
AI视频生成迈向新纪元:昆仑万维SkyReels-A3如何定义下一代内容生产力
近年来,人工智能技术在视频内容创作领域展现出前所未有的潜力,从早期的换脸应用到如今的数字人播报,其发展速度令人惊叹。然而,在激动人心的表象之下,现有AI视频生成技术在迈向广泛商业化与专业化应用的道路上,仍面临着诸多挑战。诸如数字人与真实物体交互的僵硬、长时间视频内容生成时画面一致性的难以维系,以及镜头语言的匮乏,都使得AI视频在真实感与表现力方面与人类创作尚存显著差距。即便是一些热门的二创内容,例如利用经典影视IP如《甄嬛传》进行创意广告植入,也常因上述技术瓶颈而难以实现超过数秒的逼真效果。一旦时长延长,人物动作的僵硬、手部扭曲、画面质量的下降,乃至“崩坏”现象便会暴露无遗,这严重制约了AI视频从“猎奇亮点”向“生产力工具”的转变。
正是为了精准解决这些痛点,中国AI领域的重要参与者昆仑万维,于近期正式发布了其在AI视频生成领域的重磅新作——SkyReels-A3模型。该模型作为昆仑万维“Skywork AI技术发布周”的首日亮点,旨在通过一系列创新技术,彻底革新数字人视频的生成逻辑与应用边界。SkyReels-A3的问世,预示着AI视频内容创作正从单薄的静态展示,迈向充满动态与互动的新篇章。
突破互动僵局:数字人与真实世界的自然融合
长期以来,让数字人自然地与物理世界中的物体进行交互,一直是AI视频生成领域的难点。传统模型往往只能生成僵硬、不自然的动作,尤其在手部精细动作和物体抓取方面表现欠佳。这在直播带货、产品演示等对真实感要求极高的场景中,无疑是致命缺陷。想象一下,一个虚拟主播在介绍商品时,无法流畅地拿起、展示产品,其带货效果将大打折扣。
SkyReels-A3模型在这方面取得了显著突破。它基于先进的DiT(Diffusion Transformer)视频扩散模型架构,并通过专门的数据构建和优化算法,实现了数字人与物体的自然交互能力。例如,在昆仑万维展示的桌游带货演示中,虚拟主播能够以高度真实的动作拿起桌游盒子并进行展示,盒子本身的前后一致性也得到了良好保持。这背后,是SkyReels-A3针对广告主播等业务场景进行了深入的手和商品交互优化。模型通过构建大量针对线上直播场景的真实数据,并采用偏好学习(reward model)来精选最佳生成结果,从而持续提升手部动作的自然度和清晰度。这种精细化的训练策略,使得SkyReels-A3生成的数字人不再是简单的“读稿机”,而是能够进行富有表现力的身体语言和手势互动,极大增强了视频的沉浸感与说服力。再比如,在MV场景中,数字人歌星能够自然地握持话筒,这一细节的完善,让虚拟形象的真实感瞬间跃升,摆脱了以往数字人“只有嘴巴在动”的机械感。



解锁长时稳定与镜头叙事:AI视频的“导演”视角
除了精细的互动,数字人视频要真正摆脱“玩具感”,迈向“生产力工具”的行列,还必须攻克两大核心难题:一是如何让视频在拉长时长的同时,依然保持画面与人物的稳定性和一致性;二是如何打破固定机位的呆板视角,引入专业的镜头语言,提升视频的艺术性和观赏性。过往的AI视频生成,往往受限于误差累积效应,随着时间推移,画面容易出现视觉伪影甚至“崩坏”,导致无法生成长时间的高质量内容。
SkyReels-A3在长视频生成方面引入了创新的“智能插帧”方法,有效解决了这一痛点。与简单地根据前一帧预测下一帧不同,该模型能够预先“锚定”未来的清晰关键帧,并在此基础上高质量地补全中间的视频片段。这种机制显著提升了视频的全局一致性,确保即使是长达一分钟的视频,人物的面部表情和画面细节也能保持高度的稳定性。从技术角度看,这种架构甚至具备支持无限长视频生成的潜力,虽然在实际产品应用中可能会受限于音频文件大小等因素,但分钟级别的单镜头视频生成已是轻而易举,这为数字人在更复杂的叙事场景中应用铺平了道路。
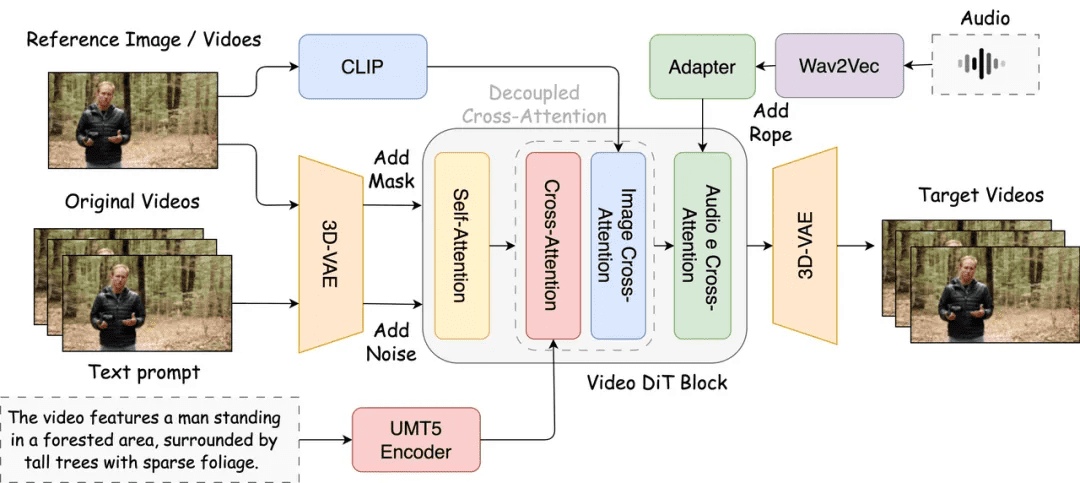
此外,SkyReels-A3还内置了一个基于ControlNet的镜头控制模块,赋予了创作者前所未有的“导演”权力。传统数字人视频多为“大头贴”式的固定机位,视觉上缺乏变化,容易让观众感到乏味。而SkyReels-A3预设了推镜(push in)、拉镜(push out)、左摇(pan left)、右摇(pan right)等8种常见的专业运镜方式,并且每种运镜的强度都可以从0到100进行连续调节。这意味着用户不再需要依赖后期剪辑,就能直接生成具有丰富镜头语言的视频内容。无论是模拟Vlog的手持镜头效果,还是实现直播带货中更为自然的横向运镜,SkyReels-A3都能轻松实现,极大地拓展了AI视频的应用场景和表现力。


尽管当前数字人技术在完全模拟人类真实行为方面仍有进步空间,但SkyReels-A3在长时稳定性和镜头控制上的突破,已经展现出令人信服的未来潜力。一个稳定、可控且具备丰富镜头感的长视频数字人,足以叩开直播、MV、在线教育、虚拟客服等多个领域的应用大门,预示着AI视频内容生产力的全面提升。
衡量前沿:SkyReels-A3的技术基准与行业地位
昆仑万维此次同步公布了SkyReels-A3的技术指标,为业界提供了其性能的量化依据。在基准测试平台A-Bench上,SkyReels-A3在多个关键维度上均达到了行业先进水平。具体而言:
- Sync-C和Sync-D:这两个指标用于精确测量生成视频中唇部动作与音频的同步程度。SkyReels-A3在Sync-C指标上表现优异,意味着其数字人唇形与语音的匹配度极高,显著提升了口播类视频的真实感与流畅性。
- IQA和ASE:通过专门训练的多模态大型语言模型(MLLM)评估视频画面的质量和艺术性。SkyReels-A3在这两项指标上的表现,表明其生成的视频不仅清晰稳定,而且具备较高的视觉美感。
- ID Similarity:通过计算生成视频和参考图/视频的人脸余弦相似度,衡量数字人身份的一致性。SkyReels-A3的高相似度,保证了数字人形象在长时间视频中的稳定性和可识别性,避免了“换脸”或形象不一的问题。
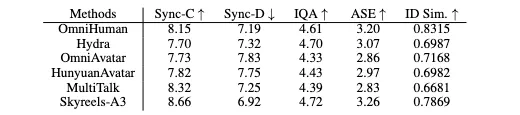
这些量化指标的优秀表现,印证了SkyReels-A3在核心技术上的扎实积累与领先优势,使其在日常对话、唱歌和口播等不同场景下,都能提供高质量的生成结果。这不仅是对其技术实力的最佳佐证,也为行业树立了新的性能标杆。
昆仑万维的AI全栈布局:从开源创新到产品落地
SkyReels-A3的发布,并非昆仑万维的孤立行动,它深刻嵌入了公司宏大的AI战略版图之中。昆仑万维长期以来坚持“开源贡献”与“产品落地”双线并进的策略,这使其在AI领域扮演着“基础设施建设者”与“顶尖产品经理”的双重角色。
作为“基础设施建设者”,昆仑万维通过持续开源一系列在行业内取得SOTA(State-of-the-Art)成就的大模型,为整个AI生态系统贡献着底层技术力量。例如,2025年2月,其开源的中国首个面向AI短剧创作的视频生成模型SkyReels-V1在Hugging Face排行榜上长期位居前列;同年4月,又发布了全球首个使用扩散强迫框架的无限时长电影生成模型SkyReels-V2,不断拓展技术边界。此外,在多模态领域,昆仑万维推出了将文本推理能力迁移至视觉的思维链推理模型“Skywork-R1V”系列,以及集图片生成、理解和编辑于一体的轻量化模型“Skywork UniPic”,以1.5B的参数规模逼近同类大参数模型。针对专业领域的挑战,他们还发布了数学代码推理模型“Skywork-OR1”、业界最强的仓库级代码修复模型“Skywork-SWE”,以及工业界首个开源的10B+空间智能大模型“Matrix-Game”。这些开源成果不仅彰显了昆仑万维深厚的技术硬实力,也为全球开发者提供了丰富的创新工具。
与此同时,作为“顶尖产品经理”,昆仑万维毫不掩饰其将最前沿技术迅速转化为实际生产力的商业雄心。集成了视频大模型与3D大模型的AI短剧平台SkyReels,正是搭载了包括SkyReels-A3在内的最新模型,旨在让创作者能够“一键成剧”,轻松制作高质量AI视频。这种从基础研究到应用产品一体化的全栈能力,使得昆仑万维能够快速响应市场需求,提供真正解决用户痛点的创新解决方案。
SkyReels-A3的亮相,仅仅是昆仑万维此次为期五天技术发布周的序章。它所展现的在数字人交互、长视频稳定性和镜头控制上的突破,为AI视频生成领域提供了极具说服力的解法。可以预见,随着昆仑万维未来更多底层技术与应用产品的推出,AI将不再是遥远的未来概念,而是实实在在地融入到媒体、娱乐、电商等各个行业,重塑内容创作与传播的范式。对于整个行业和所有关注人工智能发展的人而言,昆仑万维无疑正在牌桌上亮出更多底牌,这场由AI驱动的“好戏”,才刚刚拉开帷幕。


