
近年来,科技巨头们在人工智能领域投入巨资,竞相推出参数量日益庞大的AI模型,借助昂贵的GPU集群,将生成式AI作为云服务推向市场。然而,在追求极致性能的同时,我们不应忽视“微型”AI所蕴含的巨大价值。近期,Google发布了一款引人注目的Gemma开放模型——Gemma 3 270M。这款专为本地设备运行而设计的模型,其参数规模仅为其他新模型的极小一部分,却承诺在保持强大性能的同时,实现快速微调和极低的资源占用。
Gemma系列模型最早于今年早些时候推出,参数量从10亿到270亿不等。在生成式AI领域,参数是控制模型如何处理输入、估算输出的关键变量。通常情况下,参数越多,模型的性能越强。而Gemma 3 270M仅拥有2.7亿个参数,这意味着它能够直接在智能手机乃至完全在网页浏览器内部运行,这一特性无疑为AI技术的普及和应用带来了革命性的变革。
在本地设备上运行AI模型,其优势是多方面的。首先,它显著增强了用户隐私保护。由于数据处理和模型推理都在本地进行,敏感信息无需上传至云端服务器,大大降低了数据泄露的风险。其次,本地运行可以大幅降低延迟。指令处理和响应几乎是即时完成,无需依赖网络连接,这对于需要快速反馈的应用场景至关重要。Gemma 3 270M正是围绕这些本地用例进行精心设计的。
在对Pixel 9 Pro进行测试时,Gemma 3 270M展现出令人惊叹的效率。在搭载Tensor G4芯片的设备上,该模型能够顺畅运行25次对话,而电池消耗仅为0.75%。这使其成为迄今为止Gemma系列中能效最高的模型,为移动设备上的持续AI体验奠定了基础。
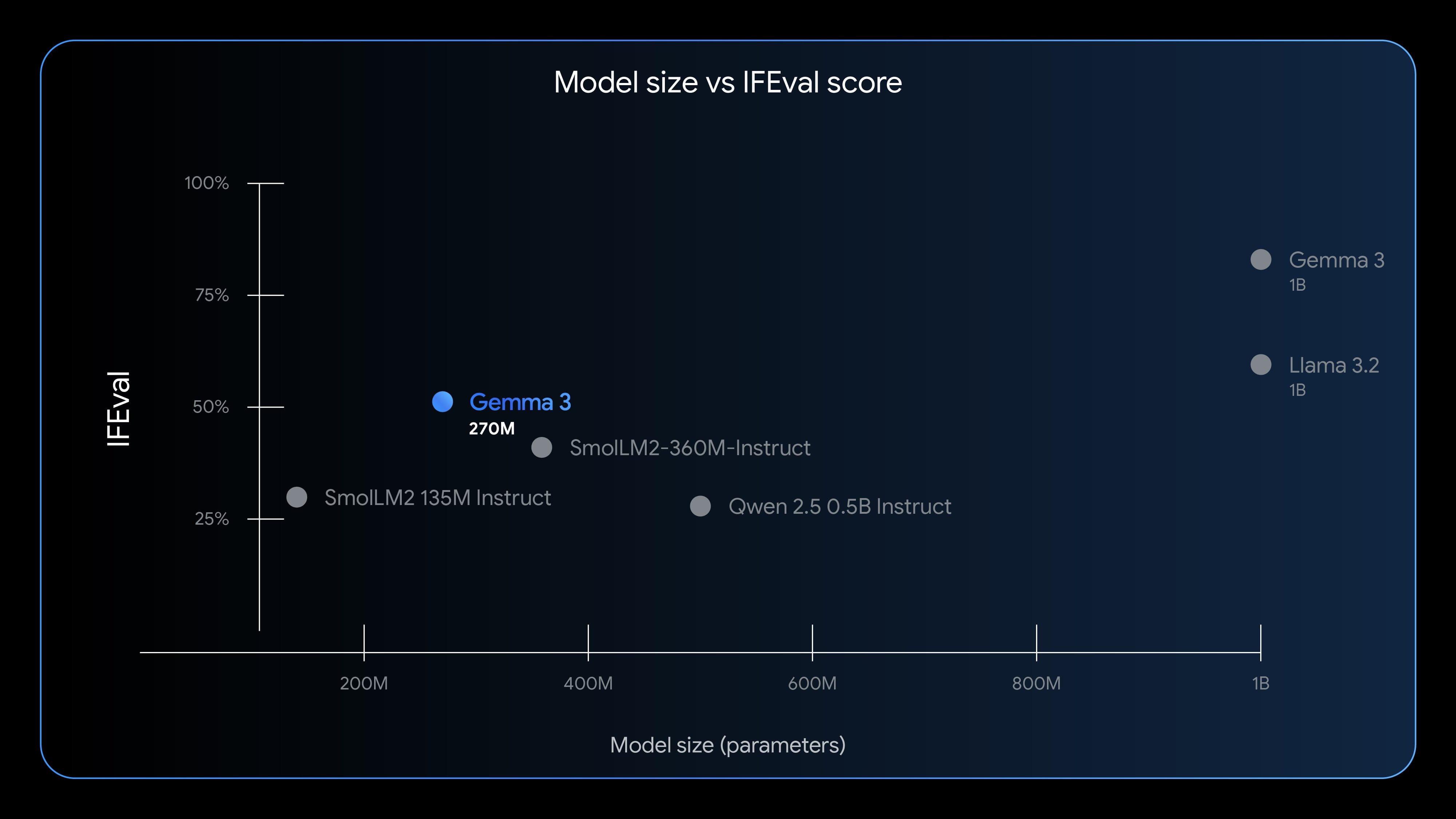
当然,开发者不应期望Gemma 3 270M能达到数十亿参数模型的同等性能水平,但它无疑拥有自己独特的应用价值。Google采用IFEval基准测试来评估模型遵循指令的能力,结果显示Gemma 3 270M表现出色。它在测试中获得了51.2%的分数,这一成绩高于许多参数更多的轻量级模型,充分证明了其“小身材大能量”的特点。虽然与Llama 3.2等十亿级以上模型相比仍有差距,但考虑到其参数规模,这种差距远比人们预期的要小,这表明Google在模型架构和优化方面取得了显著突破。
Google方面声称,Gemma 3 270M在开箱即用的情况下,就能很好地遵循指令。但其更大的潜力在于开发者可以根据特定用例进行快速微调。由于参数数量少,微调过程不仅速度快,成本也极低。Google认为,新的Gemma模型非常适合文本分类和数据分析等任务,这些任务可以在不依赖大量计算资源的情况下迅速完成,从而在资源受限的环境中实现高效的AI处理。
关于Gemma模型,Google将其定义为“开放”而非“开源”。尽管两者在许多方面相似,但在关键的许可条款上仍存在细微差异。开发者可以免费下载新的Gemma模型,并且模型的权重也已公开。重要的是,Gemma模型没有独立的商业许可协议,这意味着开发者可以自由地修改、发布和部署Gemma 3 270M的衍生版本,并将其集成到自己的工具中,极大地促进了生态系统的创新与发展。
然而,所有Gemma模型的使用者都必须遵守其使用条款。这些条款明确禁止对模型进行微调以生成有害内容,或故意违反隐私规定。此外,开发者有责任详细说明对模型的任何修改,并为所有衍生版本提供一份使用条款副本,这些衍生版本将继承Google的自定义许可证。这确保了在模型开放使用的同时,仍能维持一定的伦理和法律规范,引导AI技术向积极的方向发展。
Gemma 3 270M目前已在Hugging Face和Kaggle等主流平台上线,提供预训练版本和指令微调版本,以满足不同开发者的需求。同时,它也在Google的Vertex AI平台中提供测试环境,方便开发者进行实验和验证。Google还特别强调了这款新模型的潜力,展示了一个完全基于浏览器运行的文本故事生成器,该生成器正是基于Transformer.js构建。即使对开发不感兴趣的用户,也可以尝试体验这一创新的轻量级模型应用,感受本地AI带来的便捷与乐趣。
Gemma 3 270M的发布,标志着AI发展的一个重要里程碑。它不仅仅是一个参数更小的模型,更是对AI未来发展路径的一次深刻探索——即如何在保持强大的智能能力的同时,实现更广泛的部署、更低的资源消耗和更强的隐私保护。随着更多设备和应用开始集成这种微型AI,我们有理由相信,未来的智能世界将变得更加普惠、高效和个性化。








