即可使用
- 多模态输入支持:接受文字描述、图片参考或草图输入,满足不同用户的创作习惯
- 实时预览功能:提供即时反馈,让用户能够快速迭代和优化创作

开发者API生态
面向专业用户,混元3D提供了强大的API接口:
- 模型生成API:开发者可将3D模型生成能力集成到自有应用中
- 定制化训练接口:支持基于特定领域数据集训练专属模型
- 资源管理工具:提供模型存储、版本控制等企业级功能
这一战略布局使腾讯能够在竞争激烈的3D内容生成市场中占据有利位置,特别是在游戏、建筑可视化和电商展示等领域具有广阔应用前景。
字节跳动TRAE SOLO模式:从代码生成到软件交付的深度转型
字节跳动TRAE的SOLO模式中国版上线,代表了AI辅助开发工具从单一功能向全流程解决方案的演进。这一转变不仅提高了开发效率,也重新定义了人机协作的开发模式。
"上下文工程"理念
SOLO模式的核心创新在于其"上下文工程"理念:
- 端到端闭环:实现从需求分析到部署上线的完整流程自动化
- 上下文理解:系统能够理解项目背景、代码风格和业务逻辑,生成更符合预期的代码
- 持续学习机制:根据用户反馈不断优化代码生成质量
智能体能力升级
SOLO Coder智能体展现了强大的任务处理能力:
- 复杂任务优化:支持功能迭代、代码重构和Bug修复等高级操作
- 多语言支持:覆盖主流编程语言和框架,适应不同技术栈
- 自然语言驱动:开发者可用日常语言描述需求,系统自动转换为可执行代码
这种全流程自动化的开发模式有望大幅提高软件交付效率,特别是在快速迭代的项目中具有显著优势。同时,它也为初级开发者提供了强大的辅助工具,降低了编程门槛。
百度大模型战略:双部门架构加速AI技术布局
百度近期宣布设立两个新的大模型研发部门,展现了其在AI领域的战略雄心。这一组织架构调整反映了百度对大模型技术的高度重视,以及推动技术与应用协同发展的清晰思路。
基础模型研发部:通用AI的探索
基础模型研发部由吴甜负责,专注于:
- 高智能通用模型:开发具有更强推理能力和知识储备的基础大模型
- 多模态融合技术:整合文本、图像、音频等多种模态,实现更全面的理解与生成
- 模型效率优化:在保持性能的同时降低计算资源消耗,提高部署可行性
应用模型研发部:场景化落地的推动
应用模型研发部由贾磊领导,聚焦:
- 行业专精模型:针对医疗、金融、教育等特定领域开发专业模型
- 业务场景适配:将大模型能力与企业实际需求深度结合
- 轻量化部署方案:提供适合不同规模企业的模型部署选项

这两个部门均直接向CEO李彦宏汇报,体现了百度对大模型战略的重视。结合文心大模型5.0的全模态理解与生成能力,百度正在构建一个从基础研究到应用落地的完整AI技术体系。
OpenAI ChatGPT语音升级:多模态互动的新体验
OpenAI对ChatGPT的语音功能升级,实现了语音与文本的无缝结合,为用户提供了更自然、更丰富的交互体验。这一改进不仅提升了用户体验,也为AI助手在更多场景的应用铺平了道路。
语音与文本的无缝融合
升级后的ChatGPT语音功能具有以下特点:
- 实时语音交互:用户可直接通过语音提问,获得即时回应
- 视觉信息同步:语音对话时,系统实时展示相关视觉内容,如地图、图表等
- 文字自动转录:对话内容自动生成文字记录,方便用户回顾和分享
灵活的交互模式
OpenAI保留了传统语音模式的同时,提供了新的融合选项:
- 独立语音模式:专注于语音对话,适合电话、车载等场景
- 融合交互模式:语音与文本界面结合,支持多任务处理
- 自动切换机制:根据使用场景智能推荐最适合的交互方式
这一升级使ChatGPT能够更好地适应不同使用场景,从专业会议到日常咨询,从教育辅导到创意协作,语音功能的加入大大扩展了AI助手的应用边界。
Amazon Kiro战略:自研AI工具的全面推广
Amazon内部备忘录显示,公司正积极推广自研AI编程工具Kiro,并限制第三方服务的使用。这一策略反映了科技巨头在AI基础设施领域的竞争加剧,以及企业对AI安全与可控性的日益重视。
Kiro的核心优势
Amazon Kiro作为自研AI编程工具,具备以下特点:
- 深度集成:与Amazon云服务和开发工具链无缝对接
- 企业级安全:符合Amazon严格的数据安全和隐私标准
- 定制化能力:可根据企业特定需求进行优化和扩展
战略转变背后的考量
Amazon这一策略调整有多重考量:
- 技术自主权:减少对第三方AI服务的依赖,掌握核心技术
- 成本控制:长期使用自研工具可降低AI应用成本
- 数据安全:企业代码和敏感数据不离开Amazon生态系统
这一趋势不仅出现在Amazon,微软、Google等科技巨头也在加强自研AI工具的布局。未来,企业级AI市场可能形成"自研+开源"的双轨发展模式,一方面大型企业构建专属AI能力,另一方面开源社区提供创新基础。
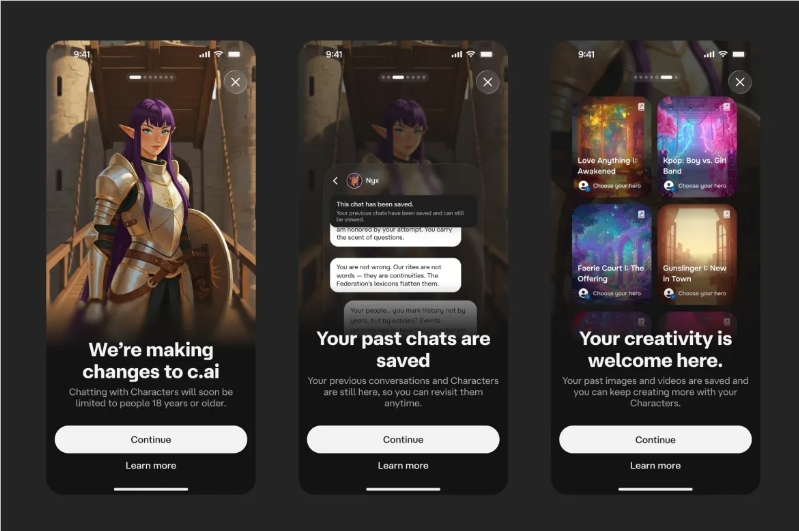
Character.AI Stories:AI互动内容的安全新模式
Character.AI推出的Stories功能,标志着AI内容生成从简单对话向结构化互动体验的演进。同时,平台对未成年用户的全面保护措施,也为AI内容安全提供了新的解决方案。
互动小说的创新形式
Stories功能具有以下特点:
- 多分支叙事:用户可创作具有多个选择路径的互动故事
- 角色扮演增强:AI角色扮演从开放式聊天转向剧本式互动
- 内容审核机制:内置多层审核系统,确保内容适宜性
安全优先的青少年保护
Character.AI在青少年保护方面采取了严格措施:
- 年龄验证强化:严格禁止18岁以下用户进行开放式对话
- 内容分级制度:根据不同年龄段提供差异化的内容体验
- 家长控制功能:允许家长设置使用时间和内容限制
这一模式为AI内容生成提供了安全与创意平衡的范例,既保护了未成年人,又为成人用户提供了丰富的互动体验。未来,随着教育IP合作的引入,Stories功能有望在在线教育领域发挥更大作用。
WMG与Suno合作:AI音乐版权新模式
Warner Music Group与AI音乐平台Suno达成的版权和解,不仅解决了当前的版权争议,更开创了"付费下载+可控声纹"的AI音乐商业模式,为整个行业树立了新标准。
授权模式的创新
新的授权协议包含以下关键要素:
- 进阶授权模型:艺术家可自主控制姓名、肖像、声音和作品的使用权限
- 分级付费体系:免费用户仅能播放与分享,付费用户可下载高质量音频
- 声纹保护技术:系统内置"声纹指纹+水印",有效拦截未经授权的AI翻唱
行业连锁反应
这一合作产生了广泛影响:
- 估值提升:Suno估值达24.5亿美元,显示资本市场对AI音乐前景的信心
- 行业标准形成:其他音乐公司可能效仿类似模式,建立AI音乐授权框架
- 创作者权益保障:通过技术手段确保艺术家对自身声音和作品的控制权

这一合作标志着AI音乐行业从争议走向规范,从技术探索走向商业成熟。未来,随着更多音乐公司的加入,AI音乐有望形成更加健康、可持续的生态系统。
AI技术发展趋势与行业影响
综合以上分析,我们可以看到AI技术正在多个维度同时发展,从底层模型到应用场景,从技术创新到商业模式,共同塑造着AI行业的未来格局。
技术融合加速
当前AI技术发展呈现出明显的融合趋势:
- 多模态能力整合:文本、图像、音频、视频等多种模态的协同处理能力不断提升
- 端到端自动化:从需求分析到部署上线的全流程自动化,提高开发效率
- 个性化定制:模型能够根据用户特定需求进行定制化调整,提供更精准的服务
商业模式创新
AI应用的商业模式也在不断创新:
- 分层授权模式:如Suno的分级付费体系,平衡免费使用与商业价值
- 开发者生态构建:通过API和工具链,吸引开发者共建应用生态
- 行业垂直解决方案:针对特定行业需求开发专业AI解决方案
安全与伦理并重
随着AI技术普及,安全与伦理问题日益突出:
- 内容审核机制:多层审核确保AI生成内容的安全性
- 未成年人保护:严格的年龄验证和使用限制
- 知识产权保护:通过技术手段保护原创者权益
结语:AI创新生态的多元化发展
从FLUX.2的开源发布到腾讯混元3D的国际化,从百度的大模型战略到WMG与Suno的音乐合作,这些最新动态共同描绘了一幅AI技术多元化发展的图景。开源与闭源并存,通用与专用并重,技术创新与商业模式协同,安全与创意平衡,这些特点共同构成了当前AI生态的复杂面貌。
未来,随着大模型技术的持续突破和应用场景的不断拓展,AI将进一步融入各行各业,深刻改变人们的工作与生活方式。而开发者作为连接技术与应用的关键纽带,将在这一变革中发挥越来越重要的作用。对于企业和个人而言,把握AI技术趋势,积极参与创新生态,将是应对未来挑战的关键策略。
在这个快速发展的AI时代,唯有持续学习、勇于创新,才能在技术浪潮中把握先机,共同塑造一个更加智能、更加美好的未来。








