
在数字化与智能化浪潮的驱动下,AI正成为推动科研进步与产业升级的核心引擎。无论是气象模拟、海洋研究,还是医药研发、工业设计,算力已逐渐演变为关键资源,而智算中心则成为这一进程的重要承载平台。本文将深入探讨北京正阳恒卓科技有限公司为某超大型智算中心规划的1000PFlops@FP16规模算力集群项目,剖析其技术创新与实施策略。
超大规模智算集群建设的时代背景
随着AI技术的快速发展,对高性能计算的需求呈现指数级增长。传统计算架构已难以满足大规模并行计算与海量数据交互的需求,亟需构建新型智算基础设施。在此背景下,正阳恒卓依托NVIDIA全栈式解决方案,成功交付了这一超大型智算中心项目,实现了算力密度与系统稳定性的双重突破。

该项目的成功不仅体现了AI基础设施建设的系统工程特性,更为行业提供了可借鉴的实施经验。通过从硬件到软件的全面系统性开发,以及对稳定性和高效性技术的封装,正阳恒卓展示了高性能、高稳定性如何成为智算中心的基本能力和发展趋势。
超大规模智算集群建设挑战
网络架构的极致性能需求
该超算中心面向气候模拟、药物研发等前沿任务,对网络架构提出了极高要求。计算网络需实现400Gbps节点间通信,存储网络需达到200Gbps带宽,同时整体延迟需控制在亚微秒级别。这种极致性能需求对网络拓扑设计与硬件选型提出了严苛挑战,任何设计缺陷都可能成为系统瓶颈。
大规模部署的物理限制
与同等规模项目通常需要6-12个月的建设周期相比,该项目必须在3个月内完成跨A、B两个机房的硬件集成。计算服务器位于A机房,存储与安全设备部署于B机房,而存储网络的跨机房布线需克服200G AOC线缆100米的传输距离限制。这一物理限制极大增加了部署复杂度,要求精确的规划与执行。
现场施工的适应性调整
项目实施过程中面临施工环境与原设计不符的挑战。原设计采用上走线方案,但实际机房为下走线布局,导致线槽操作空间狭窄、焊接式设计穿线困难。工人在无法站立行走的环境中作业,直接影响了施工进度与质量。这一挑战要求项目团队具备快速响应与灵活调整的能力。
系统性构建高效可靠的AI算力集群
高速互连:借助NVIDIA InfiniBand构建高效网络架构
面对网络性能挑战,正阳恒卓采用了NVIDIA Quantum InfiniBand这一全球唯一完全硬件卸载的网络计算平台。该平台具备卓越的数据吞吐量和端口密度,并支持网络自愈、增强服务质量(QoS)、拥塞控制和动态路由等特性,使数据中心能够以更低的成本和复杂性实现出色性能。

在网络架构设计上,项目采用了NVIDIA Quantum QM9790 NDR 400G InfiniBand交换机作为核心交换设备,构建了无阻塞胖树组网架构,包含8台Spine交换机和16台Leaf交换机。这种架构保证了任意节点间的数据传输路径始终等价,避免了网络拥塞和带宽瓶颈,从而实现超低延迟和超高吞吐量。
同时,项目部署了1000多条400G MPO线缆确保高速连接,总长度达20公里。通过精细化的机柜空间规划和布线路径设计,实现了高密度互连与稳定的高速传输,有效保障了大规模集群的高效运行。

在存储网络方面,项目采用NVIDIA Quantum QM8790 HDR 200G InfiniBand交换机作为核心设备,构建了Spine-Leaf架构(10台Spine和11台Leaf),使用400多条200G AOC线缆进行连接。这一架构不仅保证了存储节点之间的多路径并行访问能力,显著提升了I/O并发处理效率,还能在大规模并发读写时保持稳定的低延迟表现。

NVIDIA InfiniBank的SHARP™技术可卸载聚合通信运算、减少数据传输量并缩短消息传递时间;网络自愈功能能快速应对链路故障,实现远超软件方案的恢复速度;成熟的服务质量机制提供高级拥塞控制和动态路由;并支持多种网络拓扑及优化路由算法,从而进一步提升整体数据中心的吞吐效率和稳定性。
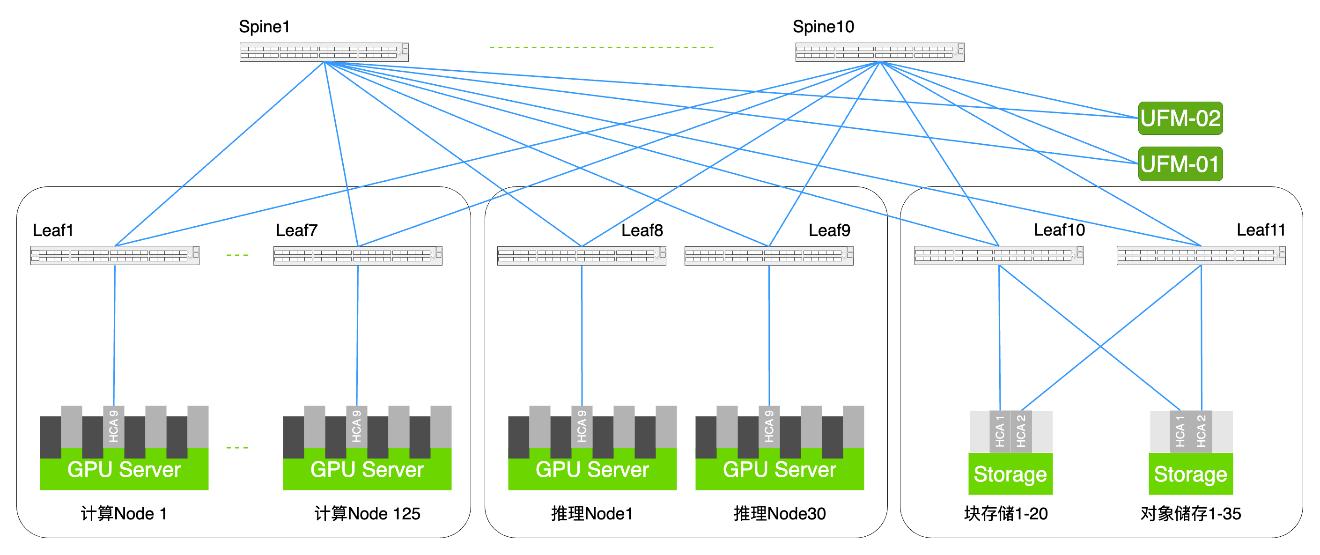
通过这些创新设计,整体系统在实际运行中实现了1TB/s级别的数据流动,为大数据分析、AI训练和科学计算工作负载提供了极高的存储吞吐能力。
复杂部署环境中的施工优化与调整
针对跨机房布线难题,项目团队通过精确测量机房间距与设备位置,反复推演布线方案,最终合理规划交换机安装位置,确保所有跨机房连接线缆连接都严格控制在100米限制内。同时,跨机房AOC线缆采用了特殊保护套管,防止线缆受损,并在关键路径部署了冗余连接,保证了整体网络的稳定性和安全性。
在高压之下,项目团队在仅有不到1周时间内完成了走线方案的全面重新设计,制定了精确到机柜和管槽的下走线规划图,并通过线缆长度自动计算工具快速生成并更新了上千条线缆的采购清单。
为保障进度,正阳恒卓同步优化了施工计划与人员安排,将原本顺序式的施工转为多工序并行,增派数十名工程人员分批次开展布线作业,确保在拥挤、工人无法站立的机柜底部空间中依然能够有序推进。对于不合理的焊接式线槽,项目团队还协调相关方拆除并重新设计为卡扣式线槽,大幅提高了穿线效率,最终在紧迫工期内完成了高密度布线任务。
NVIDIA UFM平台赋能智算中心的智能化运维
在软件与管理层面,正阳恒卓为该超大型智算中心引入了NVIDIA UFM平台,这一平台能够实时监控网络的性能与健康状态,提供自动化故障诊断与报警,以及流量分析与优化建议。NVIDIA UFM平台将增强的实时网络遥测与AI驱动的网络智能和分析相结合,为InfiniBand高性能数据中心网络的高效调配、监控、管理和预防性故障排除提供了强大支持。
通过UFM平台的智能运维,智算中心实现了网络零宕机的优秀记录,系统能够提前发现潜在问题,避免故障发生,为科研任务提供了稳定可靠的算力保障。
打造科学计算平台,支撑多领域科研突破
通过正阳恒卓专业的技术方案和高效的落地实施,该智算中心项目在NVIDIA网络解决方案的赋能下取得了显著成果。精准的网络架构设计与优化部署确保了大规模分布式训练能够顺利进行,实现了规模扩展和硬件升级带来的性能提升。
系统稳定运行表现同样令人印象深刻,项目交付后持续稳定运行,实现了网络零宕机的优秀记录。这一成果得益于NVIDIA UFM监控系统能够提前发现潜在问题,避免故障发生。
在支持科研突破方面,该智算中心已经为多个大型科研项目提供了强大算力支持,加速了AI产业发展与数字化转型:
- 气象领域:参与精细化气象预报,提高了天气预报的准确性和时效性;
- 海洋科学:与高校合作开展海洋环境模拟,支持海洋生态系统研究和气候变化分析;
- 医药研发:加速新药分子筛选与蛋白质结构解析,缩短药物研发周期;
- 工业领域:支持重工领域在高端装备制造中的仿真设计,大幅降低研发成本;
- 大型科技项目:支撑大飞机、深空探测等大型科技项目的计算需求。

构建智算生态新格局
这一超大型智算中心项目的成功,不仅推动了科研与产业的融合发展,也为智算建设积累了宝贵经验。正阳恒卓计划将该项目的成功实践推广至更多大型智算中心,并与高校共建联合实验室,培养新一代科学计算人才。
作为NVIDIA网络产品精英级合作伙伴,未来,正阳恒卓致力于将领先的智算中心网络解决方案应用于各行各业,助力更多行业实现智能化转型与升级,探索智算中心在智慧城市、生命科学、工业互联网等更多应用场景中的潜力。
AI基础设施建设是一个系统工程,需要从硬件到软件进行全面系统性开发,并将具备稳定性和高效性的技术进行封装,对用户尽可能透明。正阳恒卓通过这一项目,展示了高性能、高稳定性如何成为智算中心的基本能力和发展趋势,为行业树立了新的标杆。








