
AI技术正以前所未有的速度渗透并重塑着我们生活的方方面面。从复杂的图像处理到日常的电商购物,再到前沿的多模态内容生成,一系列激动人心的创新正在全球范围内涌现。这些进展不仅展现了人工智能的强大潜力,也预示着一个更加智能、高效且富有创造力的未来。
图像与内容创作的革新浪潮
阿里Qwen-Image-Edit:中文图像编辑的新标杆
阿里巴巴通义千问团队推出的Qwen-Image-Edit图像编辑模型,标志着中文图像编辑领域的一大突破。这款模型凭借其卓越的文本编辑能力,特别是在中文渲染方面,其表现甚至超越了部分国际领先模型。其核心优势在于独特的双重编码机制,这一机制巧妙地平衡了语义理解与视觉外观的统一性,确保了编辑的准确性和图像的自然度。这意味着用户可以通过简单的中文指令,实现对图像内容的精准修改,无论是替换特定物体,还是调整风格细节,都能得到高质量的视觉反馈。Qwen-Image-Edit的开源,无疑将极大地赋能全球AI创作生态,降低技术门槛,推动个性化图像内容生成的普及与深化。

小红书DynamicFace:人脸融合技术的未来
小红书AIGC团队发布的DynamicFace可控人脸生成技术,聚焦于图像和视频领域的人脸融合任务。这项技术的核心在于其高可控性和高质量的融合效果,它能够实现高度一致性的人脸置换,即便在动态视频中也能保持自然流畅。DynamicFace的出现,不仅为娱乐社交平台带来了全新的互动体验,例如虚拟试妆、角色扮演等,更在影视制作、虚拟数字人创建等专业领域展现出巨大的应用价值。然而,随之而来的伦理和安全挑战,例如深度伪造(deepfake)的潜在风险,也需要业界在技术发展的同时,同步探索有效的监管和防御机制。
Grok Imagine 0.1:马斯克的“想象力放大器”
埃隆·马斯克旗下的xAI公司发布了其图像生成功能Grok Imagine的0.1测试版,并将其定位为“宇宙最强想象力放大器”。尽管仍处于早期阶段,马斯克对其寄予厚望,旨在与DALL-E、Midjourney等成熟的AI图像生成工具展开竞争。Grok Imagine的愿景在于不仅生成图像,更在于激发和拓展用户的创意思维,将抽象的想象具象化。这种强调“想象力”而非单纯“生成”的定位,或将为AI图像创作领域带来新的视角和交互模式。未来的发展值得持续关注,尤其是在其如何平衡技术生成与人类创造力融合的挑战。

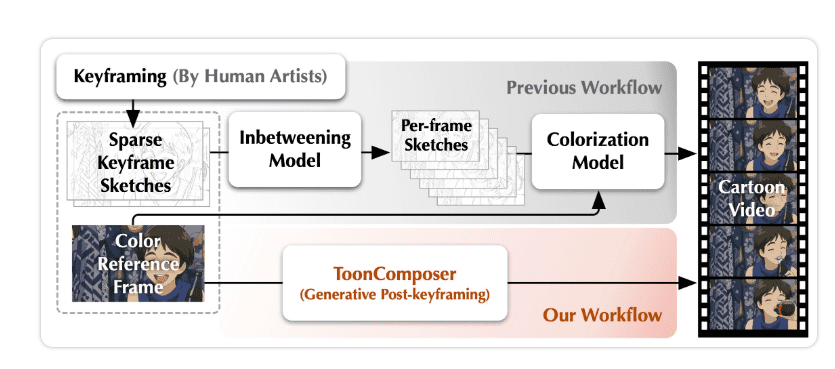
ToonComposer:AI赋能动漫制作流程
动画制作历来是一项耗时耗力的工作,而ToonComposer的出现,正彻底改变这一现状。这款基于生成式AI的创新工具,能够显著简化动画制作流程。用户只需提供一张草图和一帧彩色图像,ToonComposer便能智能生成完整的卡通视频。据统计,该技术有望节省高达70%的人工工作时间,让动画师能将更多精力投入到创意构思而非繁琐的重复劳动中。它所提供的关键帧控制和区域控制功能,进一步提升了创作的灵活性和效率,预示着AI在创意产业中扮演越来越重要的辅助角色。
商业模式与开发效率的飞跃
淘宝“AI万能搜”:重塑电商购物体验
淘宝正在灰度测试的“AI万能搜”功能,是电商领域利用大模型技术重构搜索体验的典范。该功能通过自然语言理解,为用户提供购物攻略、口碑评测和优惠咨询等一站式服务,并透明地展示AI的思考过程。这意味着消费者不再需要大海捞针般地浏览商品,而是可以通过对话式交互,获得更精准、个性化的购物建议。从穿搭指南到送礼清单,从选购攻略到口碑查询,“AI万能搜”旨在提升用户购物决策效率,从而彻底改变传统的电商购物模式,推动电商平台向更智能、更人性化的方向发展。

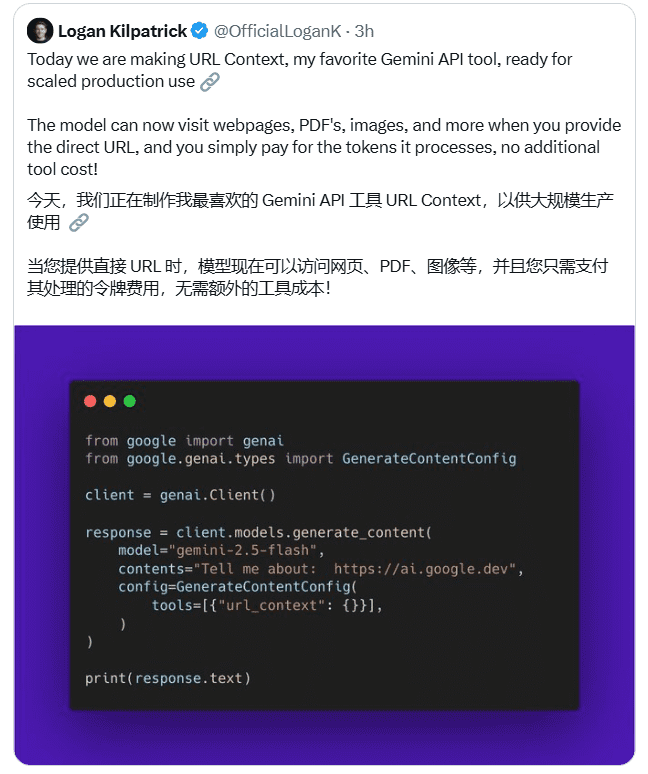
Gemini API URL Context:内容变现新机遇
Google Gemini API推出的URL Context功能,为开发者和内容提供商带来了前所未有的商业机遇。这项功能允许开发者直接在API请求中嵌入网页链接,模型能够自动访问并解析链接内容,从而极大地简化了内容获取流程。对于内容提供商而言,这可能催生出一种类似于AdSense的联盟机制,即通过提供高质量的内容,从模型处理这些内容所产生的Tokens费用中获得分成。这不仅提升了开发效率,也为内容创作的价值评估和商业化探索提供了新的思路,有望激励更多高质量原创内容的产出。
Vercel v0 iOS版:AI驱动的移动开发新纪元
Vercel推出的AI驱动开发工具v0的iOS版本,正在开创移动开发的新篇章。该工具允许开发者通过自然语言提示,快速生成全栈Web应用,极大地提升了开发效率。其在React和Next.js框架中的出色表现,已经赢得了广泛认可。v0 iOS版的发布,意味着移动开发者现在可以利用AI的强大能力,以前所未有的速度和便捷性构建应用。这不仅降低了移动开发的门槛,也将加速创新应用的迭代周期,为移动生态系统注入新的活力。这种“所思即所得”的开发模式,是软件工程领域一次深刻的变革。

模型的效率与应用的深化
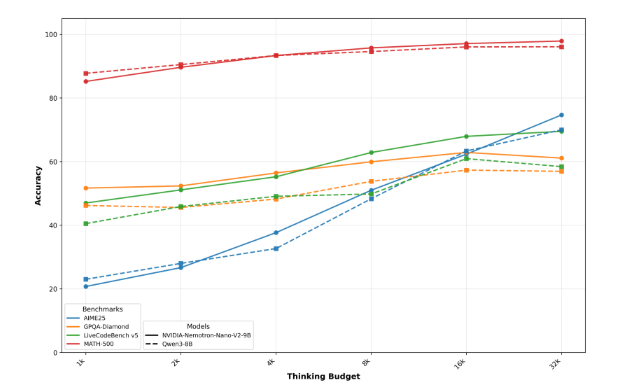
Nvidia Nemotron-Nano-9B-v2:小型开放模型的强大潜力
Nvidia发布的新型小型语言模型Nemotron-Nano-9B-v2,以其90亿参数的精巧体量,在多个基准测试中展现出卓越性能。这款模型尤其优化于单个Nvidia A10 GPU,其混合架构使其能够高效处理长序列信息,并支持用户灵活控制推理功能,这对于需要部署在边缘设备或资源受限环境下的应用至关重要。作为开放模型,Nemotron-Nano-9B-v2允许商业用途和衍生模型的创建,这对于推动多语言任务、代码生成以及其他垂直领域的AI应用具有重要意义,标志着小型、高效且功能强大的AI模型正成为行业新趋势。
理想汽车MindGPT 3.1:智能体模型在汽车领域的突破
理想汽车发布的MindGPT 3.1智能体模型,展现了AI大模型在特定行业应用中的深度融合与优化。这款模型显著提升了AI助手的实时处理和多任务协调能力,其每秒输出速度最高可达200个tokens,性能提升近5倍。更重要的是,MindGPT 3.1将智能体能力深度融入大模型架构,实现了“边想边搜”的先进功能。在数学计算和代码编程等关键维度,其表现全面超越前代版本,甚至可以实现贪吃蛇游戏、弹球控制等经典编程案例。这不仅提升了车载AI的智能化水平,也为汽车行业在人机交互、智能驾驶辅助等方面提供了更广阔的想象空间。
ElevenLabs:视频到音乐生成的新流程
ElevenLabs在AI音频领域持续深耕,推出了视频到音乐生成流程和AI学生包。这项视频到音乐生成技术,能够基于视频内容自动创作定制化的配乐,极大地简化了内容创作者的工作流程,提高了后期制作的效率。同时,AI学生包则通过提供免费积分和折扣工具,支持教育领域的应用,降低了学生和学术研究人员使用前沿AI音频技术的门槛。这些更新进一步巩固了ElevenLabs在多模态AI领域的领先地位,预示着未来内容创作将更加趋向于自动化、个性化和跨模态融合。








