
在人工智能语音技术领域,一股开源的风潮正在涌动。Fish Audio 近日宣布开源其最新的文本转语音(TTS)模型——OpenAudio S1-Mini,引起了业界的广泛关注。这款模型以其精简的参数、卓越的性能以及对多语言的支持,成为了AI语音技术领域的一颗新星。
OpenAudio S1-Mini 的核心优势在于其轻量化设计与高性能的完美结合。它从拥有4B参数的S1模型中提炼而来,仅包含0.5B参数,这使得它在计算资源受限的环境中也能流畅运行。这种轻量化的设计,无疑为边缘设备和本地化应用提供了极大的便利。然而,参数的减少并未牺牲其性能。S1-Mini 依然基于超过200万小时的庞大音频数据集进行训练,这为它赋予了强大的语音合成能力。
更令人 впечатляющий的是,S1-Mini 支持14种语言,包括中文、英文、日语、法语等,并能够生成超过50种情感和语调的语音表达。无论是表达愤怒、开心、惊讶,还是模拟笑声、哭声等特殊音效,S1-Mini 都能以接近真人的自然发音呈现,展现出其卓越的表现力。这种强大的情感表达能力,使得它在语音合成领域具有了独特的优势。
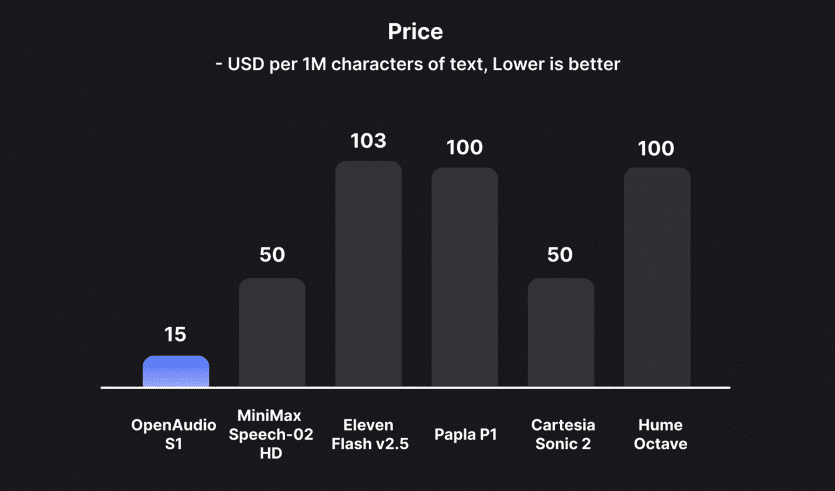
开源是 OpenAudio S1-Mini 的另一大亮点。OpenAudio 通过开源 S1-Mini,积极推动 AI 语音技术的民主化。该模型已在 Hugging Face 平台上架,开发者可以免费下载并在非商业场景下使用。相较于那些需要支付高昂订阅费用的闭源 TTS 模型,S1-Mini 的开源特性无疑大大降低了开发门槛,为小型团队和独立开发者提供了高质量语音合成的可能性。此外,OpenAudio 还提供在线体验平台,让用户能够直观地体验模型的效果。这种开放的策略不仅促进了技术的迭代,也增强了社区的信任,为语音 AI 的广泛应用奠定了坚实的基础。
OpenAudio S1-Mini 的性能也备受瞩目。根据第三方基准测试,OpenAudio S1 在性能上已经超越了 ElevenLabs、OpenAI 等竞争对手的部分模型。而 S1-Mini 作为其精简版,依然在自然度和情感表达上表现出色。这主要得益于 RLHF(强化学习与人类反馈)优化技术,该技术使得 S1-Mini 在生成连贯、富有情感的语音时展现出惊人的效果,尤其在多语言场景和复杂对话中的表现令人瞩目。尽管目前 S1-Mini 不可用于商业用途,但其开源性质为学术研究和个人项目提供了巨大的价值。
S1-Mini 的应用前景十分广阔。其轻量化设计使其能够适应多种场景,包括教育领域的语言学习工具、娱乐行业的音频书和播客生成,以及交互式应用的语音合成。此外,S1-Mini 支持的特殊音效(如笑声、喊叫)为内容创作者提供了更多的创意空间。其多语言支持使其在全球市场具有竞争优势,尤其在非英语语言的语音生成领域展现出巨大的潜力。可以预见,S1-Mini 的发布将进一步推动开源 TTS 技术在全球的普及与创新。
Fish Audio 计划持续优化 S1-Mini 的性能,并可能推出支持更多语言和实时应用的版本。随着开源社区的参与,S1-Mini 有望加速语音技术的迭代,挑战现有商业模型的垄断地位,为行业带来更多的可能性。
OpenAudio S1-Mini:技术细节深度剖析
为了更深入地了解 OpenAudio S1-Mini 的技术细节,我们需要对其内部结构和训练方法进行详细的分析。S1-Mini 的核心架构基于 Transformer 模型,这是一种在自然语言处理领域广泛应用的深度学习模型。Transformer 模型以其强大的序列建模能力和并行计算能力而著称,能够有效地捕捉语音信号中的复杂关系。
在 S1-Mini 中,Transformer 模型被用于将输入的文本序列转换为相应的语音特征序列。这个过程可以分为以下几个步骤:
- 文本编码:首先,输入的文本被转换为一系列的词嵌入向量。词嵌入是一种将词语映射到高维向量空间的技术,它能够捕捉词语之间的语义关系。S1-Mini 使用预训练的词嵌入模型,例如 Word2Vec 或 GloVe,来初始化词嵌入向量。这些预训练模型已经在大量的文本数据上进行了训练,能够提供高质量的词嵌入表示。
- Transformer 编码器:接下来,词嵌入向量被输入到 Transformer 编码器中。编码器由多个 Transformer 层堆叠而成,每一层都包含自注意力机制和前馈神经网络。自注意力机制能够让模型关注输入序列中不同位置之间的关系,从而更好地理解文本的含义。前馈神经网络则用于对自注意力机制的输出进行非线性变换。
- 语音特征预测:编码器的输出被输入到一个语音特征预测模块中。该模块负责将文本表示转换为语音特征,例如梅尔频谱或线性谱。S1-Mini 使用一个多层感知器(MLP)来实现语音特征预测。MLP 接收编码器的输出,并将其映射到相应的语音特征向量。
- 声码器:最后,语音特征向量被输入到一个声码器中。声码器负责将语音特征转换为可听的音频信号。S1-Mini 支持多种声码器,例如 WaveNet、MelGAN 和 Parallel WaveGAN。这些声码器都能够生成高质量的音频信号,但它们在计算复杂度和音质方面有所不同。
除了模型架构之外,训练数据也是影响 TTS 模型性能的关键因素。S1-Mini 基于超过200万小时的庞大音频数据集进行训练,这个数据集包含了各种语言、口音、情感和语调的语音样本。为了提高模型的泛化能力,OpenAudio 还使用了数据增强技术,例如添加噪声、改变语速和音调等。此外,OpenAudio 还采用了 RLHF(强化学习与人类反馈)优化技术,该技术能够让模型更好地学习人类的偏好,从而生成更自然、更符合人类期望的语音。
开源 TTS 模型的未来趋势
OpenAudio S1-Mini 的开源发布,标志着开源 TTS 模型进入了一个新的发展阶段。随着计算能力的不断提高和数据集的不断扩大,开源 TTS 模型的性能将会越来越接近甚至超过商业模型。未来,我们可以预见到以下几个趋势:
- 模型轻量化:随着边缘计算的兴起,轻量化 TTS 模型的需求将会越来越大。未来的开源 TTS 模型将会更加注重模型压缩和优化,以便在资源受限的设备上运行。
- 多语言支持:全球化的趋势使得多语言 TTS 模型变得越来越重要。未来的开源 TTS 模型将会支持更多的语言,并能够生成具有不同口音和语调的语音。
- 情感表达:情感表达是 TTS 模型的重要指标。未来的开源 TTS 模型将会更加注重情感建模,以便生成更富有情感的语音。
- 个性化定制:个性化定制是 TTS 模型的重要发展方向。未来的开源 TTS 模型将会提供更多的定制选项,以便用户可以根据自己的需求生成个性化的语音。
- 实时应用:实时 TTS 模型在语音助手、在线教育等领域具有广泛的应用前景。未来的开源 TTS 模型将会更加注重实时性能,以便满足实时应用的需求。
总而言之,OpenAudio S1-Mini 的发布是 AI 语音技术领域的一个重要里程碑。它不仅为开发者提供了高效的工具,也为开源生态注入了新的活力。随着开源社区的不断发展,我们有理由相信,开源 TTS 模型将会在未来发挥越来越重要的作用,为人们的生活带来更多的便利和乐趣。
AIbase 将持续关注 OpenAudio 及 TTS 技术的最新动态,为您带来前沿报道。








