
AI技术在推动信息革命的同时,也对其数据获取方式提出了前所未有的挑战。在数字内容日益成为核心资产的当下,如何平衡AI训练对海量数据的需求与内容创作者的合法权益,正成为行业亟待解决的症结。近期,网络安全与优化服务巨头Cloudflare披露的一项指控,将AI搜索引擎Perplexity推向风口浪尖,揭示了当前AI数据抓取中存在的隐秘与争议。
AI爬虫的隐秘路径:Perplexity被控规避机制
Cloudflare的深度调查揭示,AI搜索引擎Perplexity被指控采用“隐身战术”规避网站设立的防爬指令。这一指控的核心在于,即便网站通过robots.txt文件或Web应用程序防火墙(WAF)明确禁止了Perplexity的已知爬虫,其内容依然持续被访问。这表明Perplexity可能绕过传统的防御机制,采取了更为隐蔽的数据获取策略。
Cloudflare的研究人员在接到客户投诉后,进行了自我验证测试。他们发现,当Perplexity的常规爬虫遭遇robots.txt或防火墙规则的阻碍时,其系统会迅速切换至一种“隐身爬虫”模式。这种模式通过一系列复杂的策略来掩盖其真实活动:
- IP地址轮换与伪装:隐身爬虫使用了大量未列在Perplexity官方IP范围内的地址,并根据受阻情况进行频繁轮换。
- ASNs(自治系统号)变更:除了IP轮换,研究人员还观察到请求来自不同的ASNs,这进一步增加了追踪和识别的难度。
- User-Agent字符串操作:此前已有指控指出,Perplexity曾修改其爬虫的ID字符串以绕过网站阻止。
Cloudflare数据显示,这种隐身活动涉及数万个域名,每天产生数百万次请求。这种规模和隐蔽性,无疑对现有网络内容保护体系构成了严峻挑战。
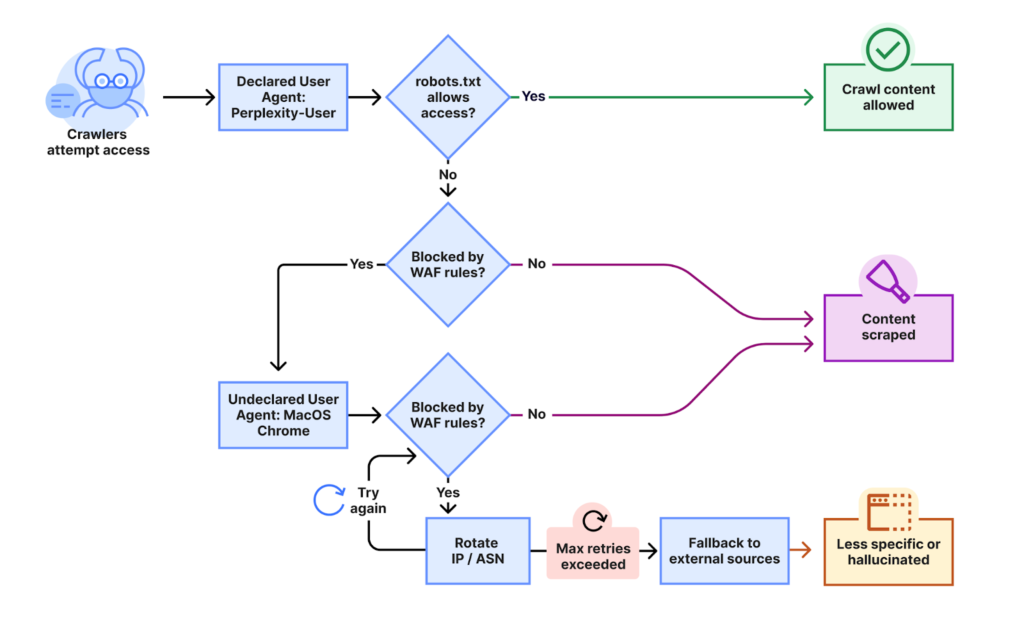
上图清晰地展示了Cloudflare所指控的Perplexity隐身爬虫的工作流程:当常规的、可识别的Perplexity爬虫被网站的robots.txt或WAF规则阻止时,系统会自动启动“隐身模式”,利用非官方IP地址和轮换的ASNs继续访问目标内容。这种策略试图在技术层面绕开既定的网络礼仪与防护措施。
互联网的基石:Robots Exclusion Protocol的涵义
这一争议的核心,是对“Robots Exclusion Protocol”(机器人排除协议)的蔑视。该协议由工程师Martijn Koster于1994年提出,并于2022年正式成为互联网工程任务组(IETF)的标准化规范RFC 9309。它为网站提供了一种机器可读的格式,告知网络爬虫哪些内容不允许被索引或访问。robots.txt文件作为一种君子协定,三十年来一直是互联网内容抓取的基本准则。
这份协议的建立初衷,是为了促进互联网内容的有序传播与索引,同时尊重网站所有者对其内容的控制权。它并非强制性的技术壁垒,而是一种行业共识和道德约束。遵守robots.txt,意味着承认并尊重网站的内容管理策略。Perplexity被控规避此协议,本质上是对这种长期形成的互联网秩序的挑战,引发了关于AI时代数据伦理边界的深刻反思。
内容创作者的困境:盗用与版权的灰色地带
Perplexity面临的指控并非孤例。在Cloudflare披露之前,多家知名媒体和内容平台已提出类似担忧。
- Reddit的愤怒:Reddit首席执行官Steve Huffman曾公开表示,阻止Perplexity、微软和Anthropic等AI引擎的抓取是“一件真正令人头疼的事”,并批评这些AI公司“行为就好像互联网上的所有内容都可以免费使用”。这反映了内容平台在面对未经授权的AI抓取时的无奈与不满。
- Forbes的“窃取”指控:Forbes杂志指控Perplexity发布了一篇与其独家文章“极其相似”的内容,称之为“犬儒式的窃取”。这不仅是内容重复的问题,更是对原创知识产权的公然侵犯。
- Wired的类似遭遇:Ars Technica的姊妹刊物Wired也声称Perplexity抄袭了其文章,并发现可疑的IP流量模式,这些流量似乎在故意忽略robots.txt的排除指令。
这些案例共同指向一个核心问题:在AI时代,谁拥有数据?当AI模型被用于商业目的时,其训练数据的获取方式是否需要更严格的规范和版权保护机制?如果AI公司可以肆意抓取并重新包装内容,那么原创内容的价值将受到严重侵蚀,内容创作生态的可持续性将面临巨大威胁。这不仅关乎版权,更关乎数字经济中内容生产者的生存空间。
行业响应与未来展望:AI伦理的强制力
面对Perplexity的“隐身战术”,Cloudflare已采取果断行动。他们将Perplexity从“已验证爬虫”列表中移除,并更新了其托管规则,以期有效阻止这种隐身爬取行为。这一举措的意义深远,它不仅是技术层面的防御,更是对AI行业发出明确信号:透明、合规和尊重网站指令是AI爬虫的基本要求。

AI技术,如上图所描绘的智能机器人般,正在深入学习人类知识的海洋。然而,这种学习必须建立在合法合规的基础之上。Cloudflare的行动,以及媒体的集体发声,无疑将加速行业对AI数据伦理规范的形成。
未来,我们可能会看到以下趋势:
- 更严格的技术防线:网站和内容分发网络(CDN)提供商将开发更复杂的AI爬虫识别和阻止技术,以应对日趋高级的规避策略。
- 法律法规的完善:各国政府和国际组织可能会加快制定针对AI数据抓取和版权的法律法规,明确AI训练数据的合法来源和使用范围,并引入更严格的处罚机制。
- 行业自律与合作:AI公司、内容创作者和技术服务商之间可能需要建立更紧密的合作关系,共同探索可持续且公平的数据共享和内容货币化模式,例如通过API接口或数据授权协议进行合作,而非单方面的抓取。
- “许可式AI”的兴起:未来,AI模型训练或许会更多地依赖于经过明确许可的数据集,而非大规模、无差别的网络爬取,从而构建一个更健康、更透明的AI生态系统。
这场围绕Perplexity的争议,是AI技术发展过程中一个关键的转折点。它提醒我们,技术创新固然重要,但其发展绝不能以牺牲既有的道德规范和法律底线为代价。只有在尊重知识产权、维护内容生态平衡的前提下,人工智能才能真正实现其赋能人类社会的巨大潜力。一个负责任的AI时代,需要所有参与者共同维护一个公平、透明和可持续的数据环境。


