
大型语言模型“链式思考”能力的深层剖析:是真智能还是“流利幻象”?
近年来,大型语言模型(LLM)在解决复杂问题方面的进步令人瞩目,特别是其通过“链式思考”(Chain-of-Thought, CoT)能力,能够将问题分解为多个逻辑步骤,从而生成更连贯、更看似合理的答案。这使得人们对AI的“推理”能力抱有前所未有的期待。然而,近期一系列深入研究却开始对这种“模拟推理”的本质提出质疑,指出其表现可能并非真正意义上的逻辑理解,而更像是一种“脆弱的海市蜃楼”。
来自亚利桑那州立大学的研究人员在一项预印本论文中,将LLMs的现有能力归结为“并非原则性的推理者,而是推理式文本的复杂模拟器”。为了更客观、可量化地评估CoT模型在面对“域外”(out-of-domain)逻辑问题时的泛化能力,研究团队构建了一个名为DataAlchemy的受控LLM训练环境,旨在精确测量模型在偏离训练数据特定逻辑模式时的表现。这项工作揭示了LLM推理能力的一个关键缺陷:它们在处理训练数据范围之外的复杂逻辑组合时,其性能会显著“退化”,甚至“灾难性地失败”。
突破训练边界:DataAlchemy实验的启示
DataAlchemy环境的搭建旨在创建一个高度受控的实验平台,用于测试LLM对基础文本转换的理解和泛化能力。研究人员首先训练了一些小型模型,使其掌握两种极其简单的文本转换规则:ROT密码(一种替换式密码)和循环移位(文本元素的顺序调整)。随后,模型会接受额外的训练,学习这两种功能以不同顺序和组合方式执行的示例。例如,模型可能在训练中见过“先ROT,再循环移位”或“先循环移位,再ROT”的组合。

实验的关键在于测试这些简化模型在面对“域外”逻辑问题时的表现。这包括两种主要情况:
- 新颖的函数组合:例如,一个模型可能只在训练数据中见过两次循环移位,但被要求执行涉及两次ROT移位的全新转换组合。尽管模型对单一的ROT移位有基本概念,但其组合方式是全新的。
- 格式、长度与微小差异:测试用例还包括了与训练数据在任务类型、格式或长度上存在细微差异的问题。例如,输入字符串比训练数据略长或略短,或者要求执行的函数链长度不同。
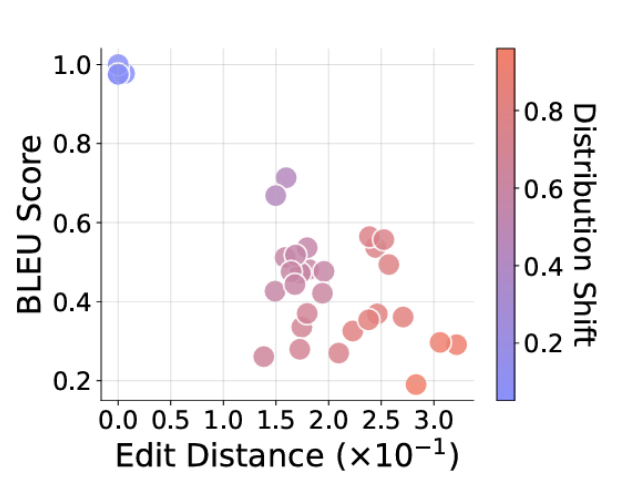
通过对模型最终答案和推理步骤进行BLEU分数和Levenshtein距离的客观评估,研究人员得以量化模型的准确性。这些指标能够精确衡量生成文本与预期答案之间的相似度和编辑距离,从而为模型性能提供量化依据。
“流利但无意义”:泛化能力的脆弱性
实验结果与研究人员的假设高度吻合:当这些基础模型被要求泛化训练数据中未直接展示的新颖转换组合时,其性能会呈现出“灾难性”的下降。模型虽然通常会尝试根据训练数据中相似的模式来泛化新的逻辑规则,但这却常常导致“正确的推理路径,但错误的答案”。这种现象令人深思:模型能够模仿逻辑步骤,但其对结果的实际把握却严重不足。在另一些案例中,LLM甚至可能偶然得出正确答案,但其背后的“推理路径”却是“不忠实于逻辑”的,即推理过程本身是错误的,这进一步凸显了其理解层面的缺失。
研究人员明确指出:“CoT推理在任务转换下,似乎反映的是训练期间所学模式的复制,而非对文本的真正理解。” 这意味着CoT更多是一种高级的模式匹配机制,而非具备深层次抽象逻辑推断能力的智能实体。
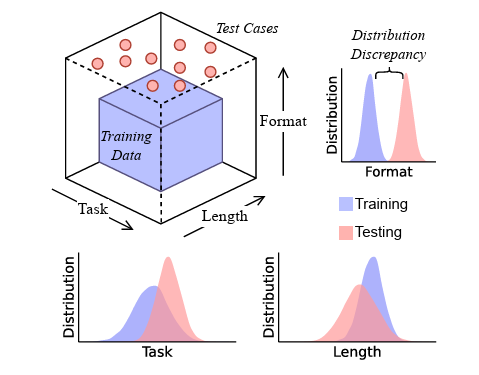
此外,当研究人员使用略短或略长的输入文本字符串,或要求执行与训练长度不同的函数链时,结果的准确性也“随着(长度)差异的增加而恶化”,这“表明模型泛化能力的失败”。即使是测试任务格式中细微的、模型不熟悉的差异(例如,引入训练数据中没有的字母或符号),也会导致模型性能“急剧下降”,并“影响”其响应的正确性。这些发现共同指向一个核心问题:LLM的“智能”高度依赖于其训练数据的分布,一旦超出这个边界,其表现便会变得极其脆弱。
局限与前景:超越表层模式识别
尽管监督式微调(SFT)常被视为解决“域外”模型性能下降的有效手段,通过引入少量相关数据便能带来显著改进,但研究人员警告称,这种“修补”方法不应被误认为是实现了真正的泛化能力。“依靠SFT来修复每一次‘域外’故障是一种不可持续的、被动的策略,未能解决核心问题:模型缺乏抽象推理能力。”这相当于头痛医头脚痛医脚,无法从根本上提升模型的通用逻辑推理水平。
该研究强调,这些CoT模型并非具备通用逻辑推断能力,而是一种“结构化模式匹配的复杂形式”。它们在被稍微推离训练分布时,性能就会“显著下降”。更令人担忧的是,这些模型生成“流利但无意义”内容的能力,会制造出一种“虚假的可靠性光环”,在缺乏严谨审查时极具迷惑性。这对于AI应用,尤其是那些对准确性、可靠性和安全性有极高要求的领域,构成了潜在的风险。例如,在医疗诊断、金融分析或法律判决等“高风险领域”,将CoT风格的输出等同于人类思维,可能会导致严重后果。
展望未来,业界亟需重新评估现有的测试和基准,将重点放在测试模型对训练集之外任务的泛化能力,以深入探究此类错误。同时,未来的模型开发必须超越“表层模式识别”,致力于展现“更深层次的推断能力”。这可能意味着需要探索全新的模型架构、训练范式,甚至是对人工智能“理解”本质的重新定义。只有这样,我们才能确保AI系统不仅能够流利地模拟推理,更能真正地进行逻辑思考,从而在日益复杂的真实世界场景中发挥其应有的价值,而非仅是提供“流利的海市蜃楼”。这一挑战不仅关乎技术,更关乎AI的可靠性与未来的发展方向。


