
近年来,人工智能在语音领域的进步可谓一日千里,而端到端语音大模型正成为这一变革的核心驱动力。在这一背景下,阶跃星辰正式发布了其最新力作——Step-Audio2mini,一个被寄予厚望的开源端到端语音大模型。该模型的推出,不仅在技术层面实现了多项突破,更在实际应用中展现了其“听得清楚、想得明白、说得自然”的卓越能力,预示着智能语音交互新时代的到来。
Step-Audio2mini的核心亮点在于其端到端的集成能力,它打破了传统语音处理中语音识别(ASR)、语言模型(LLM)和语音合成(TTS)各自独立、串联工作的范式。这种真端到端的多模态架构,实现了从原始音频输入到最终语音响应输出的直接转换,极大地简化了系统复杂性,显著降低了处理时延。更重要的是,这种架构赋予了模型更强的全局感知能力,使其能够有效理解并处理传统模型难以触及的副语言信息与非人声信号,为更自然、更富有情感的交互奠定了基础。
模型的创新性不仅体现在架构上。Step-Audio2mini在端到端语音模型中首次引入了链式思维推理(CoT)与强化学习(RL)的联合优化机制。这意味着模型不再仅仅是机械地识别和生成语音,而是能够像人类一样,对情绪、语调、音乐等副语言信息进行更为精细的理解和推理,并在此基础上做出更加自然和恰当的回应。这种“走脑又走心”的设计理念,让AI的语音交互不再局限于信息传递,更能触及情感共鸣的层面,极大地提升了用户体验。
在衡量模型性能的国际基准测试中,Step-Audio2mini取得了令人瞩目的SOTA(State-of-the-Art)成绩,全面超越了包括Qwen-Omni、Kimi-Audio在内的所有开源端到端语音模型,并在诸多任务上超越了GPT-4o Audio。例如,在通用多模态音频理解测试集MMAU上,Step-Audio2mini以73.2的高分位列开源榜首,展现了其卓越的音频理解能力。在衡量口语对话能力的URO Bench上,无论是基础赛道还是专业赛道,它都斩获了开源端到端语音模型的最高分,印证了其在复杂对话场景下的出色表现。
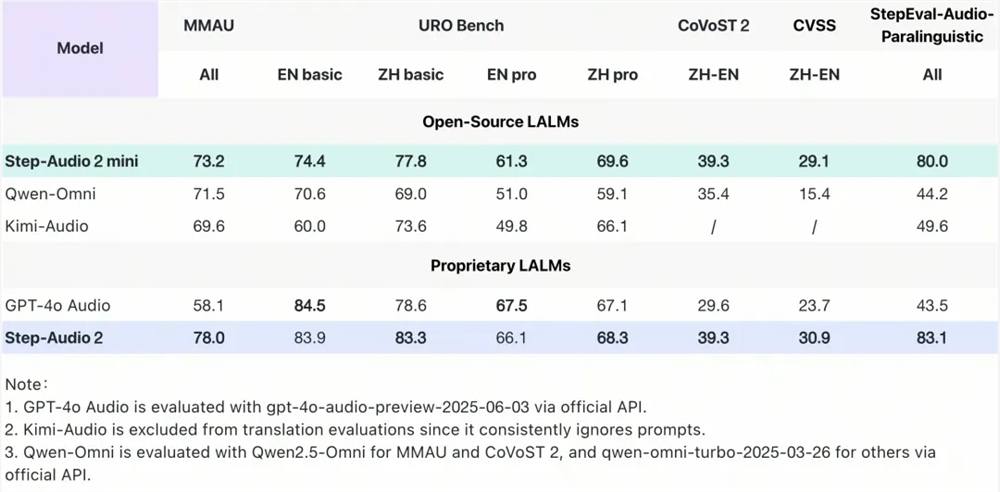
此外,在跨语种翻译任务上,Step-Audio2mini在中英互译方面表现尤为突出,在CoVoST2和CVSS评测集上分别取得39.3和29.1的分数,大幅领先包括GPT-4o Audio在内的其他模型。而在语音识别任务中,模型在多语言和多方言识别上均取得第一,其中开源中文测试集的平均字错误率(CER)仅为3.19,开源英语测试集的平均词错误率(WER)为3.50,领先其他开源模型超过15%。这些数据不仅是技术的量化证明,更意味着Step-Audio2mini在实际应用中能够提供更准确、更可靠的语音服务。
Step-Audio2mini的实用能力也得到了生动展示。它不仅能够精准识别大自然中的各种声音、精湛的配音艺术,还能通过其率先支持的语音原生Tool Calling能力,实现实时联网搜索,获取最新的行业资讯。这一能力对于解决大型语言模型普遍存在的“幻觉”问题至关重要,通过引入外部工具,模型能够获取实时准确的信息,从而给出更可靠的答案。同时,Tool Calling也极大地扩展了模型在多场景下的应用潜力,使其能够执行更广泛的任务。
模型的灵活度体现在其对语速的自如控制上,能够轻松适应不同场景的对话需求,无论是快节奏的信息交流还是舒缓的情感表达,都能游刃有余。更令人印象深刻的是,当面对抽象的哲学难题时,Step-Audio2mini能够将其转化为极简的方法论进行解析,这不仅展示了其强大的逻辑推理能力,也反映了其在处理复杂概念方面的深度理解。这些案例共同描绘了一个拥有高度智能、能适应多样化需求的未来语音助手。
阶跃星辰通过Step-Audio2mini的发布,无疑为整个AI语音技术领域树立了一个新的标杆。其开源的策略,将允许全球的开发者和研究者共同参与到模型的改进和应用创新中来,加速语音AI技术的普惠化进程。未来,我们可以预见到,Step-Audio2mini及其后续发展,将在智能家居、车载系统、在线教育、客户服务等诸多领域发挥关键作用,重新定义人机交互的边界,推动社会向更智能化、更便捷化的方向发展。这种开放与创新的精神,正是驱动人工智能不断前行的核心动力。








