
大型语言模型(LLMs)的“模拟推理”能力,是人工智能领域当前备受关注的核心议题。随着AI技术飞速发展,特别是链式思考(Chain-of-Thought, CoT)方法的引入,我们见证了LLMs在处理复杂问题时展现出多步骤逻辑分析的潜力。然而,近期来自亚利桑那州立大学的研究团队,通过一系列严谨的实验,为这一乐观前景蒙上了一层审慎的阴影,指出LLMs的“模拟推理”可能仅仅是一种“脆性幻象”。这项研究深入剖析了CoT模型在泛化能力上的根本性缺陷,强调了其在“域外”逻辑问题面前的脆弱性。
CoT推理的本质:模式复制而非抽象理解
研究人员指出,当前大型语言模型的推理能力,更多地表现为对训练数据中模式的复杂复制,而非真正意义上的抽象逻辑理解。这并非贬低LLMs在自然语言处理上的巨大成就,而是对其深层认知能力的边界进行了精准界定。当模型面临与其训练数据中特定逻辑模式不完全匹配的问题时,其性能会迅速且显著地下降。这种现象被称为“脆性幻象”,意味着模型表面上的强大推理能力,在遇到轻微的分布偏移时便会土崩瓦解。这使得我们必须重新审视,我们所观察到的“智能”究竟是何种形式。
LLMs在多步骤推理中展现出的连贯性,常常给人一种它们正在“思考”的错觉。然而,一旦问题情境超出了其严格定义的训练范畴,或者引入了不相关的干扰信息,模型便容易产生逻辑不连贯甚至荒谬的答案。这种“流畅的废话”(fluent nonsense)的生成能力,尤其令人警惕,因为它可能赋予模型一种虚假的可靠性光环,尤其是在非专业人士看来,其输出的流畅性容易掩盖深层的逻辑错误。
 *图1:机器人在解决复杂难题时,其内部运作机制往往是理解其真实能力的钥匙。
*图1:机器人在解决复杂难题时,其内部运作机制往往是理解其真实能力的钥匙。
DataAlchemy实验框架:揭示泛化之殇
为了系统性地评估LLMs的泛化推理能力,研究团队构建了一个名为DataAlchemy的受控LLM训练环境。该环境专注于训练小型模型来执行两种极简的文本转换操作:ROT密码和循环移位。随后,通过组合这些基本操作,对模型进行额外的训练。这种实验设计巧妙地避免了大型模型和复杂任务带来的不确定性,使得研究人员能够精确地控制模型的训练输入和测试条件。
研究的核心在于设计了多种测试任务,其中一部分与训练数据中的功能模式精确匹配或高度相似,而另一些则需要模型执行“域外”的功能组合。例如,一个模型可能被训练来执行两次循环移位,但随后被要求执行两次ROT移位,而它仅对单个ROT移位有过基本训练。通过这种方式,研究人员可以清晰地观察到,当模型被要求泛化到训练数据未直接演示的新颖转换集合时,其性能如何急剧下降。
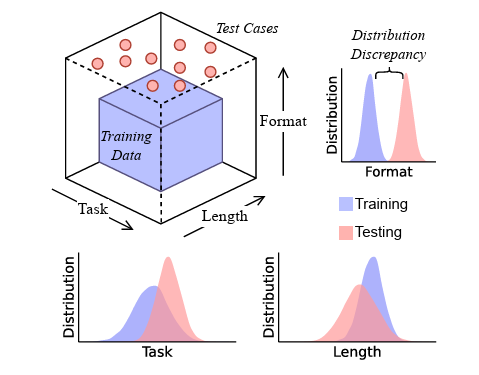 *图2:DataAlchemy实验流程示意图,展示了训练数据之外的任务类型、格式和长度如何影响LLM性能。
*图2:DataAlchemy实验流程示意图,展示了训练数据之外的任务类型、格式和长度如何影响LLM性能。
实验结果令人深思。当任务偏离训练分布时,即使模型尝试基于训练数据中的相似模式来泛化新的逻辑规则,也往往会导致“正确的推理路径,但错误的答案”。更有甚者,有时LLM会偶然得到正确的答案,但其背后的“推理路径”却是不忠实的,即不符合逻辑演进的。这再次印证了CoT推理的本质:它更倾向于复制和重现训练中习得的模式,而非进行独立的、抽象的逻辑推断。
分布偏移的影响:长度、格式与准确性
除了功能组合的“域外”性,研究还探究了输入文本字符串的长度以及功能链长度的变化对模型性能的影响。结果表明,当测试任务的输入文本字符串长度或所需功能链长度与训练数据存在差异时,模型的准确性会随差异的增大而显著恶化。这有力地揭示了模型泛化能力的局限性,即便是对看似微小的、不熟悉的格式差异(如训练数据中未出现的字母或符号),也可能导致模型性能的急剧下降。
这些发现揭示了一个核心问题:LLMs的当前“推理”能力与其说是一种普适性的认知能力,不如说是一种高度敏感的“结构化模式匹配”机制。这种机制对输入数据的分布特征极为敏感,一旦超出其熟知的边界,便难以维持其表面上的高水平表现。这种敏感性在实际应用中构成了巨大的挑战,因为真实世界的问题往往充满变数,很少能完美地复刻训练数据的分布。
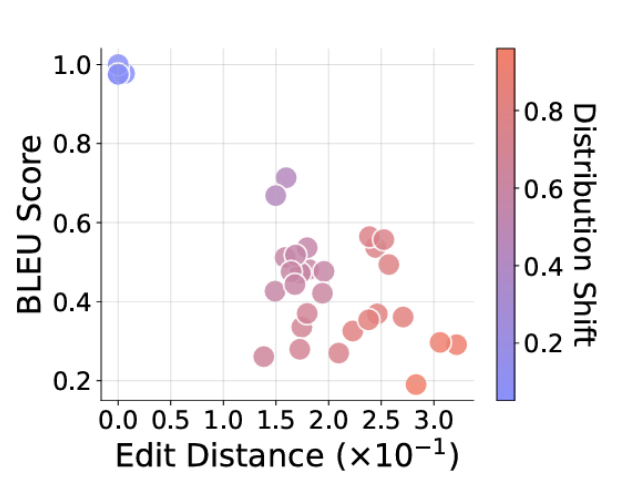 *图3:随着请求任务偏离训练分布(红色点越深),模型提供的答案与期望答案的距离也越远(图的右下角)。
*图3:随着请求任务偏离训练分布(红色点越深),模型提供的答案与期望答案的距离也越远(图的右下角)。
超越表面修补:通往真正泛化的路径
在面对这种“域外”失败时,通常的应对策略是采用监督式微调(Supervised Fine-Tuning, SFT)——即向训练集中引入少量相关数据以“修复”模型在该特定任务上的表现。然而,研究人员对此类“修补”方法提出了严正警告。他们认为,依赖SFT来解决每一个“域外”失败,是一种不可持续且被动的策略,它未能触及问题的核心:模型缺乏抽象推理能力。
真正的泛化能力,意味着模型能够在未见过的、甚至在结构上有所不同的问题上,应用其从现有知识中提炼出的抽象原则。而当前CoT模型所展现的,更多是其识别和复现训练数据中结构化模式的娴熟技巧。因此,将CoT风格的输出等同于人类思维,尤其是在医疗、金融或法律分析等高风险领域,是极其危险的。在这些领域,任何看似微小的逻辑偏差都可能导致灾难性的后果。
展望未来:重新定义AI推理的基准
这项研究为人工智能领域敲响了警钟,促使我们重新思考如何评估和发展LLMs的推理能力。未来的模型需要超越单纯的“表层模式识别”,向“更深层次的推断能力”迈进。这意味着,我们需要开发新的测试和基准,专门用于探测模型在“域外”任务上的表现,而不是仅仅衡量其在与训练数据高度相似任务上的性能。
此外,我们必须认识到,当前LLMs的强大语言生成能力与潜在的逻辑缺陷之间的矛盾。如何设计能够进行自我纠错、自我反思,并能明确表达其推理局限性的AI系统,将是未来研究的关键方向。这不仅关乎技术进步,更关乎在AI日益融入社会各个层面的背景下,构建一个安全、可靠、负责任的人工智能生态系统。AI的未来,在于能否从“模拟”走向“理解”,从“模式复制”走向“抽象创造”。








