
深入探索Qwen大模型及其LoRA微调实践
随着人工智能技术的飞速发展,大型语言模型(LLM)正日益成为推动自然语言处理领域进步的核心动力。其中,由阿里云开发的Qwen系列大模型,凭借其卓越的性能和广泛的应用前景,受到了业界的广泛关注。本文将深入剖析Qwen大模型的架构特点、训练流程,并结合LoRA微调实战案例,为读者提供一份详尽的技术解读。
Qwen大模型概览
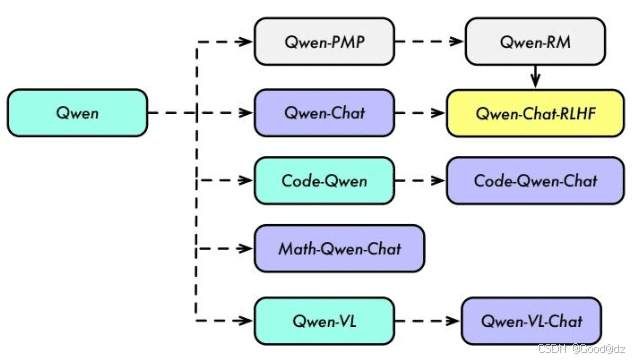
Qwen是由阿里云研发的一系列大型语言模型,它并非一个单一的模型,而是一个包含多种变体的家族,包括基础模型(Base Model)、奖励模型(RM Model)、对话模型(Chat Model)、代码模型(Code Model)和数学模型(Math Model)等,以满足不同应用场景的需求。
Qwen模型在训练过程中采用了ChatML格式,这是一种专门为对话场景设计的格式。ChatML的核心要素包括:
- 消息(Message): 对话交互的基本单元,由角色和内容组成。
- 角色(Role): 消息的发送方,可以是人(Human)或助手(Assistant)。
- 内容(Content): 消息的具体内容,以Markdown格式表示,方便信息的呈现和处理。
- 会话(Conversation): 由一系列消息构成的完整对话过程,模型通过理解和生成消息来完成对话。
ChatML格式使得模型能够有效地区分各类信息,从而增强了对复杂会话的处理和分析能力,提高了对话的质量和流畅性。

大语言模型的训练过程
大语言模型的训练过程通常包括四个主要阶段:预训练阶段、监督训练阶段(SFT)、奖励模型阶段(RM)和强化学习阶段(RL)。
1. 预训练阶段
预训练是LLM训练的基石。Qwen模型的预训练数据集规模庞大,达到了3TB,涵盖了公共网络文档、百科全书、书籍、代码等多种类型的数据。这些数据涉及多种语言,但以中文和英文为主。在预训练过程中,Qwen遵循自回归语言建模的标准方法,即通过前面Token的内容预测下一个Token。这一阶段的目标是让模型学习通用的语言知识,使其具备强大的语言编码能力。
2. SFT监督微调阶段
SFT(Supervised Fine-Tuning,监督微调)是在预训练模型的基础上,利用标注数据进行微调的过程。与预训练的无监督学习不同,SFT需要大量的标注数据,用于特定任务的训练。如果标注数据不足,可能会导致微调后的模型表现不佳。在SFT过程中,选择合适的预训练模型至关重要,因为预训练模型的参数和结构对微调后的模型性能有很大的影响。
LoRA(Low-Rank Adaptation)是一种常用的微调方法,它通过引入低秩矩阵来更新模型参数,从而降低了计算成本和存储需求。在本文的实战演练部分,我们将以LoRA微调方法为例,演示如何对Qwen模型进行微调。
3. RM奖励模型阶段
在完成SFT监督微调后,下一步是构建一个奖励模型(RM)来对模型的输出进行评分。奖励模型源于强化学习中的奖励函数,它能够对当前的状态(即模型的输出)给出一个分数,用于衡量该状态的价值。在LLM微调中,奖励模型的作用是根据输入的问题和答案计算出一个分数,答案与问题匹配度越高,奖励模型输出的分数也越高。
具体来说,RM模型是将SFT模型的最后一层softmax层去掉,替换为一个线性层。RM模型的输入是问题和答案,输出是一个标量,即分数。RM模型的训练数据是人工对问题的每个答案进行排序的结果。
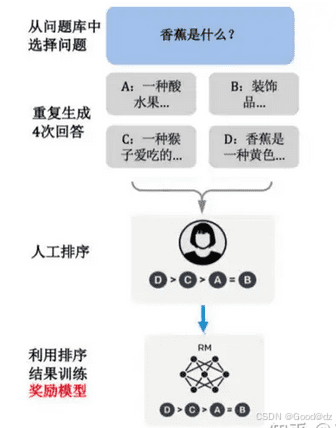
对于每个问题,给出若干个答案,然后由人工进行排序。奖励模型的目标是使得排序高的答案对应的标量分数要高于排序低的答案对应的标量分数,且越高越好。为此,奖励模型通常采用Pairwise Ranking Loss作为损失函数。
总而言之,奖励模型通过与人类进行交互,获得对生成响应质量的反馈信息,从而进一步提升大模型的生成能力和自然度。与监督模型不同的是,奖励模型通过打分的形式使得生成的文本更加自然逼真,让大模型的生成能力更进一步。
4. RL强化学习阶段
在完成奖励模型的训练后,最后一个阶段是训练强化学习模型(RL模型)。在LLM微调中,训练RL模型采用的优化算法是PPO(Proximal Policy Optimization,近端策略优化)算法,即对设定的目标函数通过随机梯度下降进行优化。PPO是一种深度强化学习算法,用于训练智能体在复杂环境中学习和执行任务。通过智能体的训练,使得其在与环境的交互中能够最大化累积汇报,从而达成指定任务目标。这里的智能体在大模型中指的就是RL模型。
通过强化学习的训练方法,迭代式地更新奖励模型(RW 模型)以及策略模型(RL 模型),让奖励模型对模型输出质量的刻画愈加精确,策略模型的输出则愈能与初始模型拉开差距,使得输出文本变得越来越符合人的认知。这种训练方法也叫做 RLHF(Reinforcement Learning from Human Feedback,从人类反馈中进行强化学习)。
基于LoRA的Qwen微调实战
接下来,我们将通过一个基于LoRA的Qwen微调实战案例,演示如何将Qwen模型应用于文本分类任务。
1. 环境配置
本案例基于以下环境进行测试:
- modelscope==1.14.0
- transformers==4.41.2
- datasets==2.18.0
- peft==0.11.1
- accelerate==0.30.1
- swanlab==0.3.11
可以使用以下命令配置环境:
conda create --name Qwen2 python=3.8
conda activate Qwen2
pip install swanlab modelscope==1.14.0 transformers==4.41.2 datasets==2.18.0 peft==0.11.1 pandas accelerate==0.30.12. 数据集下载
本案例使用zh_cls_fudan-news数据集,该数据集主要被用于训练文本分类模型。
zh_cls_fudan-news由几千条数据组成,每条数据包含text、category、output三列:
text是训练语料,内容是书籍或新闻的文本内容。category是text的多个备选类型组成的列表。output则是text唯一真实的类型。

数据集的下载地址为:zh_cls_fudan-news。可以使用以下代码下载数据集:
from modelscope import MsDataset
dataset = MsDataset.load('huangjintao/zh_cls_fudan-news', split='train')
test_dataset = MsDataset.load('huangjintao/zh_cls_fudan-news', subset_name='test', split='test')
print(dataset)
print(test_dataset)3. 完整训练代码
以下是完整的训练代码,包括数据集处理、模型加载、LoRA配置、训练参数设置和训练过程:
import json
import pandas as pd
import torch
from datasets import Dataset
from modelscope import snapshot_download, AutoTokenizer
from swanlab.integration.huggingface import SwanLabCallback
from peft import LoraConfig, TaskType, get_peft_model
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForSeq2Seq
import os
import swanlab
def dataset_jsonl_transfer(origin_path, new_path):
"""
将原始数据集转换为大模型微调所需数据格式的新数据集
"""
messages = []
# 读取旧的JSONL文件
with open(origin_path, "r") as file:
for line in file:
# 解析每一行的json数据
data = json.loads(line)
context = data["text"]
catagory = data["category"]
label = data["output"]
message = {
# "instruction": 用于告诉模型它将扮演的角色
# "input": 用户输入的文本
# "output": 模型输出的文本标签
"instruction": "你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型",
"input": f"文本:{context},类型选型:{catagory}",
"output": label,
}
messages.append(message)
# 保存重构后的JSONL文件
with open(new_path, "w", encoding="utf-8") as file:
for message in messages:
file.write(json.dumps(message, ensure_ascii=False) + "\n")
def process_func(example):
"""
将数据集进行预处理
"""
# 设置最大序列长度:MAX_LENGTH = 384 限制了模型输入序列的最大长度
MAX_LENGTH = 384
# 初始化ID列表:初始化三个列表input_ids, attention_mask, labels,分别用于存放模型所需的输入Token ID、注意力掩码以及标签(输出Token ID)。
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(
f"<|im_start|>system\n你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型<|im_end|>\n<|im_start|>user\n{example['input']}<|im_end|>\n<|im_start|>assistant\n",
add_special_tokens=False,
)
response = tokenizer(f"{example['output']}", add_special_tokens=False)
# input_ids: 将分词后的指令(instruction)和响应(response)的input_ids合并,并在末尾添加一个填充标记,以此构造完整的输入序列
# attention_mask: 用来指示哪些tokens应当被模型关注(值为1的部分),哪些应当被忽略(值为0的部分)
# 在自然语言处理领域,文本数据需要被转换成模型可以理解的数字形式---也就是数字序列。这些数字是词汇表中的索引。
# 当一个文本处理器(如tokenizer)处理一段文本时,它会将文中的单词、字符或子词映射到一个唯一的数字ID,这个过程为"令牌化"。
# 词汇表是模型训练之初,基于训练数据建立的,每个不同的词,标点符号、特殊字符等都有一个对应的ID。
# input_ids数组或列表中的每一个数字代表原文本中的一个token(可能是词、子词或其他单位)在词汇表中的位置。这样做不仅使得文本可以被编码为神经网络可以运算的形式,还方便了模型理解和生成文本。
# 至于attention_mask,它的作用在于帮助模型区分有效输入(即实际的文本内容)与填充内容(pad tokens)。模型在计算自注意力或交互时,会利用attention_mask来确定哪些部分需要关注(通常值为1),哪些部分(比如为了对齐长度而填充的tokens)应该被忽略(通常值为0)。
input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]
attention_mask = (
instruction["attention_mask"] + response["attention_mask"] + [1]
)
# 对于labels,则用-100标记源序列的token(因为这些不是预测的目标,而是已知的输入),然后跟上响应序列的真实token ID,最后也是填充标记。
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]
print(len(instruction["input_ids"]))
# exit()
#如果构建好的input_ids长度超过MAX_LENGTH,则会进行截断操作。
if len(input_ids) > MAX_LENGTH: # 做一个截断
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
def predict(messages, model, tokenizer):
device = "cuda"
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
return response
model_dir = snapshot_download("qwen/Qwen2-1.5B-Instruct", cache_dir="./", revision="master")
tokenizer = AutoTokenizer.from_pretrained("./qwen/Qwen2-1___5B-Instruct/", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./qwen/Qwen2-1___5B-Instruct/", device_map="auto", torch_dtype=torch.bfloat16)
model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法
train_dataset_path = "zh_cls_fudan-news/train.jsonl"
test_dataset_path = "zh_cls_fudan-news/test.jsonl"
train_jsonl_new_path = "new_train.jsonl"
test_jsonl_new_path = "new_test.jsonl"
if not os.path.exists(train_jsonl_new_path):
dataset_jsonl_transfer(train_dataset_path, train_jsonl_new_path)
if not os.path.exists(test_jsonl_new_path):
dataset_jsonl_transfer(test_dataset_path, test_jsonl_new_path)
train_df = pd.read_json(train_jsonl_new_path, lines=True)
train_ds = Dataset.from_pandas(train_df)
train_dataset = train_ds.map(process_func, remove_columns=train_ds.column_names)
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 训练模式
r=8, # Lora 秩
lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理
lora_dropout=0.1, # Dropout 比例
)
model = get_peft_model(model, config)
args = TrainingArguments(
output_dir="./output/Qwen2_0.5",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
logging_steps=10,
num_train_epochs=20,
save_steps=100,
learning_rate=1e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to="none",
)
swanlab_callback = SwanLabCallback(
project="Qwen2-fintune",
experiment_name="Qwen2-0.5B-Instruct",
description="使用通义千问Qwen2-0.5B-Instruct模型在zh_cls_fudan-news数据集上微调。",
config={
"model": "qwen/Qwen2-0.5B-Instruct",
"dataset": "huangjintao/zh_cls_fudan-news",
}
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback],
)
trainer.train()
test_df = pd.read_json(test_jsonl_new_path, lines=True)[:10]
test_text_list = []
for index, row in test_df.iterrows():
instruction = row['instruction']
input_value = row['input']
messages = [
{"role": "system", "content": f"{instruction}"},
{"role": "user", "content": f"{input_value}"}
]
response = predict(messages, model, tokenizer)
messages.append({"role": "assistant", "content": f"{response}"})
result_text = f"{messages[0]}\n\n{messages[1]}\n\n{messages[2]}"
test_text_list.append(swanlab.Text(result_text, caption=response))
swanlab.log({"Prediction": test_text_list})
swanlab.finish()如果在运行上述代码时出现“段错误”,可以尝试重新运行。此外,如果首次使用SwanLab,需要在swanlab.cn上注册账号,并复制API Key,然后在训练开始时粘贴进去。
4. 推理代码
以下是使用微调后的LoRA模型进行推理的代码:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
def predict(messages, model, tokenizer):
device = "cuda"
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
tokenizer = AutoTokenizer.from_pretrained("./qwen/Qwen2-1___5B-Instruct/", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("./qwen/Qwen2-1___5B-Instruct/", device_map="auto", torch_dtype=torch.bfloat16)
model = PeftModel.from_pretrained(model, model_id="./output/Qwen2/checkpointXXX")
test_texts = {
'instruction': "你是一个文本分类领域的专家,你会接收到一段文本和几个潜在的分类选项,请输出文本内容的正确类型",
'input': "文本:航空动力学报JOURNAL OF AEROSPACE POWER1998年 第4期 No.4 1998科技期刊管路系统敷设的并行工程模型研究*陈志英* * 马 枚北京航空航天大学【摘要】 提出了一种应用于并行工程模型转换研究的标号法,该法是将现行串行设计过程(As-is)转换为并行设计过程(To-be)。本文应用该法将发动机外部管路系统敷设过程模型进行了串并行转换,应用并行工程过程重构的手段,得到了管路敷设并行过程模型。"
}
instruction = test_texts['instruction']
input_value = test_texts['input']
messages = [
{"role": "system", "content": f"{instruction}"},
{"role": "user", "content": f"{input_value}"}
]
response = predict(messages, model, tokenizer)
print(response)总结
本文深入剖析了Qwen大模型的架构特点、训练流程,并结合LoRA微调实战案例,为读者提供了一份详尽的技术解读。通过本文的学习,读者可以更好地理解Qwen大模型的工作原理,并掌握LoRA微调的实践方法,从而更好地将Qwen模型应用于实际场景中。在AI技术日新月异的今天,掌握这些核心技术将有助于我们在人工智能领域取得更大的突破。
参考链接:










