
在visionOS 26系统更新和全新Vision Pro硬件发布之际,我们有必要重新审视苹果这款头显设备。作为一位在2024年初Vision Pro发布时就体验过它的用户,我对这款产品既惊叹又失望。如今,经过几个月的使用和观察,我发现Vision Pro正站在一个关键的十字路口,苹果需要做出一些艰难的决策。
初体验:从兴奋到平淡
当我第一次获得Vision Pro时,我确实频繁使用它:在飞机和酒店房间里观看电影,在家中放置应用程序窗口并测试新的工作方式,尝试各种有趣的游戏和教育应用,观看所有能找到的沉浸式视频,甚至尝试为其开发自己的应用程序。
然而,随着时间推移,我使用它的频率逐渐降低。新鲜感消退后,实用性战胜了酷炫感。在苹果几周前寄给我新款机型之前,我已经有几个月几乎没有使用过原来的设备。我基本上停止了在家中使用它,但偶尔仍会带着它旅行,作为酒店房间的娱乐设备。
这并非个例。即使在Vision Pro拥有者的子版块——本应是设备最忠实粉丝的聚集地——人们也说:"这真的很酷,但我必须特意去使用它。"如果开发者和内容创作者的支持更加强大,也许它更容易融入我的日常生活,但这又是一个典型的鸡与蛋的问题。
新款Vision Pro:硬件改进有限
双编织头带:舒适度的提升
对于许多用户来说,新款Vision Pro最显著的变化是可以通过额外购买(尽管价格不菲)为旧款设备获得的新配件:一个新的头带,能更好地平衡设备在头部的重量,使长时间佩戴更加舒适。
被称为"双编织头带"(Dual Knit Band)的设计巧妙地包含一个简单的调节旋钮,可以收紧或放松绕过头部后方的带子(类似于旧款头带)或环绕顶部的带子。

这个设计很出色,可能会让许多觉得旧款设备太不舒服的用户更容易使用Vision Pro,尽管这款新机型比前代稍重。
我是少数从未遇到任何不适问题的幸运儿之一,但我认识一些人,他们说设备对前额的压力令人无法忍受。这正是新头带解决的问题,所以看到这一改进令人欣慰。
M5芯片:不仅仅是速度的提升
首款Vision Pro搭载的是苹果M2芯片——在发布时就已经有些落后于时代,而新版本则升级为M5芯片。它更快,特别是在图形处理和机器学习任务方面。如果您有兴趣了解更多关于M5的信息,我们已经在我们关于其他苹果产品的文章中详细讨论过。
功能上,这意味着许多小事情变得更快,比如启动某些应用程序或生成Persona头像。坦率地说,我没有注意到对用户体验有重大差异的变化。我不是说有时我无法察觉到它更快,我只是说这种提升不够有意义,无法改变人们对设备的任何态度。
在游戏中这种提升最为明显——无论是原生的混合现实Vision Pro游戏,还是可以在设备虚拟显示器上运行的iPad版本的高要求游戏。在许多情况下,要求高的3D游戏看起来和运行效果都更好。M5还支持更新的图形技术,如光线追踪和网格着色,尽管很少有游戏支持这些技术,即使是iPad版本也是如此。
总而言之,虽然我总是欢迎性能提升,但它们绝对不足以说服M2 Vision Pro所有者升级,也不会让那些一直在犹豫是否购买这类设备的人改变主意。
新芯片的主要优势是提高了效率,这是电池寿命适度增加的驱动力。当我第一次带着M2 Vision Pro乘飞机时,我尝试观看2021年的《沙丘》。我勉强看完了电影,但在片尾字幕时电池耗尽了。这不算是一部短电影,但还有更长的。
现在,新头显可以额外获得30或60分钟的续航时间,具体取决于您在做什么,这终于使其进入了"可以观看任何您想看的电影"的范畴。
考虑到原始版本电池寿命如此之短,即使是适度的提升也有很大不同。此外,视野略微扩大(约10%)和新的120Hz最大刷新率是新款硬件最好的改进。这些都是锦上添花的功能,但绝非革命性的变化。
内容生态:质量优于数量
当首款Vision Pro发布时,我对该平台的前景持乐观态度——但这在很大程度上依赖于强大的内容节奏和第三方开发者支持。
正如我后来所写的,第一年的内容节奏令人失望。我期望TV应用中每周都有苹果的沉浸式视频剧集,但这些短视频之间的间隔长达数月。苹果围墙花园之外有大量优质的沉浸式内容,但苹果似乎不感兴趣让Vision Pro所有者轻松访问这些内容。第三方应用做了一些这方面的工作,但它们落后于其他平台的应用。
然而,第一年的内容节奏有所加快。此外,苹果引入了空间画廊(Spatial Gallery),这是一个内置应用,聚合沉浸式3D照片等内容。它有点类似于TikTok,让您可以滚动利用设备独特优势的短格式内容,这正是平台在发布时迫切需要的东西。
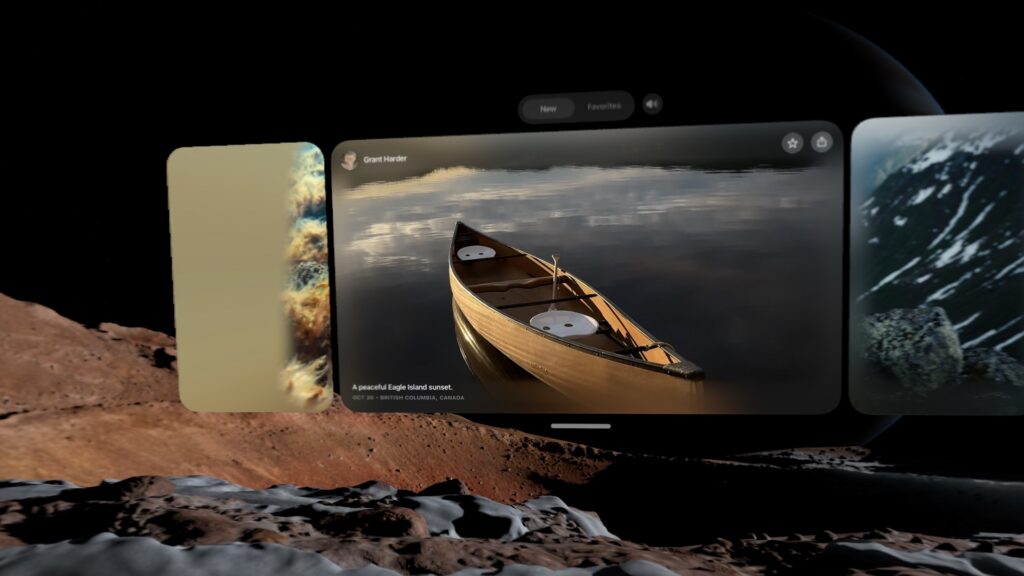
现有的内容——无论是在TV应用还是空间画廊中——都非常出色。它们制作精美,专业水准高,真正充分利用了硬件。例如,有一部以U2主唱波诺(Bono)为中心的自传体电影,在格式上做了一些我从未见过甚至想象过的创新尝试。
当然,波诺不是每个人的最爱,但如果你能忍受电影的夸夸其谈,仅从空间视频制作应该是什么样的角度来看,就值得一看。
我认为仍有很大的增长空间,但内容状况比以往任何时候都好。它不足以让您每天娱乐数小时,但足以让您每周戴上头显一段时间,这是一年前所没有的。
软件支持情况也类似。
应用支持:停滞在2024年
我们许多人都有一些基础性的日常生产力应用。对我来说,主要是macOS用户,它们是:
- Firefox
- Spark
- Todoist
- Obsidian
- Raycast
- Slack
- Visual Studio Code
- Claude
- 1Password
如您所见,我不使用大多数苹果内置应用——没有Safari,没有Mail,没有提醒,没有密码,没有笔记……甚至没有Spotlight。这可能不太典型,但这在macOS上从未成为问题,在iOS上过去几年也是如此。
令人印象深刻的是,几乎所有这些应用都可在visionOS上使用——但这仅仅因为它可以作为平面虚拟窗口运行iPad应用。Firefox、Spark、Todoist、Obsidian、Slack、1Password,甚至Raycast都可作为支持的iPad应用使用,但令人惊讶的是,Claude没有,尽管有Claude的iPad应用。(不过ChatGPT的iPad应用可以工作。)VS Code当然不可用,但我也没有期望它会可用。
没有一个应用程序是真正的visionOS应用。这很遗憾,因为我想象空间计算版本可以做一些很酷的事情。想象在增强现实中浏览您的Obsidian图谱!唉,我只能梦想。
如果您不像我这样的生产力软件极客,而是使用苹果的内置应用,情况看起来会好一些,但令人惊讶的是,仍然有一些您可能会认为具有非常酷的空间计算功能的应用——比如苹果地图——也没有。地图也只是iPad应用。
即使您抛开生产力,专注于娱乐,仍然有令人沮丧的缺口。近两年过去了,仍然没有Netflix或YouTube应用。有足够好的YouTube第三方选项,但您必须在浏览器中观看Netflix,这比原生应用质量低,并且在Vision Pro的大虚拟屏幕上看起来很糟糕。
明确地说,确实有一些有趣的空间应用体验正在陆续推出——其中大多数是游戏、教育应用或有趣的点子,值得花几分钟查看。
总而言之,自2024年2月以来,情况基本没有变化。发布时有一波应用涌入,包括一些令人印象深刻的(主要是教育应用),但其余的从"基本上是iPad应用,但有一两个一次性技术演示式的空间功能,您不会尝试超过一次"到"基本上是iPad应用,但感觉更原生"再到"简直就是iPad应用"不等。就来自流行跨平台应用的支持而言,今天的列表与那时基本相同。
杀手级应用:作为终极显示器
尽管苹果在开发者支持方面没有取得重大突破,但在使Vision Pro成为Mac的便捷伴侣方面取得了长足进步。
从一开始,它就有一个功能,让您只需看着Mac的内置显示屏,轻敲手指,即可启动一个大型可调整大小的虚拟显示器。我自己在家有大型多显示器设置,但有时旅行时我会以这种方式使用Vision Pro。
然而,一开始我有一些抱怨。它只能支持一个显示器,并且该显示器仅限于60Hz和标准宽屏分辨率。这比仅使用14英寸MacBook Pro屏幕要好,但与3500美元价格标签所暗示的高端设置相去甚远。此外,它不允许在两个设备之间切换音频。
由于软件和硬件更新,这一切都改变了。visionOS现在支持三种不同的显示器尺寸:标准宽屏宽高比、类似于标准超宽屏的更宽显示器,以及一个巨大的、超超宽的环绕显示器,我可以向您保证,它不会让任何人觉得桌面空间不够。它看起来很棒。问题解决了!同样,它现在会自动将Mac音频传输到Vision Pro或其蓝牙耳机。
所有这些不仅适用于新的Vision Pro,也适用于M2型号。新的M5型号专门解决了我的最后一个抱怨:您现在可以为该虚拟显示器实现高于60Hz的刷新率。苹果表示它"最高可达120Hz",但没有可用的工具来准确测量它实际达到了多少。尽管如此,我很高兴看到任何改进。
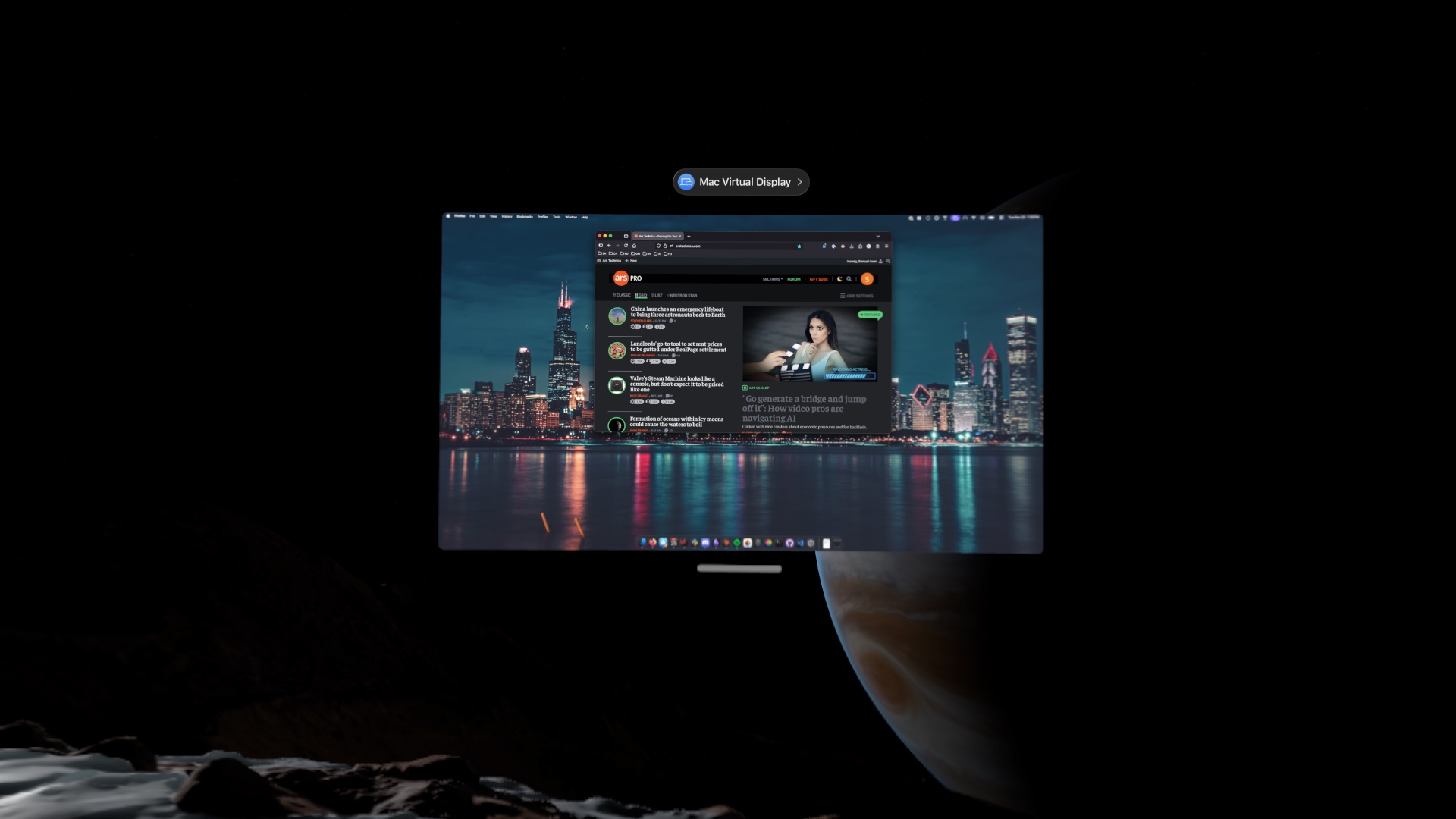
这是Mac显示器功能的标准宽度...
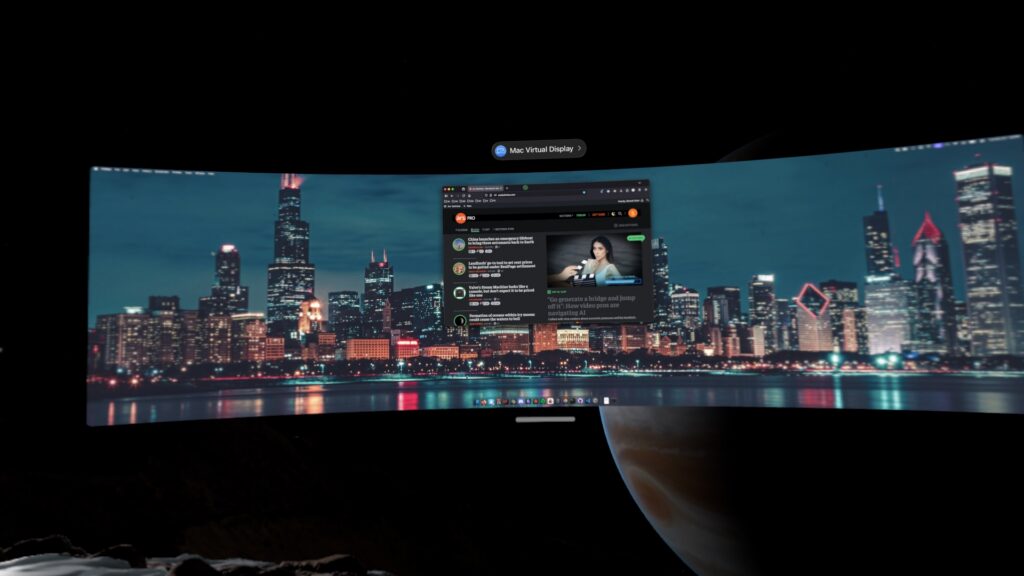
这种超宽、环绕式的显示器是Vision Pro少数几个杀手级应用之一。
通过一系列更新,苹果已经将一个巧妙的概念验证功能变成了真正有价值的东西——特别是对于那些喜欢超宽或多显示器设置但经常旅行(如我自己)或不想在家中投资显示硬件的人来说。
您也可以在这个显示器上玩Mac游戏。我尝试用控制器在上面玩《无人深空》和《赛博朋克2077》,体验非常棒。
这加上空间视频和观看电影,是Vision Pro当前的杀手级应用,也是苹果明显投入大量精力改进平台的主要领域之一。
停止强制推广Personas
奇怪的是,苹果投入大量精力改进的另一个领域是Vision Pro作为通信和会议设备的实用性。Personas——您为Zoom通话等创建的自己的3D头像——在M2 Vision Pro发布时绝对糟糕透顶。
还有"视线"(EyeSight),它使用您的Persona向周围现实世界的人们展示您眼睛的模拟形象,让他们知道您意识到周围的环境,甚至允许他们跟随您的视线。我理解这个功能背后的想法——苹果不希望混合现实具有社交隔离性——但它有时会把眼睛放在错误的位置,有点难以看清,老实说,这似乎是在浪费昂贵的硬件。
主要通过软件更新,我很高兴地报告,Personas已经大幅改进。我的现在看起来真的像我,而且动作也更自然了。
我参加了与苹果代表的FaceTime通话,他们向我展示了Personas如何相互浮动和表达情感,以及我们如何可以一起查看相同的文件和资产。不可否认,这很酷,比以前好多了,这要归功于改进的Personas。
对于"视线",我不能说同样的话,它看起来还是一样。我很难理解苹果在这款设备上放置了多个传感器和屏幕来支持此功能。
在我看来,放弃"视线"是苹果能为这款头显做的最好的事情。大多数人不喜欢它,大多数人也不想要它,但毫无疑问,它的加入不仅对价格和重量——产品采用的两大障碍——增加了不小的负担。
同样,Personas理论上很酷,参加FaceTime通话看看它是如何工作的以及你能做什么,是一种新颖有趣的经历。但仅此而已:一种新颖的经历。一旦您尝试过,您就永远不会觉得需要再次尝试。我几乎无法想象有人宁愿以Persona的形式出现在通话中,而不是摘下头显30分钟,在电脑上拨入。
这款头显的大部分都致力于它可以成为连接他人的设备,但保持这一优先级完全是一个错误的决定。混合现实具有隔离性,苹果正在将其视为需要解决的问题,但我认为这是其吸引力的一部分。
如果这款头显支持任何现实世界中的应用程序,我不会这么认为,但Vision Pro不支持任何需要将其带出家门进入公共场所的应用程序。我能想到的许多酷炫的理论性AR用途都会涉及这一点,但在这里仍然不行。
元宇宙(有趣的是,这是我至少一年来第一次输入这个词)已经存在:它在我们的手机上,在Instagram、TikTok、微信和《堡垒之夜》中。它不需要被发明,也不需要一种新的巧妙方法来使其最终起飞。它已经被发明了。它已经在轨道上了。
就像iPad和Apple Watch一样,Vision Pro需要停止尝试成为通用设备,而是需要专注于使其与众不同的特点。
通过这样做,它将提供更好的用户体验,并且会变得更轻、更便宜。那里有真正的潜力。不幸的是,如果泄露和内部报告可信,苹果可能不会走那条路。
前路漫漫,希望这不是死胡同
据普遍可靠的行业分析师郭明錤(Ming-Chi Kuo)称,M5 Vision Pro是产品线中计划推出的四款新机型中的第一款。接下来,他预测将推出全面重新设计的Vision Pro 2,以及一款更轻、更便宜的Vision Air。这些都将 precede 多年后真正的智能眼镜。
我喜欢那个计划:为那些想要最优质混合现实体验的人保留全功能Vision Pro(但可能放弃"视线"),并推出更便宜的版本,与Meta的Quest系列头显或Valve新发布的Steam Frame VR头显以及谷歌、三星等计划中的竞争对手更直接地竞争。
真正的增强现实眼镜是一个令人惊叹的梦想,但在它们能够真正取代蒂姆·库克(Tim Cook)曾经预测的智能手机之前,我们还有很长的路要走,需要解决光学和用户体验方面的严重问题。
话虽如此,看起来这个计划已被质疑。10月彭博社的一篇报道称,苹果CEO蒂姆·库克告诉员工,公司正在将资源从未来的透视HMD产品重新分配,以加速智能眼镜的工作。
让我们现实一点:它永远只会是一个偶尔使用的设备,而不是日常使用的设备。对于许多人来说,如果它售价1000美元,那会很好。在3500美元的价格下,它对大多数消费者来说仍然是一个难以接受的选择。
我相信这个产品在市场上有一席之地。我仍然认为它很了不起。它不会像iPhone那么大,甚至可能不会像iPad那么大,但它已经找到了一个小众受众,如果价格和重量能够下降,这个受众可能会显著增长。移除与Personas和"视线"相关的所有硬件将有助于实现这一目标。
我希望苹果继续开发它。当苹果发布Apple Watch时,它在用户生活中的定位并不完全明确。答案(健康和健身)随着时间的推移变得清晰,设备的其他雄心逐渐消退,而公司开始在效果最好的基础上构建。
您看到苹果通过扩展的Mac空间显示功能在这方面做了一些。这可能是一个引人入胜旅程的开始。但作家们有一个有点粗俗的短语:"杀死你的宝贝"。这意味着你需要清醒地看待你的作品,无情地删除任何不起作用的东西,即使你个人喜欢它——即使它是你一开始对这个项目感到兴奋的主要原因。
苹果现在确实应该开始为Vision Pro杀死一些宝贝,但我真心希望它不要走得太远,而完全消灭整个平台。








